 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemanticity or Polysemy? Lexical Identity Confounds Superposition Metrics
Apr 01, 2026If the same neuron activates for both "lender" and "riverside," standard metrics attribute the overlap to superposition--the neuron must be compressing two unrelated concepts. This work explores how much of the overlap is due a lexical confound: neurons fire for a shared word form (such as "bank") rather than for two compressed concepts. A 2x2 factorial decomposition reveals that the lexical-only condition (same word, different meaning) consistently exceeds the semantic-only condition (different word, same meaning) across models spanning 110M-70B parameters. The confound carries into sparse autoencoders (18-36% of features blend senses), sits in <=1% of activation dimensions, and hurts downstream tasks: filtering it out improves word sense disambiguation and makes knowledge edits more selective (p = 0.002).
mhGPT: A Lightweight Generative Pre-Trained Transformer for Mental Health Text Analysis
Aug 15, 2024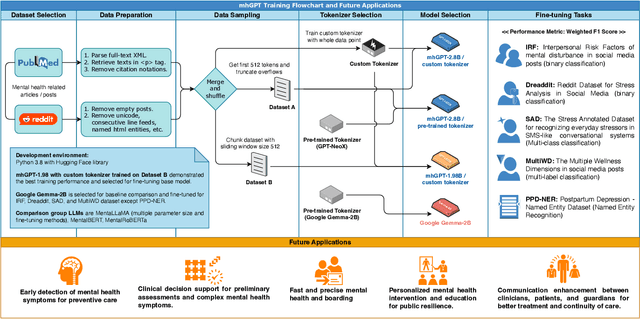
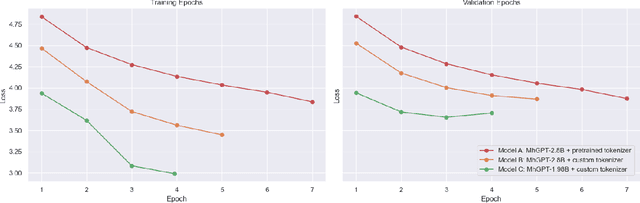

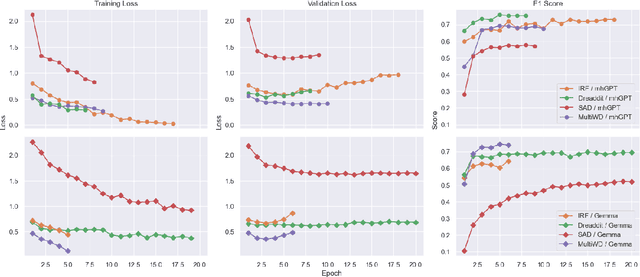
This paper introduces mhGPT, a lightweight generative pre-trained transformer trained on mental health-related social media and PubMed articles. Fine-tuned for specific mental health tasks, mhGPT was evaluated under limited hardware constraints and compared with state-of-the-art models like MentaLLaMA and Gemma. Despite having only 1.98 billion parameters and using just 5% of the dataset, mhGPT outperformed larger models and matched the performance of models trained on significantly more data. The key contributions include integrating diverse mental health data, creating a custom tokenizer, and optimizing a smaller architecture for low-resource settings. This research could advance AI-driven mental health care, especially in areas with limited computing power.
Tribe or Not? Critical Inspection of Group Differences Using TribalGram
Mar 16, 2023

With the rise of AI and data mining techniques, group profiling and group-level analysis have been increasingly used in many domains including policy making and direct marketing. In some cases, the statistics extracted from data may provide insights to a group's shared characteristics; in others, the group-level analysis can lead to problems including stereotyping and systematic oppression. How can analytic tools facilitate a more conscientious process in group analysis? In this work, we identify a set of accountable group analytics design guidelines to explicate the needs for group differentiation and preventing overgeneralization of a group. Following the design guidelines, we develop TribalGram, a visual analytic suite that leverages interpretable machine learning algorithms and visualization to offer inference assessment, model explanation, data corroboration, and sense-making. Through the interviews with domain experts, we showcase how our design and tools can bring a richer understanding of "groups" mined from the data.
