 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIPPS: Knowledge infusion in Privacy Preserving Synthetic Data Generation
Sep 25, 2024



The integration of privacy measures, including differential privacy techniques, ensures a provable privacy guarantee for the synthetic data. However, challenges arise for Generative Deep Learning models when tasked with generating realistic data, especially in critical domains such as Cybersecurity and Healthcare. Generative Models optimized for continuous data struggle to model discrete and non-Gaussian features that have domain constraints. Challenges increase when the training datasets are limited and not diverse. In such cases, generative models create synthetic data that repeats sensitive features, which is a privacy risk. Moreover, generative models face difficulties comprehending attribute constraints in specialized domains. This leads to the generation of unrealistic data that impacts downstream accuracy. To address these issues, this paper proposes a novel model, KIPPS, that infuses Domain and Regulatory Knowledge from Knowledge Graphs into Generative Deep Learning models for enhanced Privacy Preserving Synthetic data generation. The novel framework augments the training of generative models with supplementary context about attribute values and enforces domain constraints during training. This added guidance enhances the model's capacity to generate realistic and domain-compliant synthetic data. The proposed model is evaluated on real-world datasets, specifically in the domains of Cybersecurity and Healthcare, where domain constraints and rules add to the complexity of the data. Our experiments evaluate the privacy resilience and downstream accuracy of the model against benchmark methods, demonstrating its effectiveness in addressing the balance between privacy preservation and data accuracy in complex domains.
KiNETGAN: Enabling Distributed Network Intrusion Detection through Knowledge-Infused Synthetic Data Generation
May 26, 2024


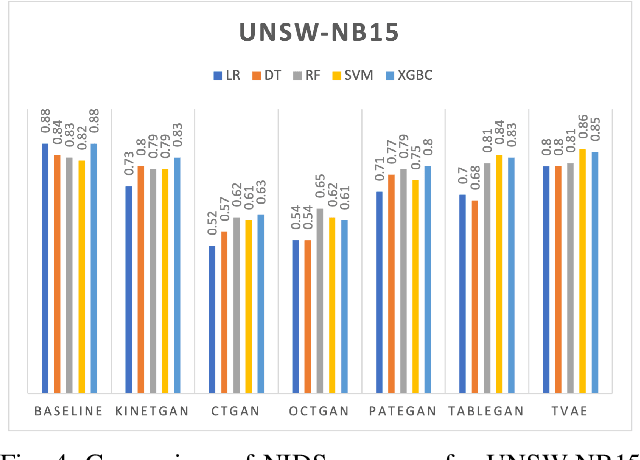
In the realm of IoT/CPS systems connected over mobile networks, traditional intrusion detection methods analyze network traffic across multiple devices using anomaly detection techniques to flag potential security threats. However, these methods face significant privacy challenges, particularly with deep packet inspection and network communication analysis. This type of monitoring is highly intrusive, as it involves examining the content of data packets, which can include personal and sensitive information. Such data scrutiny is often governed by stringent laws and regulations, especially in environments like smart homes where data privacy is paramount. Synthetic data offers a promising solution by mimicking real network behavior without revealing sensitive details. Generative models such as Generative Adversarial Networks (GANs) can produce synthetic data, but they often struggle to generate realistic data in specialized domains like network activity. This limitation stems from insufficient training data, which impedes the model's ability to grasp the domain's rules and constraints adequately. Moreover, the scarcity of training data exacerbates the problem of class imbalance in intrusion detection methods. To address these challenges, we propose a Privacy-Driven framework that utilizes a knowledge-infused Generative Adversarial Network for generating synthetic network activity data (KiNETGAN). This approach enhances the resilience of distributed intrusion detection while addressing privacy concerns. Our Knowledge Guided GAN produces realistic representations of network activity, validated through rigorous experimentation. We demonstrate that KiNETGAN maintains minimal accuracy loss in downstream tasks, effectively balancing data privacy and utility.
