 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Auxiliary Sources in Argumentative Revision Classification
Sep 13, 2023We develop models to classify desirable reasoning revisions in argumentative writing. We explore two approaches -- multi-task learning and transfer learning -- to take advantage of auxiliary sources of revision data for similar tasks. Results of intrinsic and extrinsic evaluations show that both approaches can indeed improve classifier performance over baselines. While multi-task learning shows that training on different sources of data at the same time may improve performance, transfer-learning better represents the relationship between the data.
Predicting Desirable Revisions of Evidence and Reasoning in Argumentative Writing
Feb 10, 2023We develop models to classify desirable evidence and desirable reasoning revisions in student argumentative writing. We explore two ways to improve classifier performance - using the essay context of the revision, and using the feedback students received before the revision. We perform both intrinsic and extrinsic evaluation for each of our models and report a qualitative analysis. Our results show that while a model using feedback information improves over a baseline model, models utilizing context - either alone or with feedback - are the most successful in identifying desirable revisions.
ArgRewrite V.2: an Annotated Argumentative Revisions Corpus
Jun 03, 2022Analyzing how humans revise their writings is an interesting research question, not only from an educational perspective but also in terms of artificial intelligence. Better understanding of this process could facilitate many NLP applications, from intelligent tutoring systems to supportive and collaborative writing environments. Developing these applications, however, requires revision corpora, which are not widely available. In this work, we present ArgRewrite V.2, a corpus of annotated argumentative revisions, collected from two cycles of revisions to argumentative essays about self-driving cars. Annotations are provided at different levels of purpose granularity (coarse and fine) and scope (sentential and subsentential). In addition, the corpus includes the revision goal given to each writer, essay scores, annotation verification, pre- and post-study surveys collected from participants as meta-data. The variety of revision unit scope and purpose granularity levels in ArgRewrite, along with the inclusion of new types of meta-data, can make it a useful resource for research and applications that involve revision analysis. We demonstrate some potential applications of ArgRewrite V.2 in the development of automatic revision purpose predictors, as a training source and benchmark.
Annotation and Classification of Evidence and Reasoning Revisions in Argumentative Writing
Jul 14, 2021


Automated writing evaluation systems can improve students' writing insofar as students attend to the feedback provided and revise their essay drafts in ways aligned with such feedback. Existing research on revision of argumentative writing in such systems, however, has focused on the types of revisions students make (e.g., surface vs. content) rather than the extent to which revisions actually respond to the feedback provided and improve the essay. We introduce an annotation scheme to capture the nature of sentence-level revisions of evidence use and reasoning (the `RER' scheme) and apply it to 5th- and 6th-grade students' argumentative essays. We show that reliable manual annotation can be achieved and that revision annotations correlate with a holistic assessment of essay improvement in line with the feedback provided. Furthermore, we explore the feasibility of automatically classifying revisions according to our scheme.
Annotation and Classification of Sentence-level Revision Improvement
Sep 03, 2019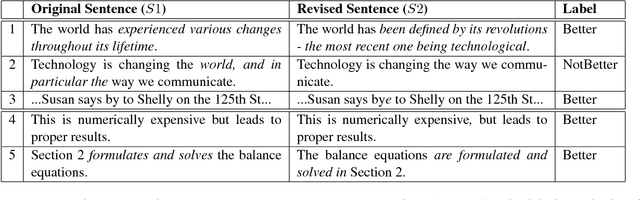
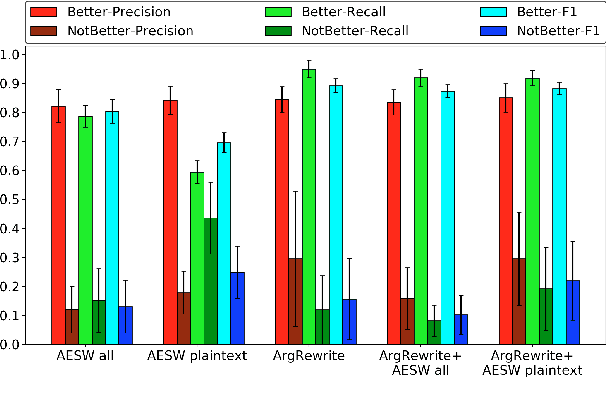


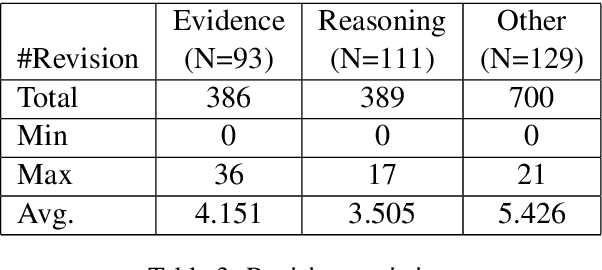
Studies of writing revisions rarely focus on revision quality. To address this issue, we introduce a corpus of between-draft revisions of student argumentative essays, annotated as to whether each revision improves essay quality. We demonstrate a potential usage of our annotations by developing a machine learning model to predict revision improvement. With the goal of expanding training data, we also extract revisions from a dataset edited by expert proofreaders. Our results indicate that blending expert and non-expert revisions increases model performance, with expert data particularly important for predicting low-quality revisions.
Identifying Editor Roles in Argumentative Writing from Student Revision Histories
Sep 03, 2019

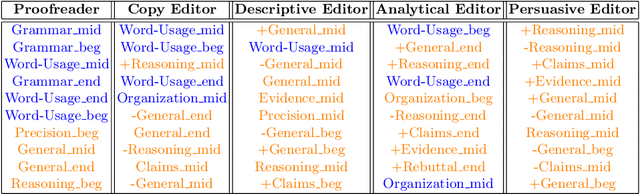

We present a method for identifying editor roles from students' revision behaviors during argumentative writing. We first develop a method for applying a topic modeling algorithm to identify a set of editor roles from a vocabulary capturing three aspects of student revision behaviors: operation, purpose, and position. We validate the identified roles by showing that modeling the editor roles that students take when revising a paper not only accounts for the variance in revision purposes in our data, but also relates to writing improvement.