 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Data Sharing in Agriculture: Enforcing Policy Rules for Secure and Confidential Data Synthesis
Nov 27, 2023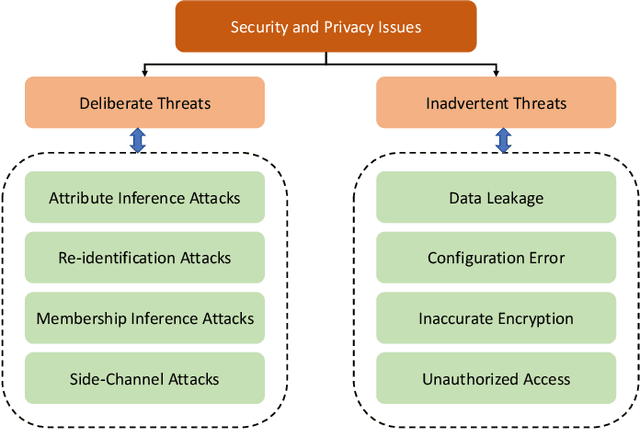
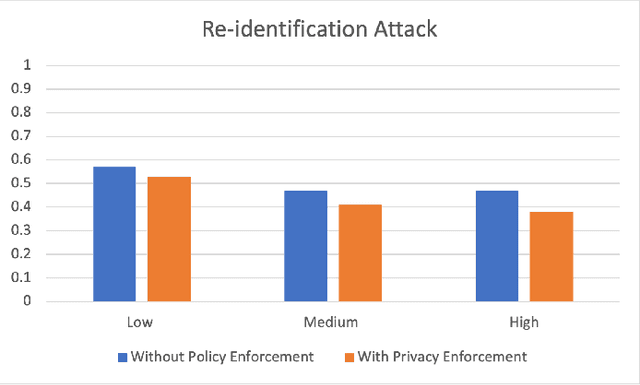
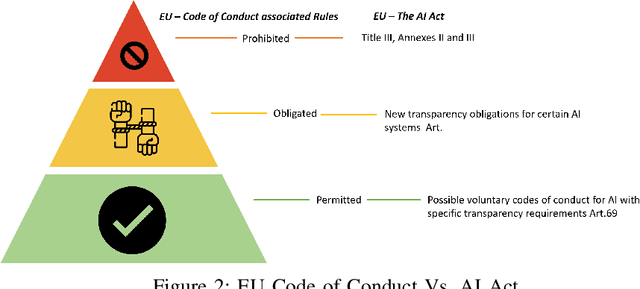
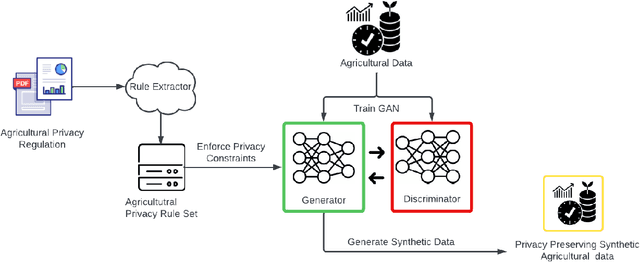
Big Data empowers the farming community with the information needed to optimize resource usage, increase productivity, and enhance the sustainability of agricultural practices. The use of Big Data in farming requires the collection and analysis of data from various sources such as sensors, satellites, and farmer surveys. While Big Data can provide the farming community with valuable insights and improve efficiency, there is significant concern regarding the security of this data as well as the privacy of the participants. Privacy regulations, such as the EU GDPR, the EU Code of Conduct on agricultural data sharing by contractual agreement, and the proposed EU AI law, have been created to address the issue of data privacy and provide specific guidelines on when and how data can be shared between organizations. To make confidential agricultural data widely available for Big Data analysis without violating the privacy of the data subjects, we consider privacy-preserving methods of data sharing in agriculture. Deep learning-based synthetic data generation has been proposed for privacy-preserving data sharing. However, there is a lack of compliance with documented data privacy policies in such privacy-preserving efforts. In this study, we propose a novel framework for enforcing privacy policy rules in privacy-preserving data generation algorithms. We explore several available agricultural codes of conduct, extract knowledge related to the privacy constraints in data, and use the extracted knowledge to define privacy bounds in a privacy-preserving generative model. We use our framework to generate synthetic agricultural data and present experimental results that demonstrate the utility of the synthetic dataset in downstream tasks. We also show that our framework can evade potential threats and secure data based on applicable regulatory policy rules.