PrivComp-KG : Leveraging Knowledge Graph and Large Language Models for Privacy Policy Compliance Verification
Apr 30, 2024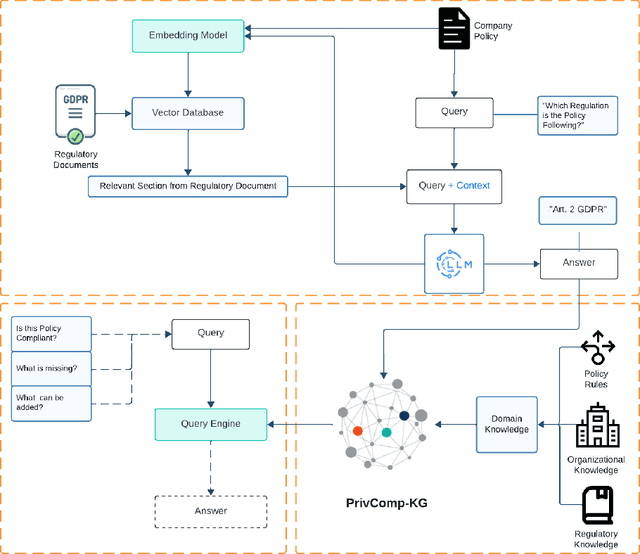
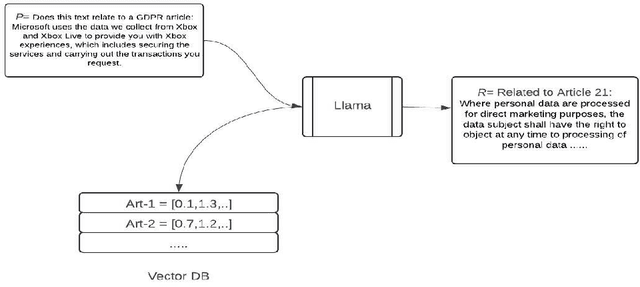
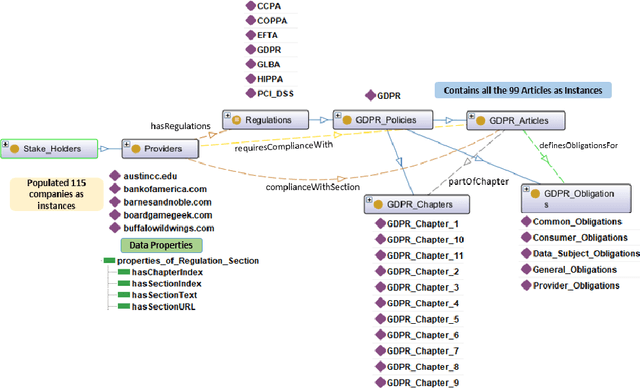
Data protection and privacy is becoming increasingly crucial in the digital era. Numerous companies depend on third-party vendors and service providers to carry out critical functions within their operations, encompassing tasks such as data handling and storage. However, this reliance introduces potential vulnerabilities, as these vendors' security measures and practices may not always align with the standards expected by regulatory bodies. Businesses are required, often under the penalty of law, to ensure compliance with the evolving regulatory rules. Interpreting and implementing these regulations pose challenges due to their complexity. Regulatory documents are extensive, demanding significant effort for interpretation, while vendor-drafted privacy policies often lack the detail required for full legal compliance, leading to ambiguity. To ensure a concise interpretation of the regulatory requirements and compliance of organizational privacy policy with said regulations, we propose a Large Language Model (LLM) and Semantic Web based approach for privacy compliance. In this paper, we develop the novel Privacy Policy Compliance Verification Knowledge Graph, PrivComp-KG. It is designed to efficiently store and retrieve comprehensive information concerning privacy policies, regulatory frameworks, and domain-specific knowledge pertaining to the legal landscape of privacy. Using Retrieval Augmented Generation, we identify the relevant sections in a privacy policy with corresponding regulatory rules. This information about individual privacy policies is populated into the PrivComp-KG. Combining this with the domain context and rules, the PrivComp-KG can be queried to check for compliance with privacy policies by each vendor against relevant policy regulations. We demonstrate the relevance of the PrivComp-KG, by verifying compliance of privacy policy documents for various organizations.
