 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-paradox Tree: Breaking Down Simpson's Paradox via A Kernel-Based Partition Algorithm
Mar 02, 2026Real-world observational datasets and machine learning have revolutionized data-driven decision-making, yet many models rely on empirical associations that may be misleading due to confounding and subgroup heterogeneity. Simpson's paradox exemplifies this challenge, where aggregated and subgroup-level associations contradict each other, leading to misleading conclusions. Existing methods provide limited support for detecting and interpreting such paradoxical associations, especially for practitioners without deep causal expertise. We introduce De-paradox Tree, an interpretable algorithm designed to uncover hidden subgroup patterns behind paradoxical associations under assumed causal structures involving confounders and effect heterogeneity. It employs novel split criteria and balancing-based procedures to adjust for confounders and homogenize heterogeneous effects through recursive partitioning. Compared to state-of-the-art methods, De-paradox Tree builds simpler, more interpretable trees, selects relevant covariates, and identifies nested opposite effects while ensuring robust estimation of causal effects when causally admissible variables are provided. Our approach addresses the limitations of traditional causal inference and machine learning methods by introducing an interpretable framework that supports non-expert practitioners while explicitly acknowledging causal assumptions and scope limitations, enabling more reliable and informed decision-making in complex observational data environments.
GenAI vs. Human Fact-Checkers: Accurate Ratings, Flawed Rationales
Feb 20, 2025


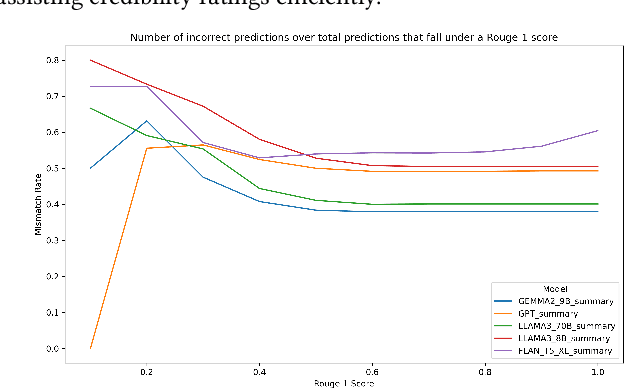
Despite recent advances in understanding the capabilities and limits of generative artificial intelligence (GenAI) models, we are just beginning to understand their capacity to assess and reason about the veracity of content. We evaluate multiple GenAI models across tasks that involve the rating of, and perceived reasoning about, the credibility of information. The information in our experiments comes from content that subnational U.S. politicians post to Facebook. We find that GPT-4o, one of the most used AI models in consumer applications, outperforms other models, but all models exhibit only moderate agreement with human coders. Importantly, even when GenAI models accurately identify low-credibility content, their reasoning relies heavily on linguistic features and ``hard'' criteria, such as the level of detail, source reliability, and language formality, rather than an understanding of veracity. We also assess the effectiveness of summarized versus full content inputs, finding that summarized content holds promise for improving efficiency without sacrificing accuracy. While GenAI has the potential to support human fact-checkers in scaling misinformation detection, our results caution against relying solely on these models.
Interactive Counterfactual Exploration of Algorithmic Harms in Recommender Systems
Sep 10, 2024


Recommender systems have become integral to digital experiences, shaping user interactions and preferences across various platforms. Despite their widespread use, these systems often suffer from algorithmic biases that can lead to unfair and unsatisfactory user experiences. This study introduces an interactive tool designed to help users comprehend and explore the impacts of algorithmic harms in recommender systems. By leveraging visualizations, counterfactual explanations, and interactive modules, the tool allows users to investigate how biases such as miscalibration, stereotypes, and filter bubbles affect their recommendations. Informed by in-depth user interviews, this tool benefits both general users and researchers by increasing transparency and offering personalized impact assessments, ultimately fostering a better understanding of algorithmic biases and contributing to more equitable recommendation outcomes. This work provides valuable insights for future research and practical applications in mitigating bias and enhancing fairness in machine learning algorithms.
