 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Conspiratorial Narratives At Scale: False Alarms and Erroneous Connections
Mar 29, 2024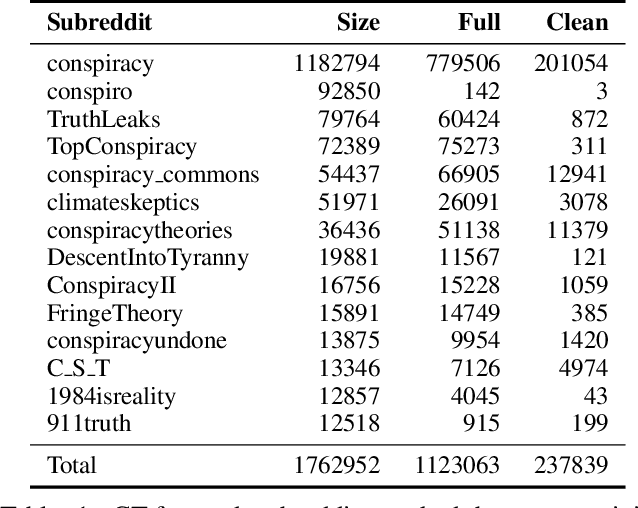
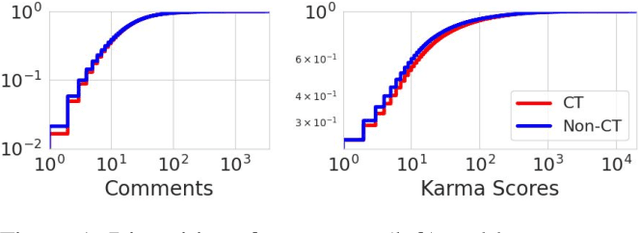
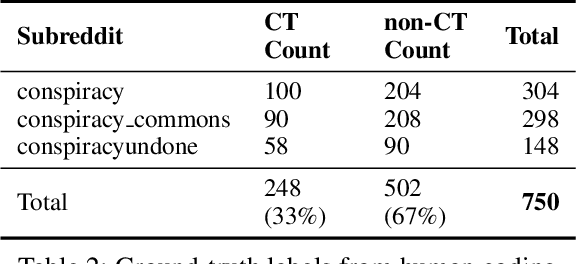
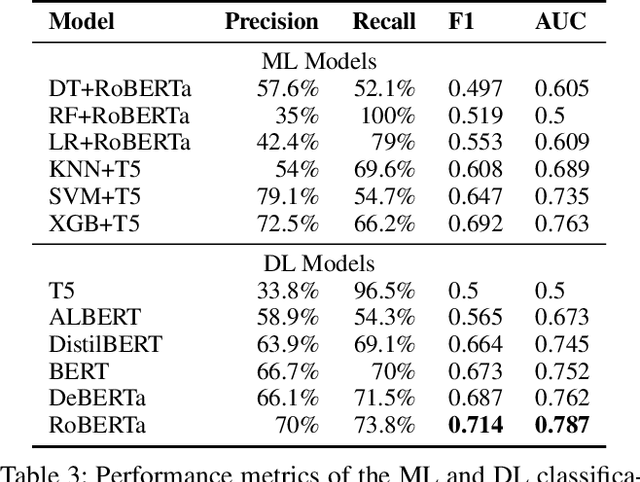
Online discussions frequently involve conspiracy theories, which can contribute to the proliferation of belief in them. However, not all discussions surrounding conspiracy theories promote them, as some are intended to debunk them. Existing research has relied on simple proxies or focused on a constrained set of signals to identify conspiracy theories, which limits our understanding of conspiratorial discussions across different topics and online communities. This work establishes a general scheme for classifying discussions related to conspiracy theories based on authors' perspectives on the conspiracy belief, which can be expressed explicitly through narrative elements, such as the agent, action, or objective, or implicitly through references to known theories, such as chemtrails or the New World Order. We leverage human-labeled ground truth to train a BERT-based model for classifying online CTs, which we then compared to the Generative Pre-trained Transformer machine (GPT) for detecting online conspiratorial content. Despite GPT's known strengths in its expressiveness and contextual understanding, our study revealed significant flaws in its logical reasoning, while also demonstrating comparable strengths from our classifiers. We present the first large-scale classification study using posts from the most active conspiracy-related Reddit forums and find that only one-third of the posts are classified as positive. This research sheds light on the potential applications of large language models in tasks demanding nuanced contextual comprehension.
