 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgRewrite V.2: an Annotated Argumentative Revisions Corpus
Jun 03, 2022Analyzing how humans revise their writings is an interesting research question, not only from an educational perspective but also in terms of artificial intelligence. Better understanding of this process could facilitate many NLP applications, from intelligent tutoring systems to supportive and collaborative writing environments. Developing these applications, however, requires revision corpora, which are not widely available. In this work, we present ArgRewrite V.2, a corpus of annotated argumentative revisions, collected from two cycles of revisions to argumentative essays about self-driving cars. Annotations are provided at different levels of purpose granularity (coarse and fine) and scope (sentential and subsentential). In addition, the corpus includes the revision goal given to each writer, essay scores, annotation verification, pre- and post-study surveys collected from participants as meta-data. The variety of revision unit scope and purpose granularity levels in ArgRewrite, along with the inclusion of new types of meta-data, can make it a useful resource for research and applications that involve revision analysis. We demonstrate some potential applications of ArgRewrite V.2 in the development of automatic revision purpose predictors, as a training source and benchmark.
Discussion Tracker: Supporting Teacher Learning about Students' Collaborative Argumentation in High School Classrooms
Feb 20, 2021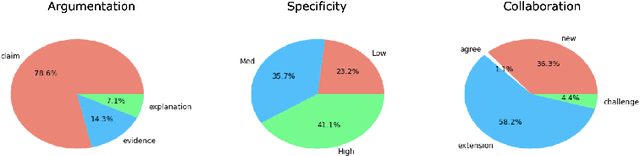

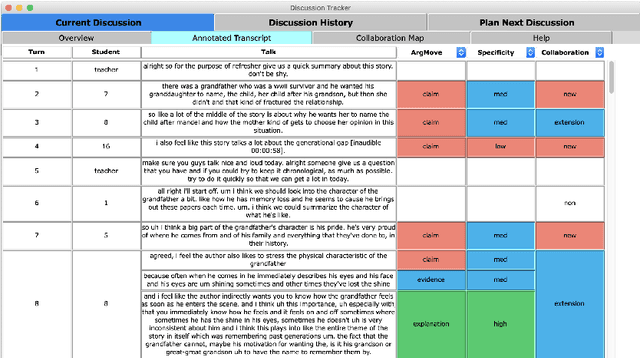
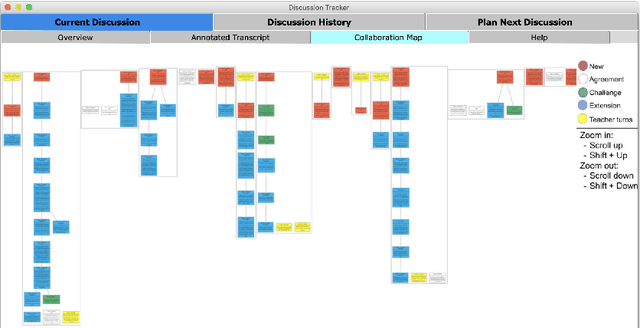
Teaching collaborative argumentation is an advanced skill that many K-12 teachers struggle to develop. To address this, we have developed Discussion Tracker, a classroom discussion analytics system based on novel algorithms for classifying argument moves, specificity, and collaboration. Results from a classroom deployment indicate that teachers found the analytics useful, and that the underlying classifiers perform with moderate to substantial agreement with humans.