ArgRewrite V.2: an Annotated Argumentative Revisions Corpus
Jun 03, 2022Analyzing how humans revise their writings is an interesting research question, not only from an educational perspective but also in terms of artificial intelligence. Better understanding of this process could facilitate many NLP applications, from intelligent tutoring systems to supportive and collaborative writing environments. Developing these applications, however, requires revision corpora, which are not widely available. In this work, we present ArgRewrite V.2, a corpus of annotated argumentative revisions, collected from two cycles of revisions to argumentative essays about self-driving cars. Annotations are provided at different levels of purpose granularity (coarse and fine) and scope (sentential and subsentential). In addition, the corpus includes the revision goal given to each writer, essay scores, annotation verification, pre- and post-study surveys collected from participants as meta-data. The variety of revision unit scope and purpose granularity levels in ArgRewrite, along with the inclusion of new types of meta-data, can make it a useful resource for research and applications that involve revision analysis. We demonstrate some potential applications of ArgRewrite V.2 in the development of automatic revision purpose predictors, as a training source and benchmark.
BasisNet: Two-stage Model Synthesis for Efficient Inference
May 07, 2021
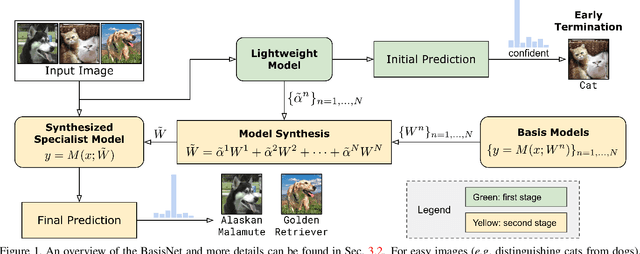

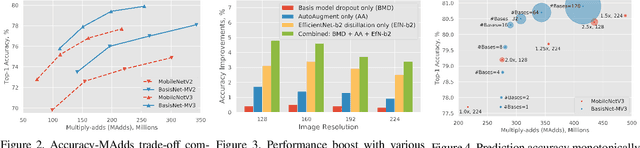
In this work, we present BasisNet which combines recent advancements in efficient neural network architectures, conditional computation, and early termination in a simple new form. Our approach incorporates a lightweight model to preview the input and generate input-dependent combination coefficients, which later controls the synthesis of a more accurate specialist model to make final prediction. The two-stage model synthesis strategy can be applied to any network architectures and both stages are jointly trained. We also show that proper training recipes are critical for increasing generalizability for such high capacity neural networks. On ImageNet classification benchmark, our BasisNet with MobileNets as backbone demonstrated clear advantage on accuracy-efficiency trade-off over several strong baselines. Specifically, BasisNet-MobileNetV3 obtained 80.3% top-1 accuracy with only 290M Multiply-Add operations, halving the computational cost of previous state-of-the-art without sacrificing accuracy. With early termination, the average cost can be further reduced to 198M MAdds while maintaining accuracy of 80.0% on ImageNet.
Domain-robust VQA with diverse datasets and methods but no target labels
Mar 29, 2021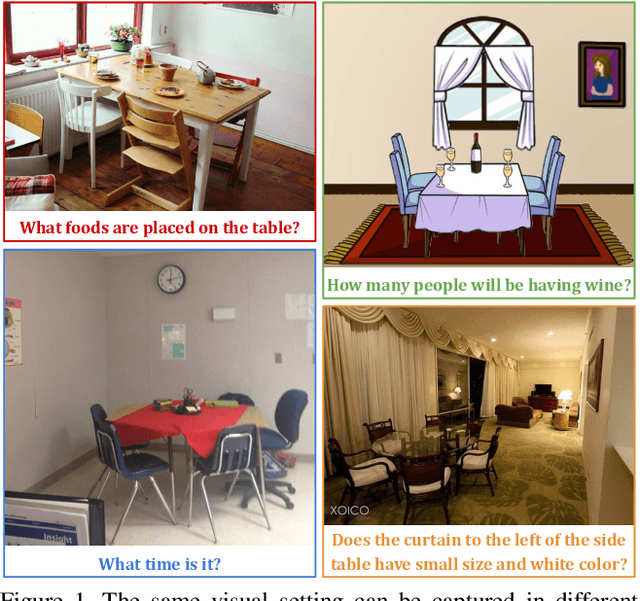


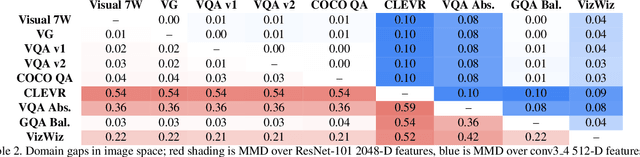
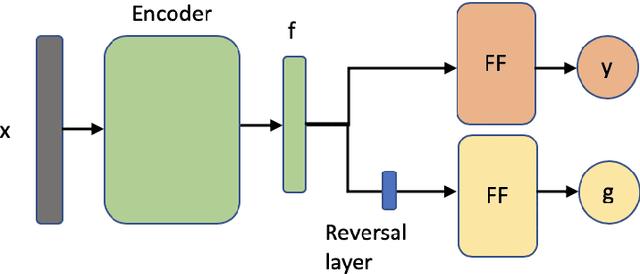