Classifying Conspiratorial Narratives At Scale: False Alarms and Erroneous Connections
Mar 29, 2024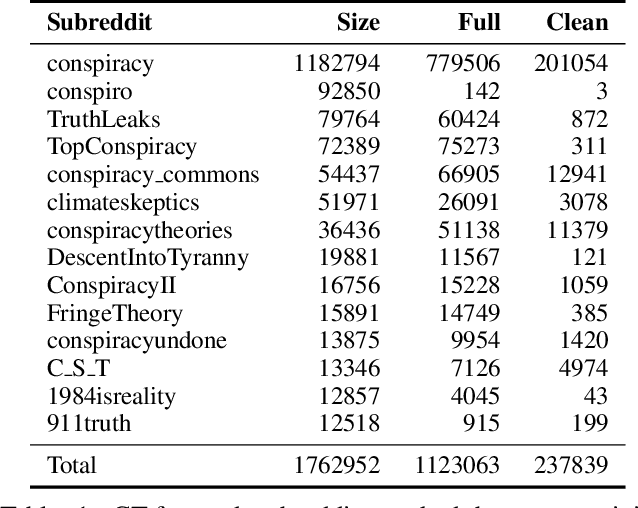
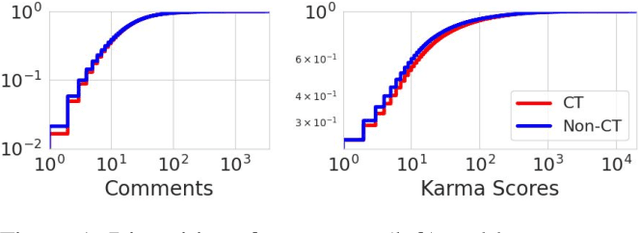
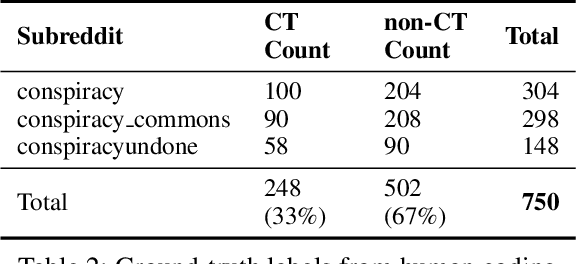
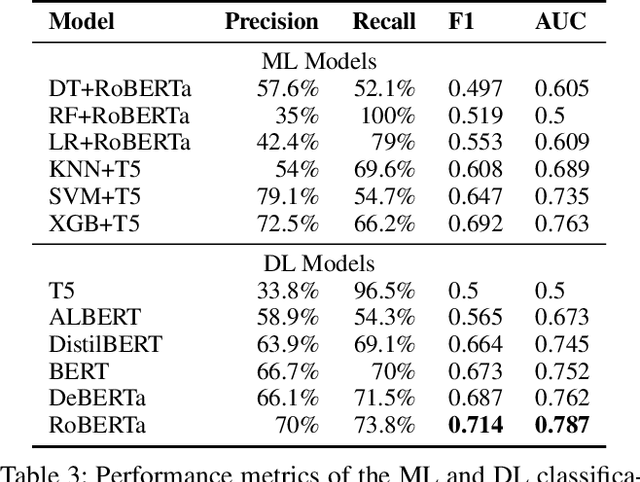
Online discussions frequently involve conspiracy theories, which can contribute to the proliferation of belief in them. However, not all discussions surrounding conspiracy theories promote them, as some are intended to debunk them. Existing research has relied on simple proxies or focused on a constrained set of signals to identify conspiracy theories, which limits our understanding of conspiratorial discussions across different topics and online communities. This work establishes a general scheme for classifying discussions related to conspiracy theories based on authors' perspectives on the conspiracy belief, which can be expressed explicitly through narrative elements, such as the agent, action, or objective, or implicitly through references to known theories, such as chemtrails or the New World Order. We leverage human-labeled ground truth to train a BERT-based model for classifying online CTs, which we then compared to the Generative Pre-trained Transformer machine (GPT) for detecting online conspiratorial content. Despite GPT's known strengths in its expressiveness and contextual understanding, our study revealed significant flaws in its logical reasoning, while also demonstrating comparable strengths from our classifiers. We present the first large-scale classification study using posts from the most active conspiracy-related Reddit forums and find that only one-third of the posts are classified as positive. This research sheds light on the potential applications of large language models in tasks demanding nuanced contextual comprehension.