The Discussion Tracker Corpus of Collaborative Argumentation
May 22, 2020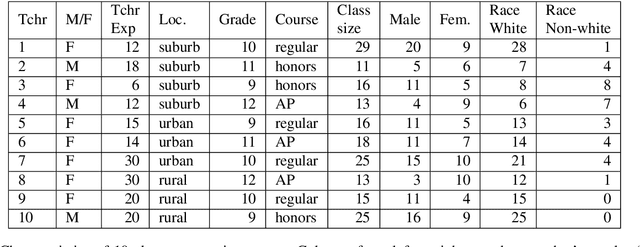
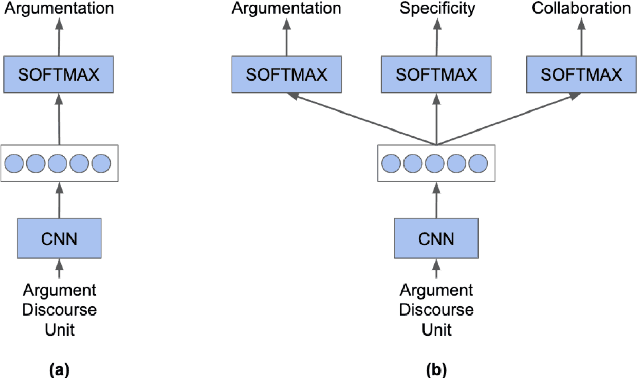
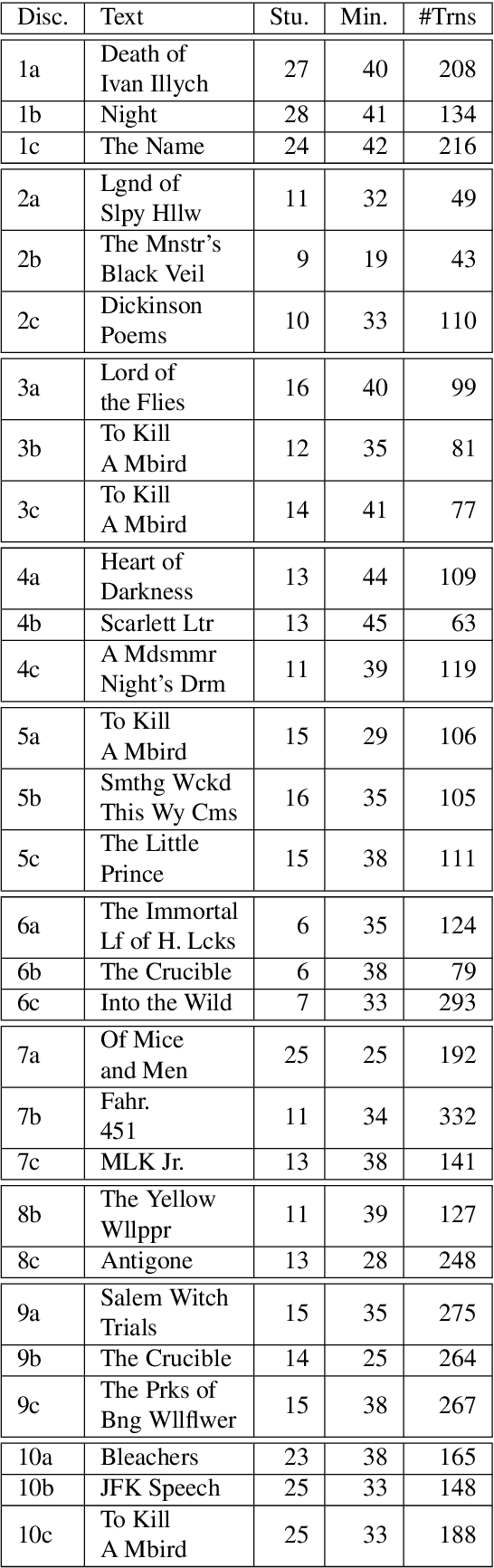
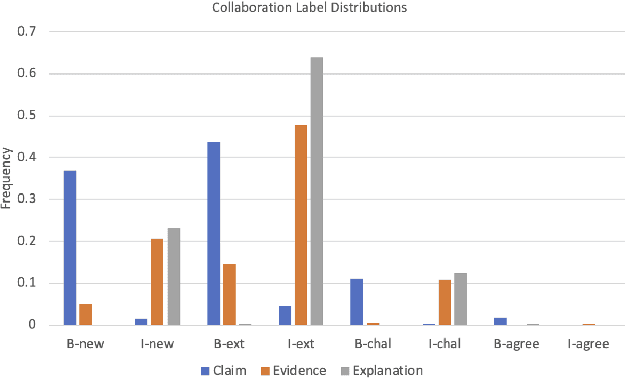
Although Natural Language Processing (NLP) research on argument mining has advanced considerably in recent years, most studies draw on corpora of asynchronous and written texts, often produced by individuals. Few published corpora of synchronous, multi-party argumentation are available. The Discussion Tracker corpus, collected in American high school English classes, is an annotated dataset of transcripts of spoken, multi-party argumentation. The corpus consists of 29 multi-party discussions of English literature transcribed from 985 minutes of audio. The transcripts were annotated for three dimensions of collaborative argumentation: argument moves (claims, evidence, and explanations), specificity (low, medium, high) and collaboration (e.g., extensions of and disagreements about others' ideas). In addition to providing descriptive statistics on the corpus, we provide performance benchmarks and associated code for predicting each dimension separately, illustrate the use of the multiple annotations in the corpus to improve performance via multi-task learning, and finally discuss other ways the corpus might be used to further NLP research.
Annotating Student Talk in Text-based Classroom Discussions
Sep 06, 2019

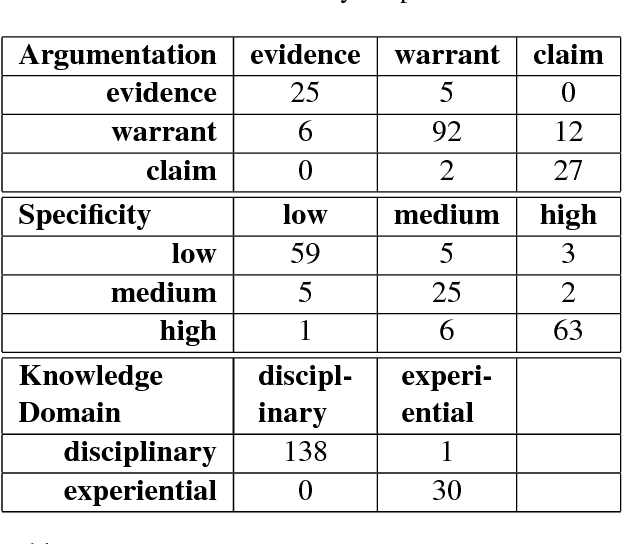
Classroom discussions in English Language Arts have a positive effect on students' reading, writing and reasoning skills. Although prior work has largely focused on teacher talk and student-teacher interactions, we focus on three theoretically-motivated aspects of high-quality student talk: argumentation, specificity, and knowledge domain. We introduce an annotation scheme, then show that the scheme can be used to produce reliable annotations and that the annotations are predictive of discussion quality. We also highlight opportunities provided by our scheme for education and natural language processing research.