 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Unlearning in Collaborative Optimization: Exact and Approximate Influence Reversal under Adversarial Contributions
May 19, 2026Federated learning systems must support data deletion requests to comply with privacy regulations, yet retraining from scratch after each deletion is computationally prohibitive. We present HF-KCU, a method that removes a client's contribution by approximating the influence function through conjugate gradient iterations in Krylov subspaces, reducing complexity from O(d^3) to O(kd) where k<<d.A causal weighting mechanism ensures that only clients holding the deleted data receive parameter updates, preventing spurious changes to unaffected clients. Our method is designed to handle bounded adversarial perturbations to the Hessian and gradient, providing graceful degradation under realistic threat models. We validate HF-KCU across convolutional (ResNet-18, SimpleCNN) and transformer (ViT-Lite) architectures on CIFAR-10, MNIST, and Fashion-MNIST. On CIFAR-10 under Dirichlet (alpha=0.5) partitioning, HF-KCU achieves 47.75 times speedup over retraining while maintaining test accuracy within 0.60% of the rational baseline(71.16 vs 71.76 %). Membership inference attacks on the forget set yield success rates of 0.499 matching the retrained model and confirming effective privacy restoration. We provide convergence guarantees showing that the Krylov approximation error decreases as O((k ^1/2-1)/(k^1/2+1)) where k is the Hessian condition number. The causal weighting mechanism ensures surgical updates, where only clients holding deleted data are modified, preserving model quality for unaffected participants and avoiding the instability of gradient-based approaches in asynchronous federated settings. This design provides interpretability as each update is directly traceable to the influence of the deleted data. The method's efficiency and precision make it suitable for production federated systems where deletion requests arrive asynchronously and computational budgets are constrained.
ArgRewrite V.2: an Annotated Argumentative Revisions Corpus
Jun 03, 2022Analyzing how humans revise their writings is an interesting research question, not only from an educational perspective but also in terms of artificial intelligence. Better understanding of this process could facilitate many NLP applications, from intelligent tutoring systems to supportive and collaborative writing environments. Developing these applications, however, requires revision corpora, which are not widely available. In this work, we present ArgRewrite V.2, a corpus of annotated argumentative revisions, collected from two cycles of revisions to argumentative essays about self-driving cars. Annotations are provided at different levels of purpose granularity (coarse and fine) and scope (sentential and subsentential). In addition, the corpus includes the revision goal given to each writer, essay scores, annotation verification, pre- and post-study surveys collected from participants as meta-data. The variety of revision unit scope and purpose granularity levels in ArgRewrite, along with the inclusion of new types of meta-data, can make it a useful resource for research and applications that involve revision analysis. We demonstrate some potential applications of ArgRewrite V.2 in the development of automatic revision purpose predictors, as a training source and benchmark.
Unsupervised Part-of-Speech Induction
Jan 10, 2018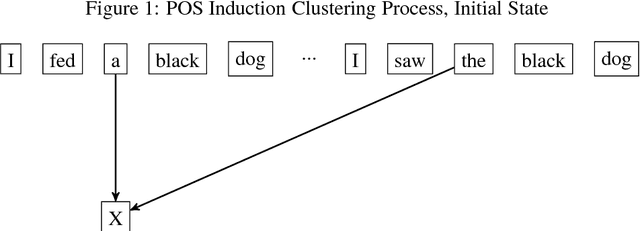

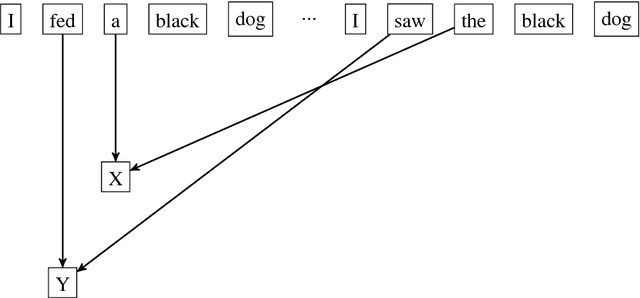
Part-of-Speech (POS) tagging is an old and fundamental task in natural language processing. While supervised POS taggers have shown promising accuracy, it is not always feasible to use supervised methods due to lack of labeled data. In this project, we attempt to unsurprisingly induce POS tags by iteratively looking for a recurring pattern of words through a hierarchical agglomerative clustering process. Our approach shows promising results when compared to the tagging results of the state-of-the-art unsupervised POS taggers.
MIZAN: A Large Persian-English Parallel Corpus
Jan 10, 2018



One of the most major and essential tasks in natural language processing is machine translation that is now highly dependent upon multilingual parallel corpora. Through this paper, we introduce the biggest Persian-English parallel corpus with more than one million sentence pairs collected from masterpieces of literature. We also present acquisition process and statistics of the corpus, and experiment a base-line statistical machine translation system using the corpus.