Privacy-Preserving Data Sharing in Agriculture: Enforcing Policy Rules for Secure and Confidential Data Synthesis
Nov 27, 2023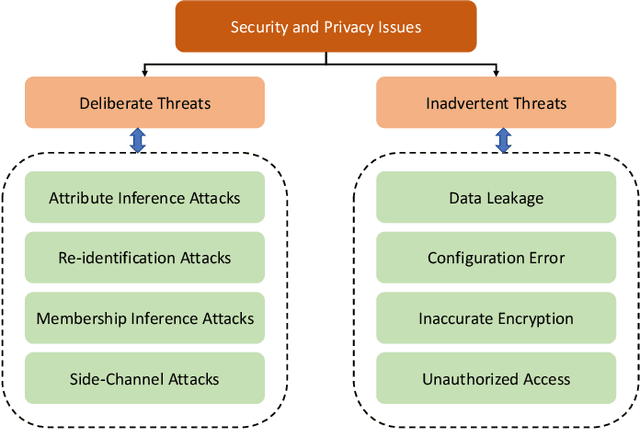
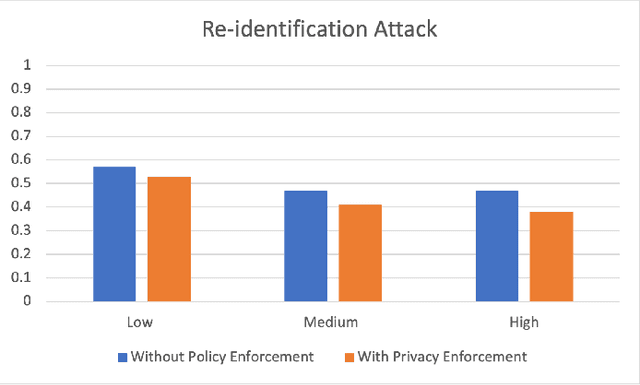
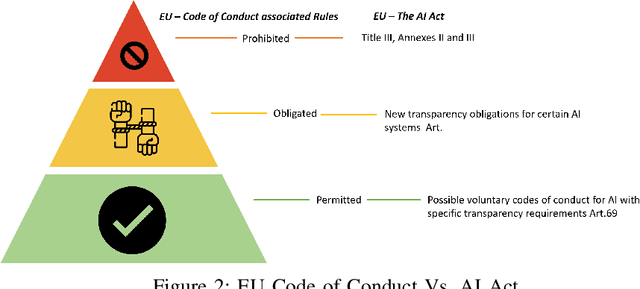
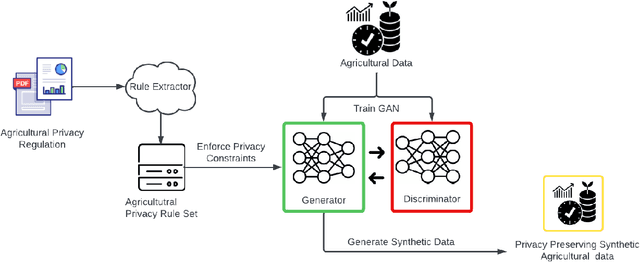
Big Data empowers the farming community with the information needed to optimize resource usage, increase productivity, and enhance the sustainability of agricultural practices. The use of Big Data in farming requires the collection and analysis of data from various sources such as sensors, satellites, and farmer surveys. While Big Data can provide the farming community with valuable insights and improve efficiency, there is significant concern regarding the security of this data as well as the privacy of the participants. Privacy regulations, such as the EU GDPR, the EU Code of Conduct on agricultural data sharing by contractual agreement, and the proposed EU AI law, have been created to address the issue of data privacy and provide specific guidelines on when and how data can be shared between organizations. To make confidential agricultural data widely available for Big Data analysis without violating the privacy of the data subjects, we consider privacy-preserving methods of data sharing in agriculture. Deep learning-based synthetic data generation has been proposed for privacy-preserving data sharing. However, there is a lack of compliance with documented data privacy policies in such privacy-preserving efforts. In this study, we propose a novel framework for enforcing privacy policy rules in privacy-preserving data generation algorithms. We explore several available agricultural codes of conduct, extract knowledge related to the privacy constraints in data, and use the extracted knowledge to define privacy bounds in a privacy-preserving generative model. We use our framework to generate synthetic agricultural data and present experimental results that demonstrate the utility of the synthetic dataset in downstream tasks. We also show that our framework can evade potential threats and secure data based on applicable regulatory policy rules.
