 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised HOI Detection from Interaction Labels Only and Language/Vision-Language Priors
Mar 09, 2023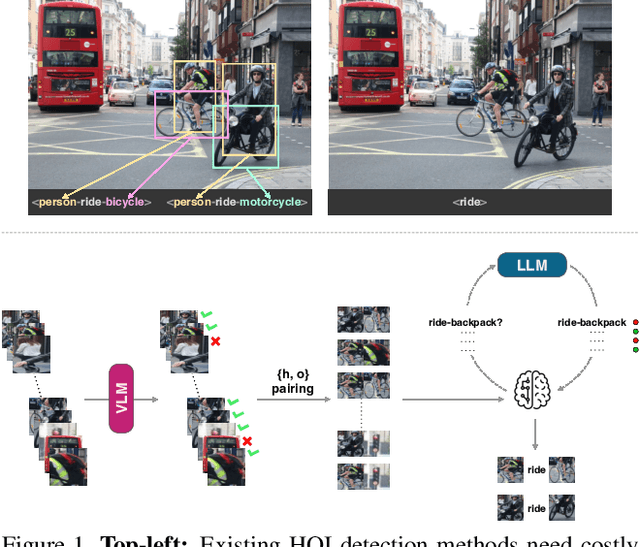
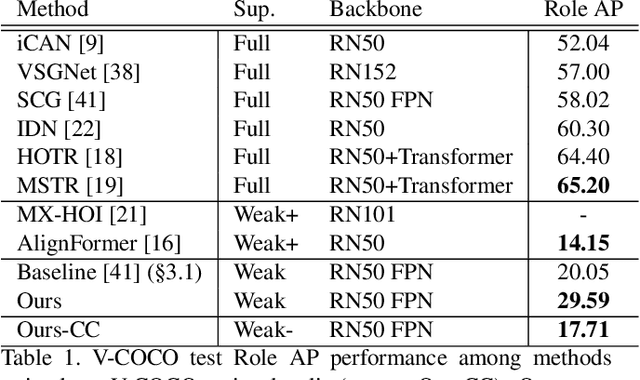
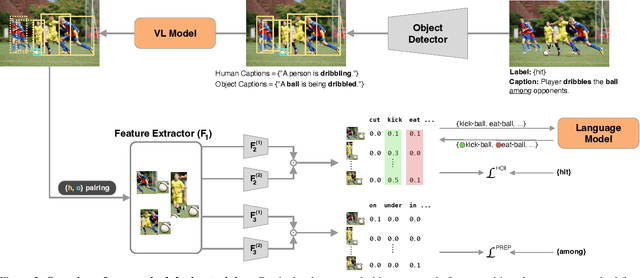
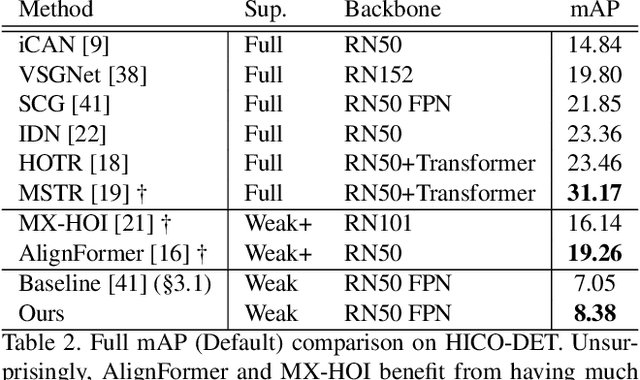
Human-object interaction (HOI) detection aims to extract interacting human-object pairs and their interaction categories from a given natural image. Even though the labeling effort required for building HOI detection datasets is inherently more extensive than for many other computer vision tasks, weakly-supervised directions in this area have not been sufficiently explored due to the difficulty of learning human-object interactions with weak supervision, rooted in the combinatorial nature of interactions over the object and predicate space. In this paper, we tackle HOI detection with the weakest supervision setting in the literature, using only image-level interaction labels, with the help of a pretrained vision-language model (VLM) and a large language model (LLM). We first propose an approach to prune non-interacting human and object proposals to increase the quality of positive pairs within the bag, exploiting the grounding capability of the vision-language model. Second, we use a large language model to query which interactions are possible between a human and a given object category, in order to force the model not to put emphasis on unlikely interactions. Lastly, we use an auxiliary weakly-supervised preposition prediction task to make our model explicitly reason about space. Extensive experiments and ablations show that all of our contributions increase HOI detection performance.
Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization
Dec 05, 2021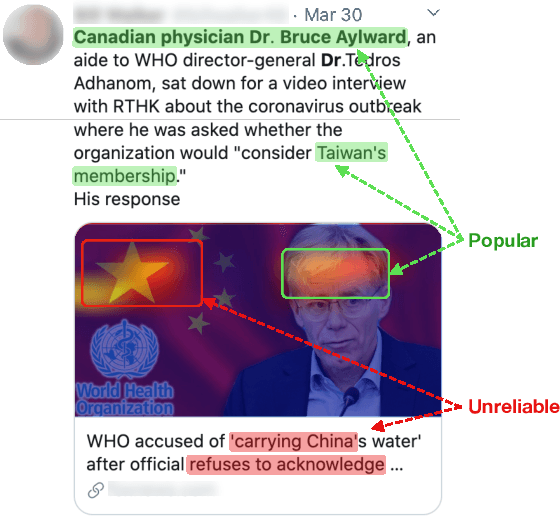
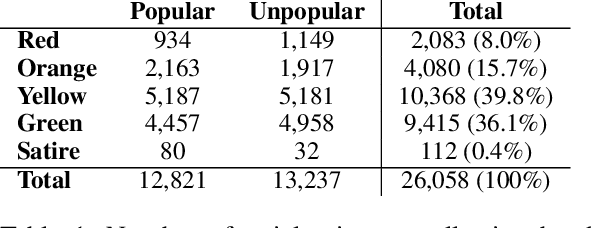


Social media content routinely incorporates multi-modal design to covey information and shape meanings, and sway interpretations toward desirable implications, but the choices and outcomes of using both texts and visual images have not been sufficiently studied. This work proposes a computational approach to analyze the outcome of persuasive information in multi-modal content, focusing on two aspects, popularity and reliability, in COVID-19-related news articles shared on Twitter. The two aspects are intertwined in the spread of misinformation: for example, an unreliable article that aims to misinform has to attain some popularity. This work has several contributions. First, we propose a multi-modal (image and text) approach to effectively identify popularity and reliability of information sources simultaneously. Second, we identify textual and visual elements that are predictive to information popularity and reliability. Third, by modeling cross-modal relations and similarity, we are able to uncover how unreliable articles construct multi-modal meaning in a distorted, biased fashion. Our work demonstrates how to use multi-modal analysis for understanding influential content and has implications to social media literacy and engagement.