Advances in Cybercrime Prediction: A Survey of Machine, Deep, Transfer, and Adaptive Learning Techniques
Apr 10, 2023



Cybercrime is a growing threat to organizations and individuals worldwide, with criminals using increasingly sophisticated techniques to breach security systems and steal sensitive data. In recent years, machine learning, deep learning, and transfer learning techniques have emerged as promising tools for predicting cybercrime and preventing it before it occurs. This paper aims to provide a comprehensive survey of the latest advancements in cybercrime prediction using above mentioned techniques, highlighting the latest research related to each approach. For this purpose, we reviewed more than 150 research articles and discussed around 50 most recent and relevant research articles. We start the review by discussing some common methods used by cyber criminals and then focus on the latest machine learning techniques and deep learning techniques, such as recurrent and convolutional neural networks, which were effective in detecting anomalous behavior and identifying potential threats. We also discuss transfer learning, which allows models trained on one dataset to be adapted for use on another dataset, and then focus on active and reinforcement Learning as part of early-stage algorithmic research in cybercrime prediction. Finally, we discuss critical innovations, research gaps, and future research opportunities in Cybercrime prediction. Overall, this paper presents a holistic view of cutting-edge developments in cybercrime prediction, shedding light on the strengths and limitations of each method and equipping researchers and practitioners with essential insights, publicly available datasets, and resources necessary to develop efficient cybercrime prediction systems.
Crime Prediction Using Machine Learning and Deep Learning: A Systematic Review and Future Directions
Mar 28, 2023



Predicting crime using machine learning and deep learning techniques has gained considerable attention from researchers in recent years, focusing on identifying patterns and trends in crime occurrences. This review paper examines over 150 articles to explore the various machine learning and deep learning algorithms applied to predict crime. The study provides access to the datasets used for crime prediction by researchers and analyzes prominent approaches applied in machine learning and deep learning algorithms to predict crime, offering insights into different trends and factors related to criminal activities. Additionally, the paper highlights potential gaps and future directions that can enhance the accuracy of crime prediction. Finally, the comprehensive overview of research discussed in this paper on crime prediction using machine learning and deep learning approaches serves as a valuable reference for researchers in this field. By gaining a deeper understanding of crime prediction techniques, law enforcement agencies can develop strategies to prevent and respond to criminal activities more effectively.
Student-centric Model of Learning Management System Activity and Academic Performance: from Correlation to Causation
Oct 27, 2022In recent years, there is a lot of interest in modeling students' digital traces in Learning Management System (LMS) to understand students' learning behavior patterns including aspects of meta-cognition and self-regulation, with the ultimate goal to turn those insights into actionable information to support students to improve their learning outcomes. In achieving this goal, however, there are two main issues that need to be addressed given the existing literature. Firstly, most of the current work is course-centered (i.e. models are built from data for a specific course) rather than student-centered; secondly, a vast majority of the models are correlational rather than causal. Those issues make it challenging to identify the most promising actionable factors for intervention at the student level where most of the campus-wide academic support is designed for. In this paper, we explored a student-centric analytical framework for LMS activity data that can provide not only correlational but causal insights mined from observational data. We demonstrated this approach using a dataset of 1651 computing major students at a public university in the US during one semester in the Fall of 2019. This dataset includes students' fine-grained LMS interaction logs and administrative data, e.g. demographics and academic performance. In addition, we expand the repository of LMS behavior indicators to include those that can characterize the time-of-the-day of login (e.g. chronotype). Our analysis showed that student login volume, compared with other login behavior indicators, is both strongly correlated and causally linked to student academic performance, especially among students with low academic performance. We envision that those insights will provide convincing evidence for college student support groups to launch student-centered and targeted interventions that are effective and scalable.
