 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTribe or Not? Critical Inspection of Group Differences Using TribalGram
Mar 16, 2023

With the rise of AI and data mining techniques, group profiling and group-level analysis have been increasingly used in many domains including policy making and direct marketing. In some cases, the statistics extracted from data may provide insights to a group's shared characteristics; in others, the group-level analysis can lead to problems including stereotyping and systematic oppression. How can analytic tools facilitate a more conscientious process in group analysis? In this work, we identify a set of accountable group analytics design guidelines to explicate the needs for group differentiation and preventing overgeneralization of a group. Following the design guidelines, we develop TribalGram, a visual analytic suite that leverages interpretable machine learning algorithms and visualization to offer inference assessment, model explanation, data corroboration, and sense-making. Through the interviews with domain experts, we showcase how our design and tools can bring a richer understanding of "groups" mined from the data.
Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization
Dec 05, 2021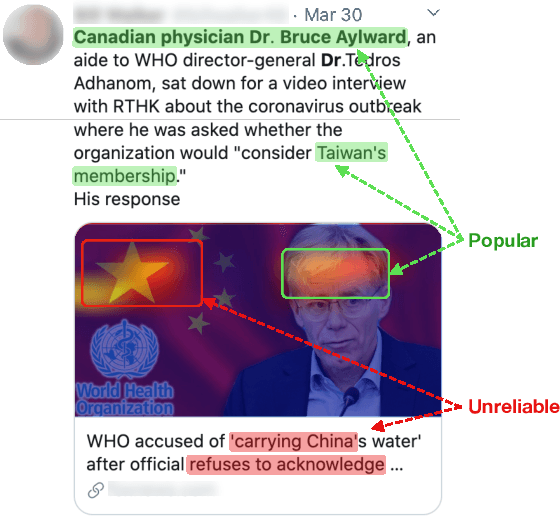
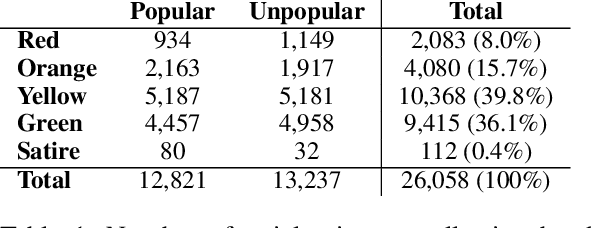


Social media content routinely incorporates multi-modal design to covey information and shape meanings, and sway interpretations toward desirable implications, but the choices and outcomes of using both texts and visual images have not been sufficiently studied. This work proposes a computational approach to analyze the outcome of persuasive information in multi-modal content, focusing on two aspects, popularity and reliability, in COVID-19-related news articles shared on Twitter. The two aspects are intertwined in the spread of misinformation: for example, an unreliable article that aims to misinform has to attain some popularity. This work has several contributions. First, we propose a multi-modal (image and text) approach to effectively identify popularity and reliability of information sources simultaneously. Second, we identify textual and visual elements that are predictive to information popularity and reliability. Third, by modeling cross-modal relations and similarity, we are able to uncover how unreliable articles construct multi-modal meaning in a distorted, biased fashion. Our work demonstrates how to use multi-modal analysis for understanding influential content and has implications to social media literacy and engagement.
Inflating Topic Relevance with Ideology: A Case Study of Political Ideology Bias in Social Topic Detection Models
Nov 29, 2020
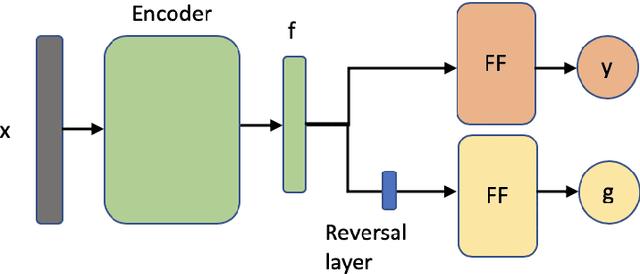
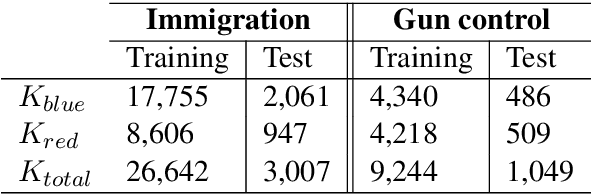
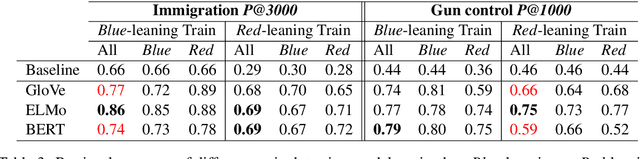
We investigate the impact of political ideology biases in training data. Through a set of comparison studies, we examine the propagation of biases in several widely-used NLP models and its effect on the overall retrieval accuracy. Our work highlights the susceptibility of large, complex models to propagating the biases from human-selected input, which may lead to a deterioration of retrieval accuracy, and the importance of controlling for these biases. Finally, as a way to mitigate the bias, we propose to learn a text representation that is invariant to political ideology while still judging topic relevance.