The observation that computer vision methods overfit to dataset specifics has inspired diverse attempts to make object recognition models robust to domain shifts. However, similar work on domain-robust visual question answering methods is very limited. Domain adaptation for VQA differs from adaptation for object recognition due to additional complexity: VQA models handle multimodal inputs, methods contain multiple steps with diverse modules resulting in complex optimization, and answer spaces in different datasets are vastly different. To tackle these challenges, we first quantify domain shifts between popular VQA datasets, in both visual and textual space. To disentangle shifts between datasets arising from different modalities, we also construct synthetic shifts in the image and question domains separately. Second, we test the robustness of different families of VQA methods (classic two-stream, transformer, and neuro-symbolic methods) to these shifts. Third, we test the applicability of existing domain adaptation methods and devise a new one to bridge VQA domain gaps, adjusted to specific VQA models. To emulate the setting of real-world generalization, we focus on unsupervised domain adaptation and the open-ended classification task formulation.
Inflating Topic Relevance with Ideology: A Case Study of Political Ideology Bias in Social Topic Detection Models
Nov 29, 2020
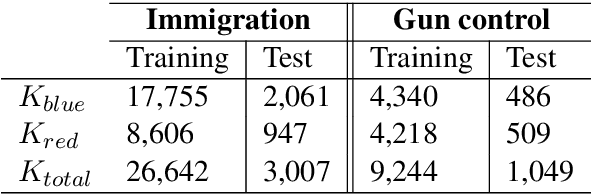
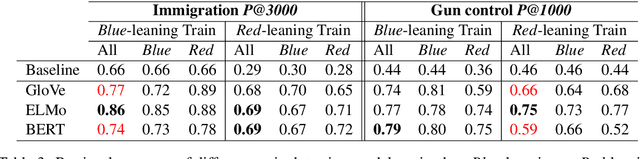
We investigate the impact of political ideology biases in training data. Through a set of comparison studies, we examine the propagation of biases in several widely-used NLP models and its effect on the overall retrieval accuracy. Our work highlights the susceptibility of large, complex models to propagating the biases from human-selected input, which may lead to a deterioration of retrieval accuracy, and the importance of controlling for these biases. Finally, as a way to mitigate the bias, we propose to learn a text representation that is invariant to political ideology while still judging topic relevance.
Equal But Not The Same: Understanding the Implicit Relationship Between Persuasive Images and Text
Jul 21, 2018



Images and text in advertisements interact in complex, non-literal ways. The two channels are usually complementary, with each channel telling a different part of the story. Current approaches, such as image captioning methods, only examine literal, redundant relationships, where image and text show exactly the same content. To understand more complex relationships, we first collect a dataset of advertisement interpretations for whether the image and slogan in the same visual advertisement form a parallel (conveying the same message without literally saying the same thing) or non-parallel relationship, with the help of workers recruited on Amazon Mechanical Turk. We develop a variety of features that capture the creativity of images and the specificity or ambiguity of text, as well as methods that analyze the semantics within and across channels. We show that our method outperforms standard image-text alignment approaches on predicting the parallel/non-parallel relationship between image and text.