Break Out of a Pigeonhole: A Unified Framework for Examining Miscalibration, Bias, and Stereotype in Recommender Systems
Dec 29, 2023
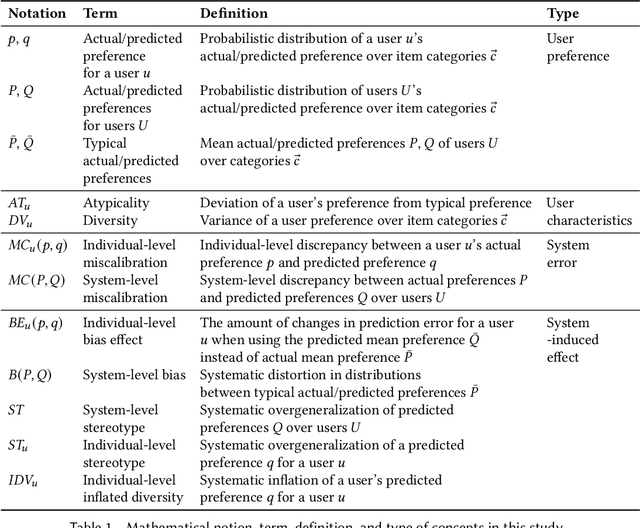
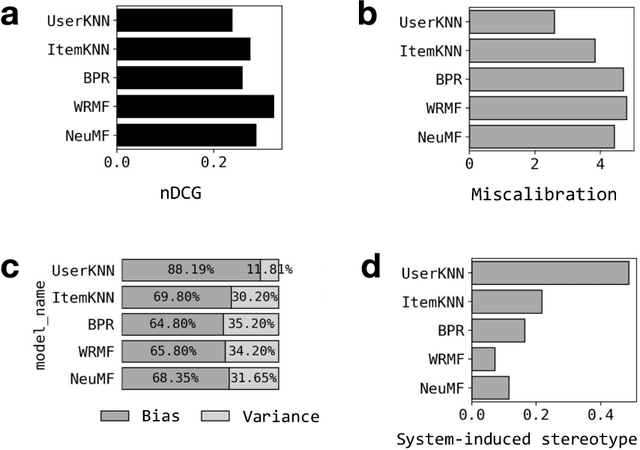
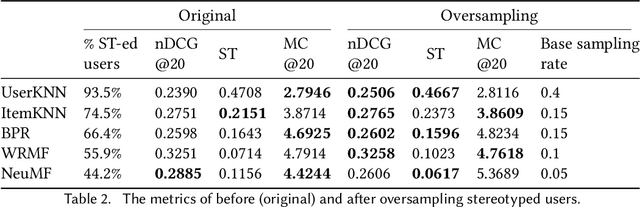
Despite the benefits of personalizing items and information tailored to users' needs, it has been found that recommender systems tend to introduce biases that favor popular items or certain categories of items, and dominant user groups. In this study, we aim to characterize the systematic errors of a recommendation system and how they manifest in various accountability issues, such as stereotypes, biases, and miscalibration. We propose a unified framework that distinguishes the sources of prediction errors into a set of key measures that quantify the various types of system-induced effects, both at the individual and collective levels. Based on our measuring framework, we examine the most widely adopted algorithms in the context of movie recommendation. Our research reveals three important findings: (1) Differences between algorithms: recommendations generated by simpler algorithms tend to be more stereotypical but less biased than those generated by more complex algorithms. (2) Disparate impact on groups and individuals: system-induced biases and stereotypes have a disproportionate effect on atypical users and minority groups (e.g., women and older users). (3) Mitigation opportunity: using structural equation modeling, we identify the interactions between user characteristics (typicality and diversity), system-induced effects, and miscalibration. We further investigate the possibility of mitigating system-induced effects by oversampling underrepresented groups and individuals, which was found to be effective in reducing stereotypes and improving recommendation quality. Our research is the first systematic examination of not only system-induced effects and miscalibration but also the stereotyping issue in recommender systems.
HungerGist: An Interpretable Predictive Model for Food Insecurity
Nov 18, 2023



The escalating food insecurity in Africa, caused by factors such as war, climate change, and poverty, demonstrates the critical need for advanced early warning systems. Traditional methodologies, relying on expert-curated data encompassing climate, geography, and social disturbances, often fall short due to data limitations, hindering comprehensive analysis and potential discovery of new predictive factors. To address this, this paper introduces "HungerGist", a multi-task deep learning model utilizing news texts and NLP techniques. Using a corpus of over 53,000 news articles from nine African countries over four years, we demonstrate that our model, trained solely on news data, outperforms the baseline method trained on both traditional risk factors and human-curated keywords. In addition, our method has the ability to detect critical texts that contain interpretable signals known as "gists." Moreover, our examination of these gists indicates that this approach has the potential to reveal latent factors that would otherwise remain concealed in unstructured texts.