Do we need to go Deep? Knowledge Tracing with Big Data
Jan 20, 2021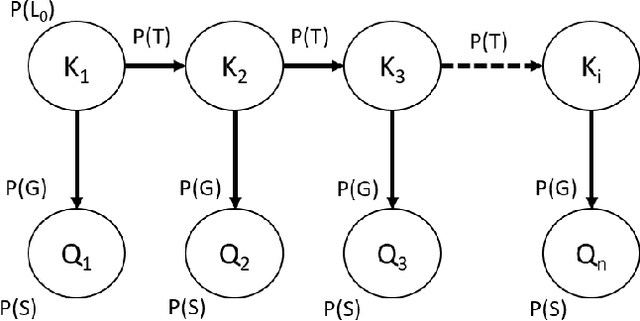
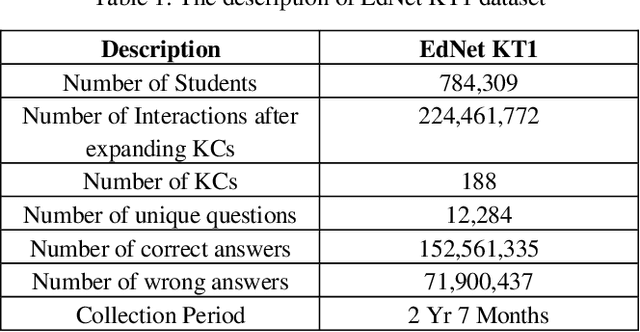
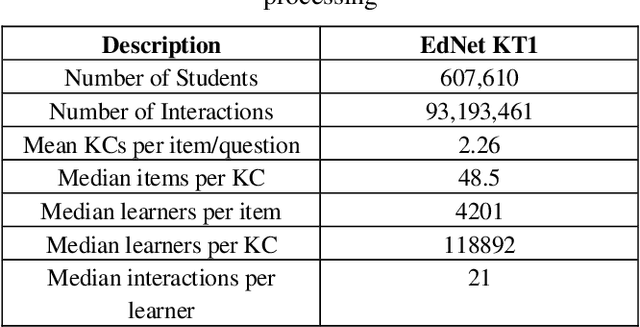
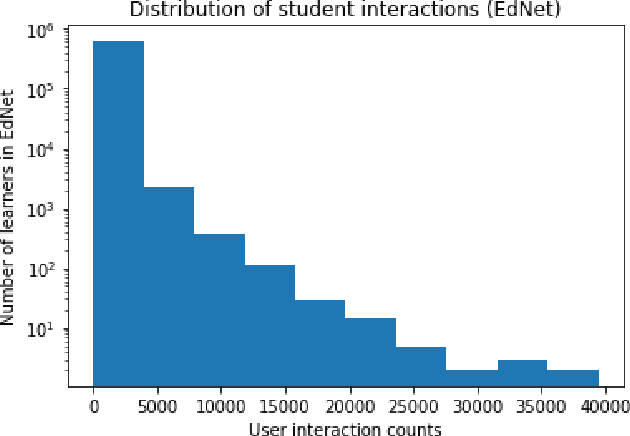
Interactive Educational Systems (IES) enabled researchers to trace student knowledge in different skills and provide recommendations for a better learning path. To estimate the student knowledge and further predict their future performance, the interest in utilizing the student interaction data captured by IES to develop learner performance models is increasing rapidly. Moreover, with the advances in computing systems, the amount of data captured by these IES systems is also increasing that enables deep learning models to compete with traditional logistic models and Markov processes. However, it is still not empirically evident if these deep models outperform traditional models on the current scale of datasets with millions of student interactions. In this work, we adopt EdNet, the largest student interaction dataset publicly available in the education domain, to understand how accurately both deep and traditional models predict future student performances. Our work observes that logistic regression models with carefully engineered features outperformed deep models from extensive experimentation. We follow this analysis with interpretation studies based on Locally Interpretable Model-agnostic Explanation (LIME) to understand the impact of various features on best performing model pre-dictions.