A Weakly Supervised Classifier and Dataset of White Supremacist Language
Jun 27, 2023



We present a dataset and classifier for detecting the language of white supremacist extremism, a growing issue in online hate speech. Our weakly supervised classifier is trained on large datasets of text from explicitly white supremacist domains paired with neutral and anti-racist data from similar domains. We demonstrate that this approach improves generalization performance to new domains. Incorporating anti-racist texts as counterexamples to white supremacist language mitigates bias.
Domain-robust VQA with diverse datasets and methods but no target labels
Mar 29, 2021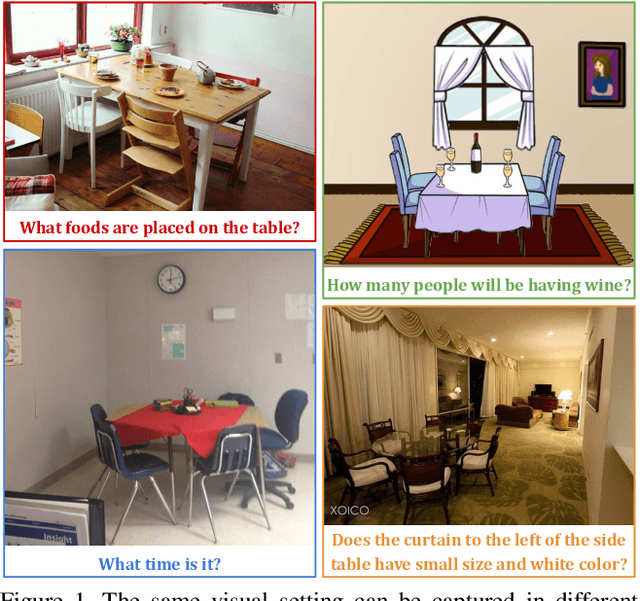


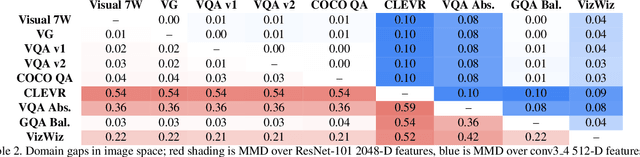
The observation that computer vision methods overfit to dataset specifics has inspired diverse attempts to make object recognition models robust to domain shifts. However, similar work on domain-robust visual question answering methods is very limited. Domain adaptation for VQA differs from adaptation for object recognition due to additional complexity: VQA models handle multimodal inputs, methods contain multiple steps with diverse modules resulting in complex optimization, and answer spaces in different datasets are vastly different. To tackle these challenges, we first quantify domain shifts between popular VQA datasets, in both visual and textual space. To disentangle shifts between datasets arising from different modalities, we also construct synthetic shifts in the image and question domains separately. Second, we test the robustness of different families of VQA methods (classic two-stream, transformer, and neuro-symbolic methods) to these shifts. Third, we test the applicability of existing domain adaptation methods and devise a new one to bridge VQA domain gaps, adjusted to specific VQA models. To emulate the setting of real-world generalization, we focus on unsupervised domain adaptation and the open-ended classification task formulation.
