 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and representing the semantics of large structured documents
Paper and Code
Jul 24, 2018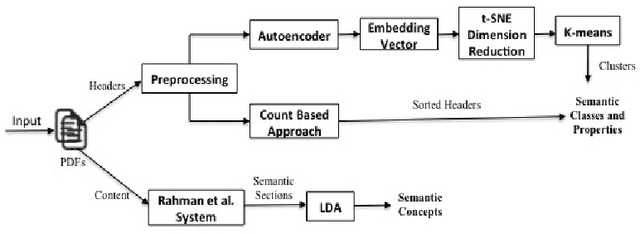
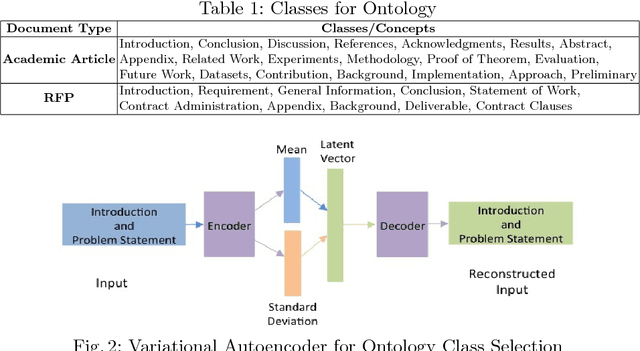

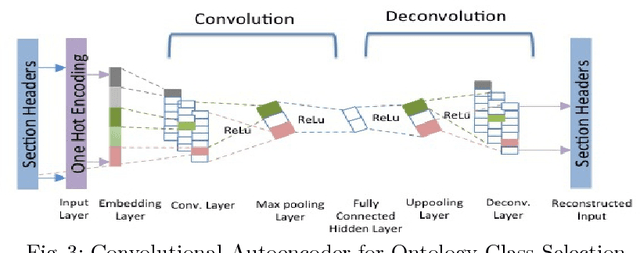
Understanding large, structured documents like scholarly articles, requests for proposals or business reports is a complex and difficult task. It involves discovering a document's overall purpose and subject(s), understanding the function and meaning of its sections and subsections, and extracting low level entities and facts about them. In this research, we present a deep learning based document ontology to capture the general purpose semantic structure and domain specific semantic concepts from a large number of academic articles and business documents. The ontology is able to describe different functional parts of a document, which can be used to enhance semantic indexing for a better understanding by human beings and machines. We evaluate our models through extensive experiments on datasets of scholarly articles from arXiv and Request for Proposal documents.