 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemhGPT: A Lightweight Generative Pre-Trained Transformer for Mental Health Text Analysis
Aug 15, 2024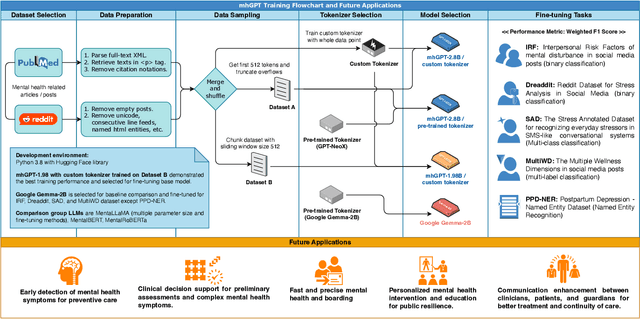
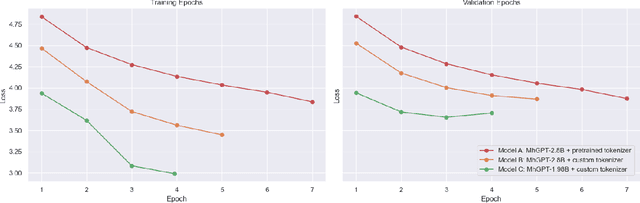

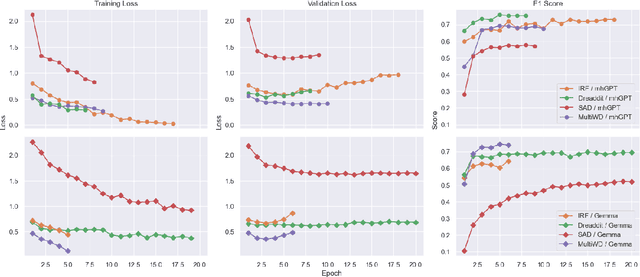
This paper introduces mhGPT, a lightweight generative pre-trained transformer trained on mental health-related social media and PubMed articles. Fine-tuned for specific mental health tasks, mhGPT was evaluated under limited hardware constraints and compared with state-of-the-art models like MentaLLaMA and Gemma. Despite having only 1.98 billion parameters and using just 5% of the dataset, mhGPT outperformed larger models and matched the performance of models trained on significantly more data. The key contributions include integrating diverse mental health data, creating a custom tokenizer, and optimizing a smaller architecture for low-resource settings. This research could advance AI-driven mental health care, especially in areas with limited computing power.
Unfolding the Structure of a Document using Deep Learning
Sep 29, 2019