FABULA: Intelligence Report Generation Using Retrieval-Augmented Narrative Construction
Oct 20, 2023
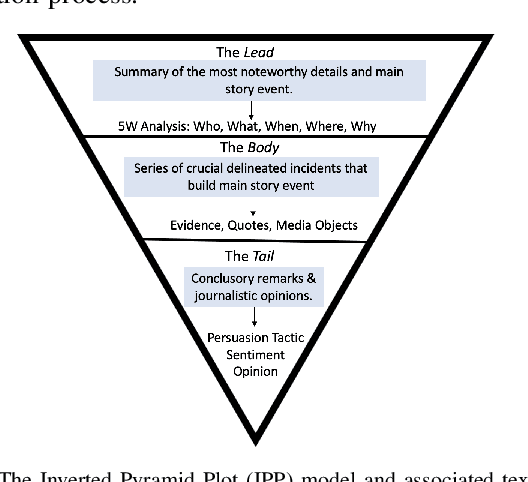


Narrative construction is the process of representing disparate event information into a logical plot structure that models an end to end story. Intelligence analysis is an example of a domain that can benefit tremendously from narrative construction techniques, particularly in aiding analysts during the largely manual and costly process of synthesizing event information into comprehensive intelligence reports. Manual intelligence report generation is often prone to challenges such as integrating dynamic event information, writing fine-grained queries, and closing information gaps. This motivates the development of a system that retrieves and represents critical aspects of events in a form that aids in automatic generation of intelligence reports. We introduce a Retrieval Augmented Generation (RAG) approach to augment prompting of an autoregressive decoder by retrieving structured information asserted in a knowledge graph to generate targeted information based on a narrative plot model. We apply our approach to the problem of neural intelligence report generation and introduce FABULA, framework to augment intelligence analysis workflows using RAG. An analyst can use FABULA to query an Event Plot Graph (EPG) to retrieve relevant event plot points, which can be used to augment prompting of a Large Language Model (LLM) during intelligence report generation. Our evaluation studies show that the plot points included in the generated intelligence reports have high semantic relevance, high coherency, and low data redundancy.
Change Management using Generative Modeling on Digital Twins
Sep 21, 2023A key challenge faced by small and medium-sized business entities is securely managing software updates and changes. Specifically, with rapidly evolving cybersecurity threats, changes/updates/patches to software systems are necessary to stay ahead of emerging threats and are often mandated by regulators or statutory authorities to counter these. However, security patches/updates require stress testing before they can be released in the production system. Stress testing in production environments is risky and poses security threats. Large businesses usually have a non-production environment where such changes can be made and tested before being released into production. Smaller businesses do not have such facilities. In this work, we show how "digital twins", especially for a mix of IT and IoT environments, can be created on the cloud. These digital twins act as a non-production environment where changes can be applied, and the system can be securely tested before patch release. Additionally, the non-production digital twin can be used to collect system data and run stress tests on the environment, both manually and automatically. In this paper, we show how using a small sample of real data/interactions, Generative Artificial Intelligence (AI) models can be used to generate testing scenarios to check for points of failure.
Knowledge-enhanced Neuro-Symbolic AI for Cybersecurity and Privacy
Jul 25, 2023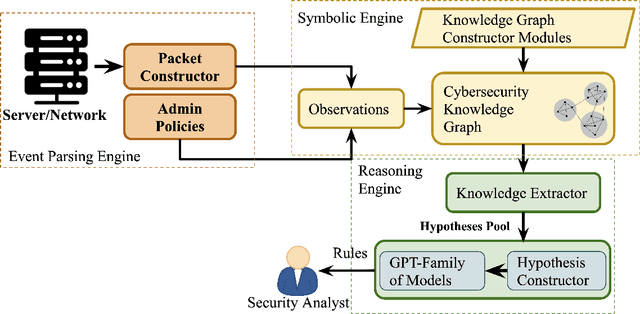
Neuro-Symbolic Artificial Intelligence (AI) is an emerging and quickly advancing field that combines the subsymbolic strengths of (deep) neural networks and explicit, symbolic knowledge contained in knowledge graphs to enhance explainability and safety in AI systems. This approach addresses a key criticism of current generation systems, namely their inability to generate human-understandable explanations for their outcomes and ensure safe behaviors, especially in scenarios with \textit{unknown unknowns} (e.g. cybersecurity, privacy). The integration of neural networks, which excel at exploring complex data spaces, and symbolic knowledge graphs, which represent domain knowledge, allows AI systems to reason, learn, and generalize in a manner understandable to experts. This article describes how applications in cybersecurity and privacy, two most demanding domains in terms of the need for AI to be explainable while being highly accurate in complex environments, can benefit from Neuro-Symbolic AI.
A Practical Entity Linking System for Tables in Scientific Literature
Jun 12, 2023



Entity linking is an important step towards constructing knowledge graphs that facilitate advanced question answering over scientific documents, including the retrieval of relevant information included in tables within these documents. This paper introduces a general-purpose system for linking entities to items in the Wikidata knowledge base. It describes how we adapt this system for linking domain-specific entities, especially for those entities embedded within tables drawn from COVID-19-related scientific literature. We describe the setup of an efficient offline instance of the system that enables our entity-linking approach to be more feasible in practice. As part of a broader approach to infer the semantic meaning of scientific tables, we leverage the structural and semantic characteristics of the tables to improve overall entity linking performance.