Darknet and Deepnet Mining for Proactive Cybersecurity Threat Intelligence
Jul 28, 2016
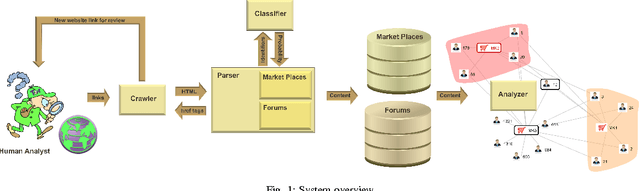
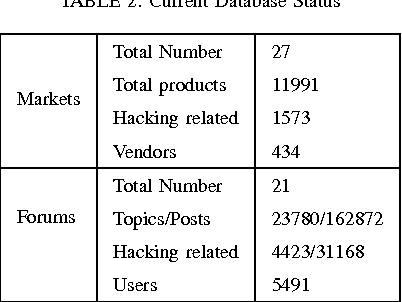
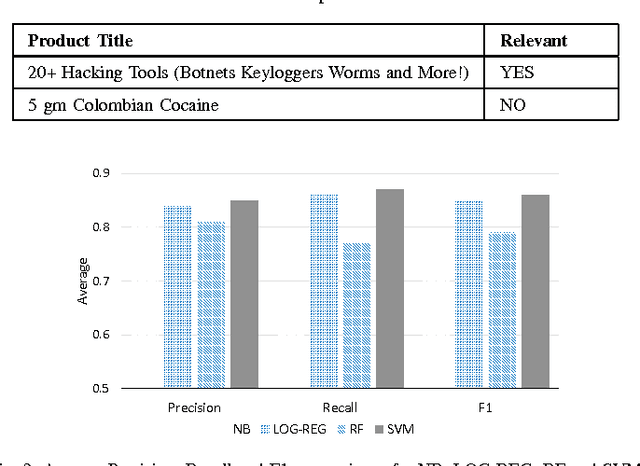
In this paper, we present an operational system for cyber threat intelligence gathering from various social platforms on the Internet particularly sites on the darknet and deepnet. We focus our attention to collecting information from hacker forum discussions and marketplaces offering products and services focusing on malicious hacking. We have developed an operational system for obtaining information from these sites for the purposes of identifying emerging cyber threats. Currently, this system collects on average 305 high-quality cyber threat warnings each week. These threat warnings include information on newly developed malware and exploits that have not yet been deployed in a cyber-attack. This provides a significant service to cyber-defenders. The system is significantly augmented through the use of various data mining and machine learning techniques. With the use of machine learning models, we are able to recall 92% of products in marketplaces and 80% of discussions on forums relating to malicious hacking with high precision. We perform preliminary analysis on the data collected, demonstrating its application to aid a security expert for better threat analysis.
Product Offerings in Malicious Hacker Markets
Jul 26, 2016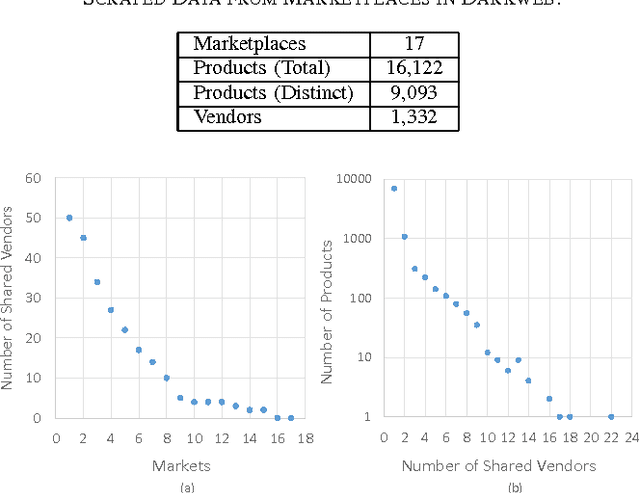


Marketplaces specializing in malicious hacking products - including malware and exploits - have recently become more prominent on the darkweb and deepweb. We scrape 17 such sites and collect information about such products in a unified database schema. Using a combination of manual labeling and unsupervised clustering, we examine a corpus of products in order to understand their various categories and how they become specialized with respect to vendor and marketplace. This initial study presents how we effectively employed unsupervised techniques to this data as well as the types of insights we gained on various categories of malicious hacking products.