 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Logical and Semantic Structure of Large Documents
Paper and Code
Sep 03, 2017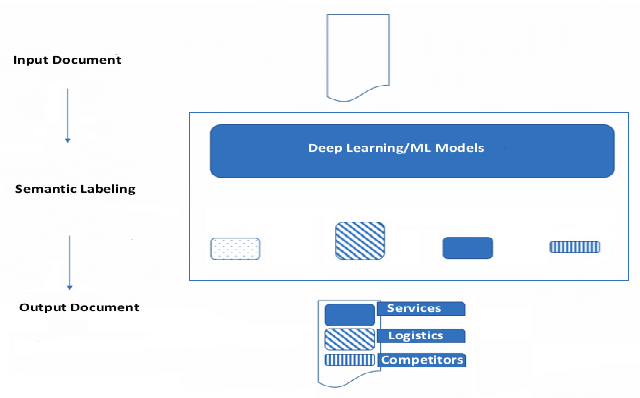


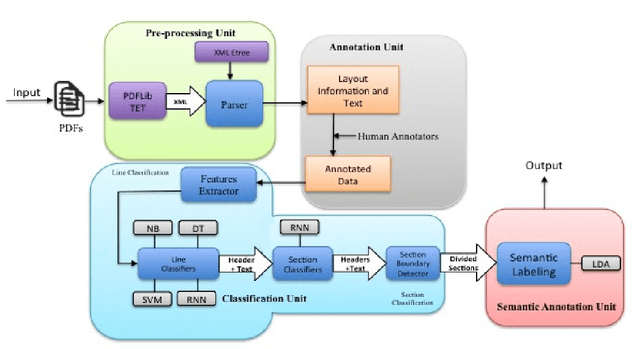
Current language understanding approaches focus on small documents, such as newswire articles, blog posts, product reviews and discussion forum entries. Understanding and extracting information from large documents like legal briefs, proposals, technical manuals and research articles is still a challenging task. We describe a framework that can analyze a large document and help people to know where a particular information is in that document. We aim to automatically identify and classify semantic sections of documents and assign consistent and human-understandable labels to similar sections across documents. A key contribution of our research is modeling the logical and semantic structure of an electronic document. We apply machine learning techniques, including deep learning, in our prototype system. We also make available a dataset of information about a collection of scholarly articles from the arXiv eprints collection that includes a wide range of metadata for each article, including a table of contents, section labels, section summarizations and more. We hope that this dataset will be a useful resource for the machine learning and NLP communities in information retrieval, content-based question answering and language modeling.