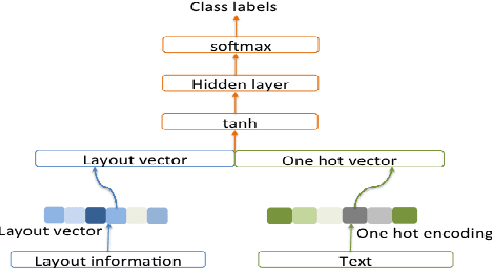

Understanding and extracting of information from large documents, such as business opportunities, academic articles, medical documents and technical reports, poses challenges not present in short documents. Such large documents may be multi-themed, complex, noisy and cover diverse topics. We describe a framework that can analyze large documents and help people and computer systems locate desired information in them. We aim to automatically identify and classify different sections of documents and understand their purpose within the document. A key contribution of our research is modeling and extracting the logical and semantic structure of electronic documents using deep learning techniques. We evaluate the effectiveness and robustness of our framework through extensive experiments on two collections: more than one million scholarly articles from arXiv and a collection of requests for proposal documents from government sources.
Query Expansion for Cross-Language Question Re-Ranking
Apr 16, 2019
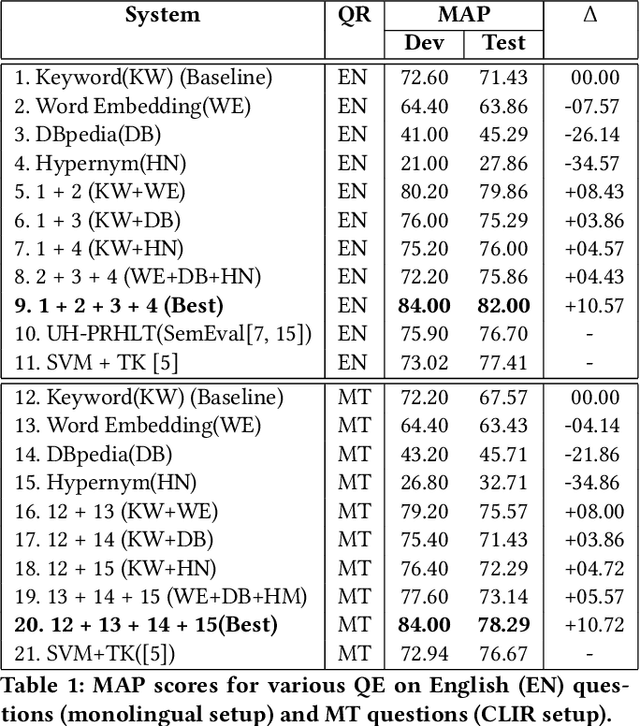
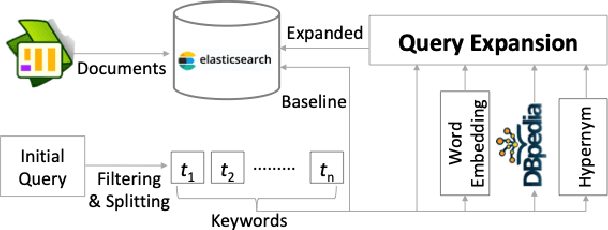

Community question-answering (CQA) platforms have become very popular forums for asking and answering questions daily. While these forums are rich repositories of community knowledge, they present challenges for finding relevant answers and similar questions, due to the open-ended nature of informal discussions. Further, if the platform allows questions and answers in multiple languages, we are faced with the additional challenge of matching cross-lingual information. In this work, we focus on the cross-language question re-ranking shared task, which aims to find existing questions that may be written in different languages. Our contribution is an exploration of query expansion techniques for this problem. We investigate expansions based on Word Embeddings, DBpedia concepts linking, and Hypernym, and show that they outperform existing state-of-the-art methods.
Understanding and representing the semantics of large structured documents
Jul 24, 2018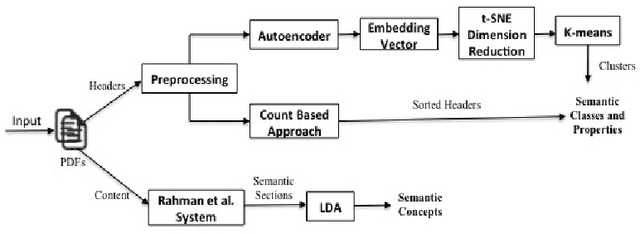
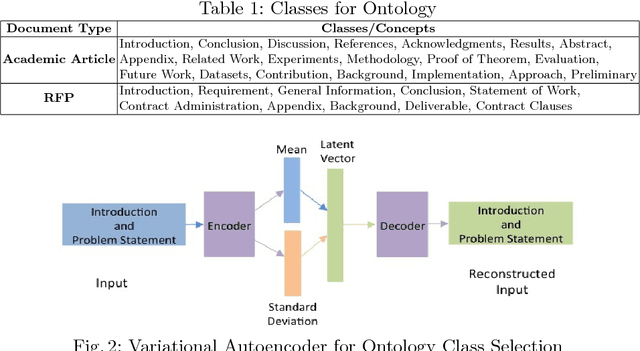