An Interactive Tool for Natural Language Processing on Clinical Text
Jul 07, 2017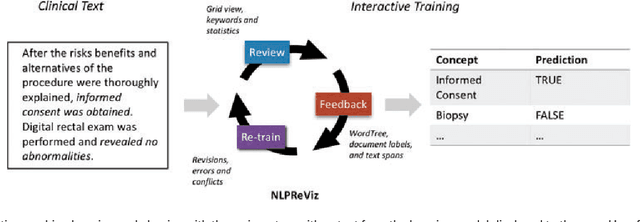
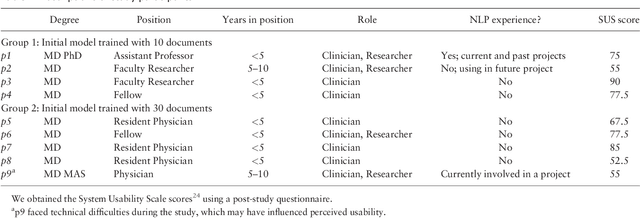
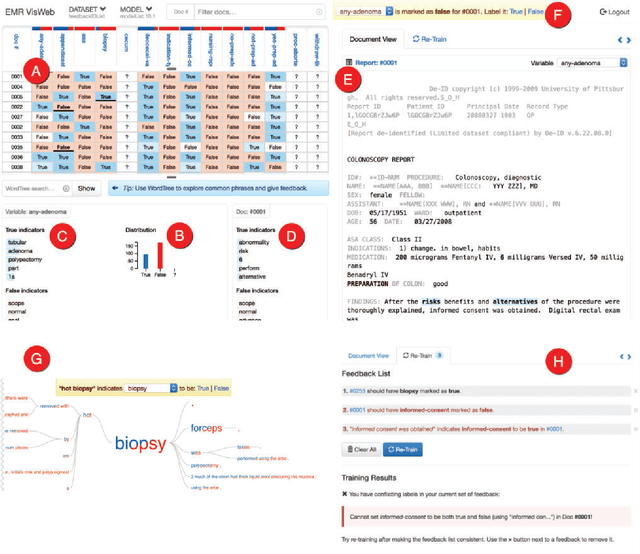
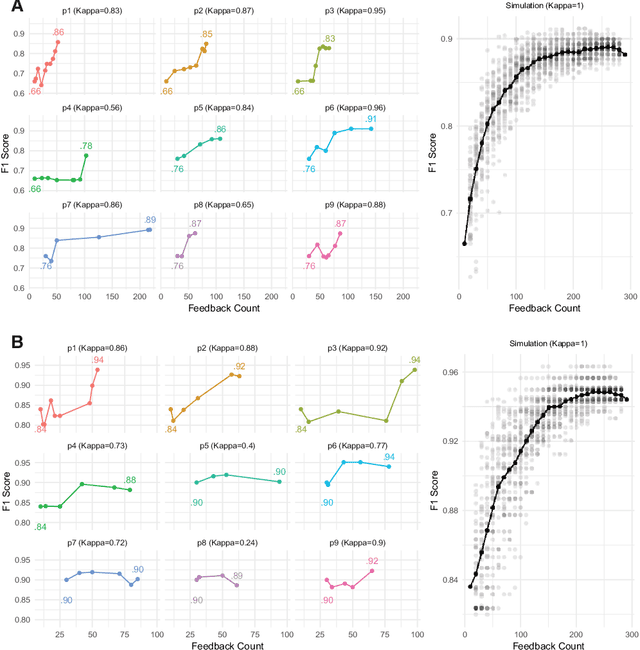
Natural Language Processing (NLP) systems often make use of machine learning techniques that are unfamiliar to end-users who are interested in analyzing clinical records. Although NLP has been widely used in extracting information from clinical text, current systems generally do not support model revision based on feedback from domain experts. We present a prototype tool that allows end users to visualize and review the outputs of an NLP system that extracts binary variables from clinical text. Our tool combines multiple visualizations to help the users understand these results and make any necessary corrections, thus forming a feedback loop and helping improve the accuracy of the NLP models. We have tested our prototype in a formative think-aloud user study with clinicians and researchers involved in colonoscopy research. Results from semi-structured interviews and a System Usability Scale (SUS) analysis show that the users are able to quickly start refining NLP models, despite having very little or no experience with machine learning. Observations from these sessions suggest revisions to the interface to better support review workflow and interpretation of results.
Supervised Grammar Induction Using Training Data with Limited Constituent Information
May 02, 1999


Corpus-based grammar induction generally relies on hand-parsed training data to learn the structure of the language. Unfortunately, the cost of building large annotated corpora is prohibitively expensive. This work aims to improve the induction strategy when there are few labels in the training data. We show that the most informative linguistic constituents are the higher nodes in the parse trees, typically denoting complex noun phrases and sentential clauses. They account for only 20% of all constituents. For inducing grammars from sparsely labeled training data (e.g., only higher-level constituent labels), we propose an adaptation strategy, which produces grammars that parse almost as well as grammars induced from fully labeled corpora. Our results suggest that for a partial parser to replace human annotators, it must be able to automatically extract higher-level constituents rather than base noun phrases.