Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInflating Topic Relevance with Ideology: A Case Study of Political Ideology Bias in Social Topic Detection Models
Paper and Code

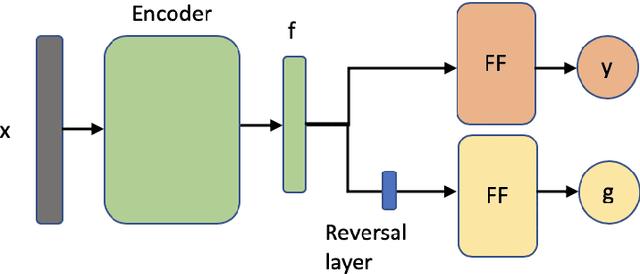
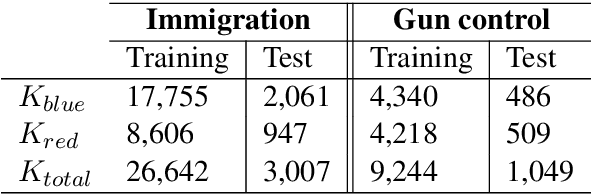
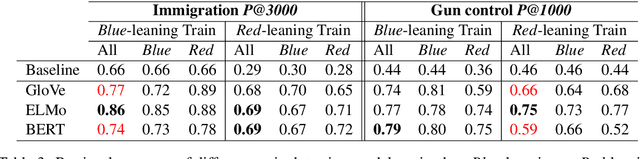
We investigate the impact of political ideology biases in training data. Through a set of comparison studies, we examine the propagation of biases in several widely-used NLP models and its effect on the overall retrieval accuracy. Our work highlights the susceptibility of large, complex models to propagating the biases from human-selected input, which may lead to a deterioration of retrieval accuracy, and the importance of controlling for these biases. Finally, as a way to mitigate the bias, we propose to learn a text representation that is invariant to political ideology while still judging topic relevance.
* To appear in The Proceedings of The 28th International Conference on
Computational Linguistics (COLING-2020)
View paper on