VISPUR: Visual Aids for Identifying and Interpreting Spurious Associations in Data-Driven Decisions
Jul 26, 2023Big data and machine learning tools have jointly empowered humans in making data-driven decisions. However, many of them capture empirical associations that might be spurious due to confounding factors and subgroup heterogeneity. The famous Simpson's paradox is such a phenomenon where aggregated and subgroup-level associations contradict with each other, causing cognitive confusions and difficulty in making adequate interpretations and decisions. Existing tools provide little insights for humans to locate, reason about, and prevent pitfalls of spurious association in practice. We propose VISPUR, a visual analytic system that provides a causal analysis framework and a human-centric workflow for tackling spurious associations. These include a CONFOUNDER DASHBOARD, which can automatically identify possible confounding factors, and a SUBGROUP VIEWER, which allows for the visualization and comparison of diverse subgroup patterns that likely or potentially result in a misinterpretation of causality. Additionally, we propose a REASONING STORYBOARD, which uses a flow-based approach to illustrate paradoxical phenomena, as well as an interactive DECISION DIAGNOSIS panel that helps ensure accountable decision-making. Through an expert interview and a controlled user experiment, our qualitative and quantitative results demonstrate that the proposed "de-paradox" workflow and the designed visual analytic system are effective in helping human users to identify and understand spurious associations, as well as to make accountable causal decisions.
Tribe or Not? Critical Inspection of Group Differences Using TribalGram
Mar 16, 2023

With the rise of AI and data mining techniques, group profiling and group-level analysis have been increasingly used in many domains including policy making and direct marketing. In some cases, the statistics extracted from data may provide insights to a group's shared characteristics; in others, the group-level analysis can lead to problems including stereotyping and systematic oppression. How can analytic tools facilitate a more conscientious process in group analysis? In this work, we identify a set of accountable group analytics design guidelines to explicate the needs for group differentiation and preventing overgeneralization of a group. Following the design guidelines, we develop TribalGram, a visual analytic suite that leverages interpretable machine learning algorithms and visualization to offer inference assessment, model explanation, data corroboration, and sense-making. Through the interviews with domain experts, we showcase how our design and tools can bring a richer understanding of "groups" mined from the data.
ESCAPE: Countering Systematic Errors from Machine's Blind Spots via Interactive Visual Analysis
Mar 16, 2023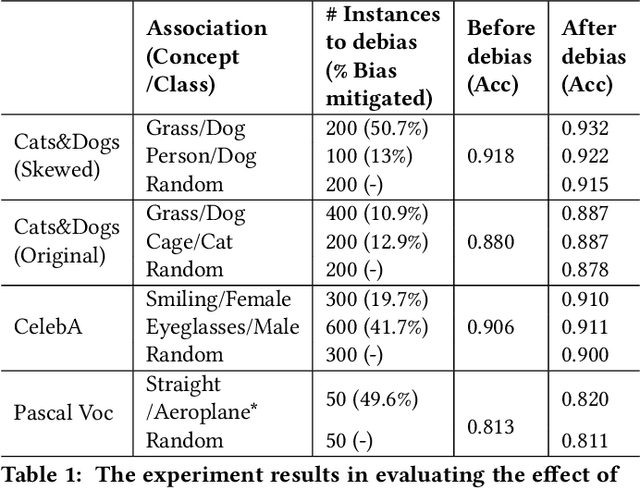