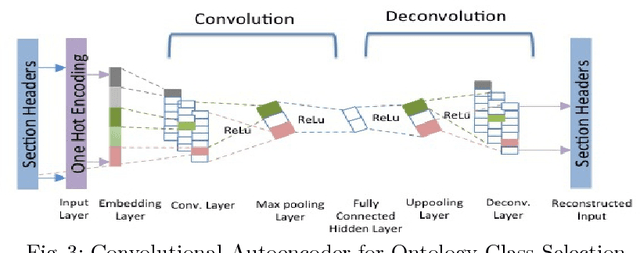
Understanding large, structured documents like scholarly articles, requests for proposals or business reports is a complex and difficult task. It involves discovering a document's overall purpose and subject(s), understanding the function and meaning of its sections and subsections, and extracting low level entities and facts about them. In this research, we present a deep learning based document ontology to capture the general purpose semantic structure and domain specific semantic concepts from a large number of academic articles and business documents. The ontology is able to describe different functional parts of a document, which can be used to enhance semantic indexing for a better understanding by human beings and machines. We evaluate our models through extensive experiments on datasets of scholarly articles from arXiv and Request for Proposal documents.
* 10 pages, 6 figures, 28 references and 2 tables
Understanding the Logical and Semantic Structure of Large Documents
Sep 03, 2017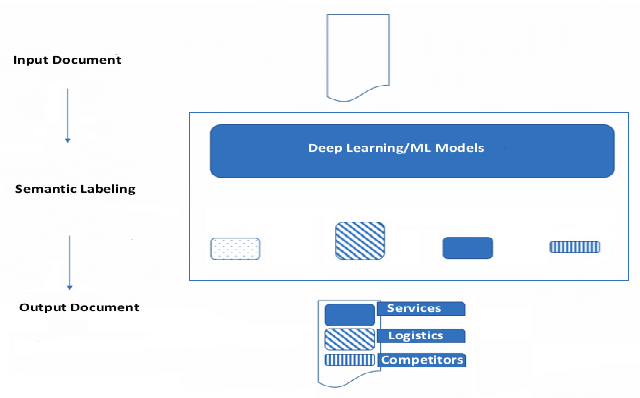


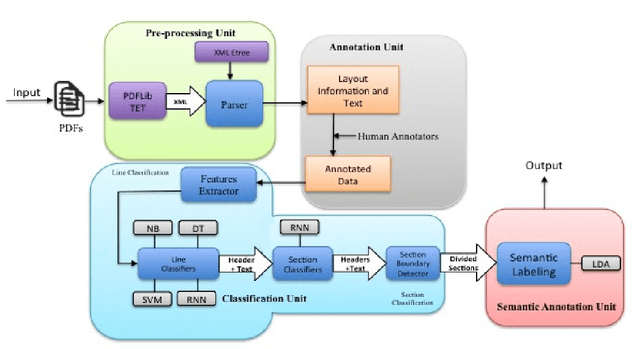
Current language understanding approaches focus on small documents, such as newswire articles, blog posts, product reviews and discussion forum entries. Understanding and extracting information from large documents like legal briefs, proposals, technical manuals and research articles is still a challenging task. We describe a framework that can analyze a large document and help people to know where a particular information is in that document. We aim to automatically identify and classify semantic sections of documents and assign consistent and human-understandable labels to similar sections across documents. A key contribution of our research is modeling the logical and semantic structure of an electronic document. We apply machine learning techniques, including deep learning, in our prototype system. We also make available a dataset of information about a collection of scholarly articles from the arXiv eprints collection that includes a wide range of metadata for each article, including a table of contents, section labels, section summarizations and more. We hope that this dataset will be a useful resource for the machine learning and NLP communities in information retrieval, content-based question answering and language modeling.
Mining Social Data to Extract Intellectual Knowledge
Sep 24, 2012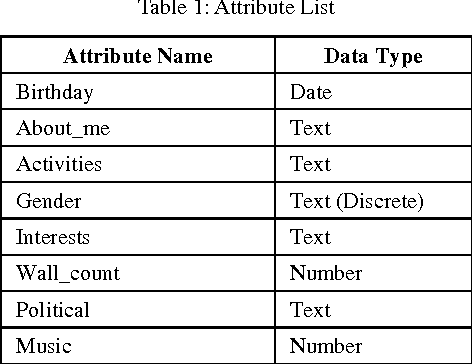


Social data mining is an interesting phe-nomenon which colligates different sources of social data to extract information. This information can be used in relationship prediction, decision making, pat-tern recognition, social mapping, responsibility distri-bution and many other applications. This paper presents a systematical data mining architecture to mine intellectual knowledge from social data. In this research, we use social networking site facebook as primary data source. We collect different attributes such as about me, comments, wall post and age from facebook as raw data and use advanced data mining approaches to excavate intellectual knowledge. We also analyze our mined knowledge with comparison for possible usages like as human behavior prediction, pattern recognition, job responsibility distribution, decision making and product promoting.
* 8 pages, 19 figures, 4 tables, 3 equations, ISSN: 2074-904X (Print), ISSN: 2074-9058 (Online)