CAPD: A Context-Aware, Policy-Driven Framework for Secure and Resilient IoBT Operations
Aug 02, 2022The Internet of Battlefield Things (IoBT) will advance the operational effectiveness of infantry units. However, this requires autonomous assets such as sensors, drones, combat equipment, and uncrewed vehicles to collaborate, securely share information, and be resilient to adversary attacks in contested multi-domain operations. CAPD addresses this problem by providing a context-aware, policy-driven framework supporting data and knowledge exchange among autonomous entities in a battlespace. We propose an IoBT ontology that facilitates controlled information sharing to enable semantic interoperability between systems. Its key contributions include providing a knowledge graph with a shared semantic schema, integration with background knowledge, efficient mechanisms for enforcing data consistency and drawing inferences, and supporting attribute-based access control. The sensors in the IoBT provide data that create populated knowledge graphs based on the ontology. This paper describes using CAPD to detect and mitigate adversary actions. CAPD enables situational awareness using reasoning over the sensed data and SPARQL queries. For example, adversaries can cause sensor failure or hijacking and disrupt the tactical networks to degrade video surveillance. In such instances, CAPD uses an ontology-based reasoner to see how alternative approaches can still support the mission. Depending on bandwidth availability, the reasoner initiates the creation of a reduced frame rate grayscale video by active transcoding or transmits only still images. This ability to reason over the mission sensed environment and attack context permits the autonomous IoBT system to exhibit resilience in contested conditions.
Recognizing and Extracting Cybersecurtity-relevant Entities from Text
Aug 02, 2022

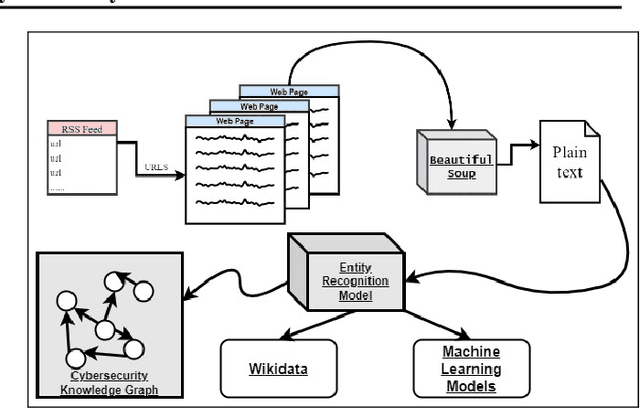
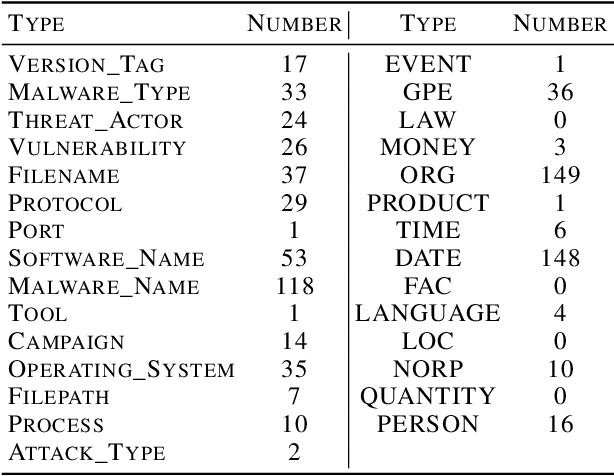
Cyber Threat Intelligence (CTI) is information describing threat vectors, vulnerabilities, and attacks and is often used as training data for AI-based cyber defense systems such as Cybersecurity Knowledge Graphs (CKG). There is a strong need to develop community-accessible datasets to train existing AI-based cybersecurity pipelines to efficiently and accurately extract meaningful insights from CTI. We have created an initial unstructured CTI corpus from a variety of open sources that we are using to train and test cybersecurity entity models using the spaCy framework and exploring self-learning methods to automatically recognize cybersecurity entities. We also describe methods to apply cybersecurity domain entity linking with existing world knowledge from Wikidata. Our future work will survey and test spaCy NLP tools and create methods for continuous integration of new information extracted from text.