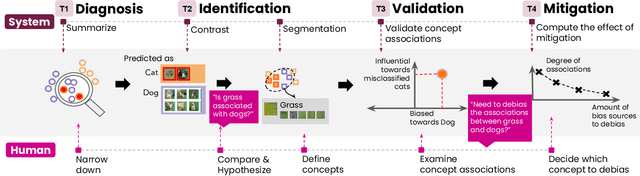
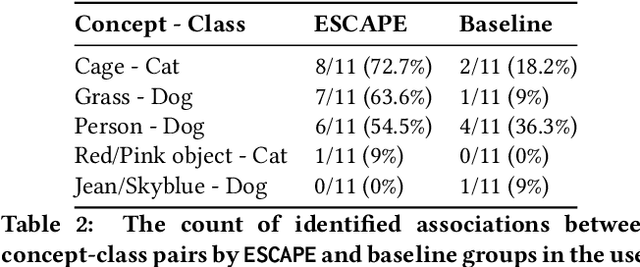
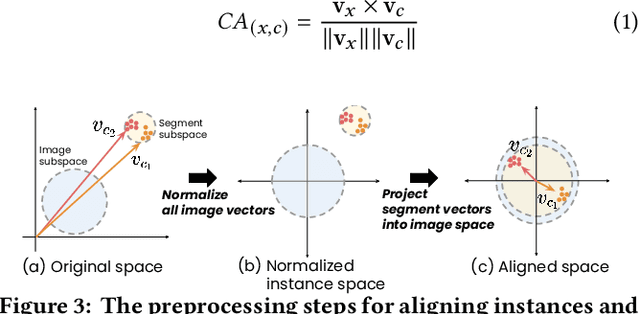
Classification models learn to generalize the associations between data samples and their target classes. However, researchers have increasingly observed that machine learning practice easily leads to systematic errors in AI applications, a phenomenon referred to as AI blindspots. Such blindspots arise when a model is trained with training samples (e.g., cat/dog classification) where important patterns (e.g., black cats) are missing or periphery/undesirable patterns (e.g., dogs with grass background) are misleading towards a certain class. Even more sophisticated techniques cannot guarantee to capture, reason about, and prevent the spurious associations. In this work, we propose ESCAPE, a visual analytic system that promotes a human-in-the-loop workflow for countering systematic errors. By allowing human users to easily inspect spurious associations, the system facilitates users to spontaneously recognize concepts associated misclassifications and evaluate mitigation strategies that can reduce biased associations. We also propose two statistical approaches, relative concept association to better quantify the associations between a concept and instances, and debias method to mitigate spurious associations. We demonstrate the utility of our proposed ESCAPE system and statistical measures through extensive evaluation including quantitative experiments, usage scenarios, expert interviews, and controlled user experiments.
Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization
Dec 05, 2021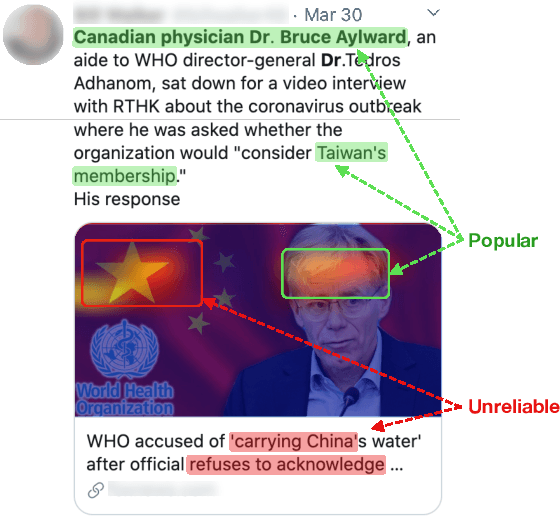
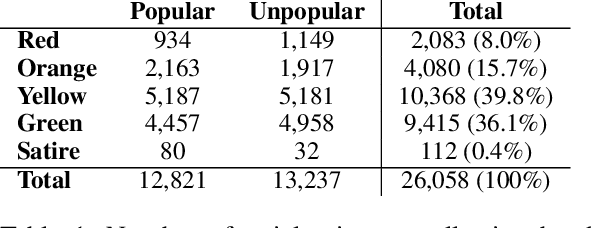


Social media content routinely incorporates multi-modal design to covey information and shape meanings, and sway interpretations toward desirable implications, but the choices and outcomes of using both texts and visual images have not been sufficiently studied. This work proposes a computational approach to analyze the outcome of persuasive information in multi-modal content, focusing on two aspects, popularity and reliability, in COVID-19-related news articles shared on Twitter. The two aspects are intertwined in the spread of misinformation: for example, an unreliable article that aims to misinform has to attain some popularity. This work has several contributions. First, we propose a multi-modal (image and text) approach to effectively identify popularity and reliability of information sources simultaneously. Second, we identify textual and visual elements that are predictive to information popularity and reliability. Third, by modeling cross-modal relations and similarity, we are able to uncover how unreliable articles construct multi-modal meaning in a distorted, biased fashion. Our work demonstrates how to use multi-modal analysis for understanding influential content and has implications to social media literacy and engagement.