 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025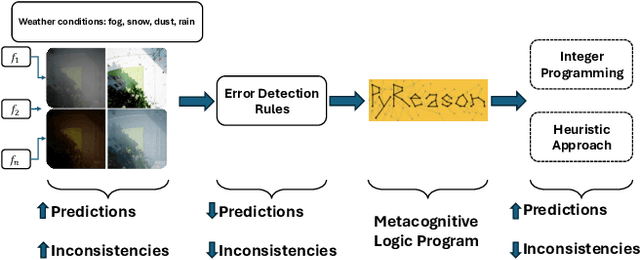
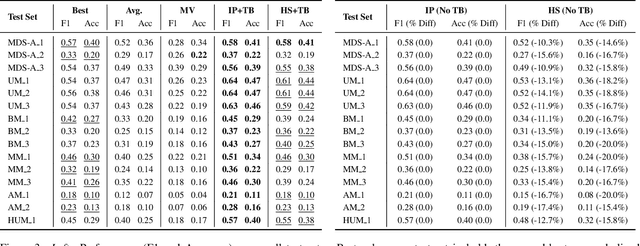
The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
VLC Fusion: Vision-Language Conditioned Sensor Fusion for Robust Object Detection
May 19, 2025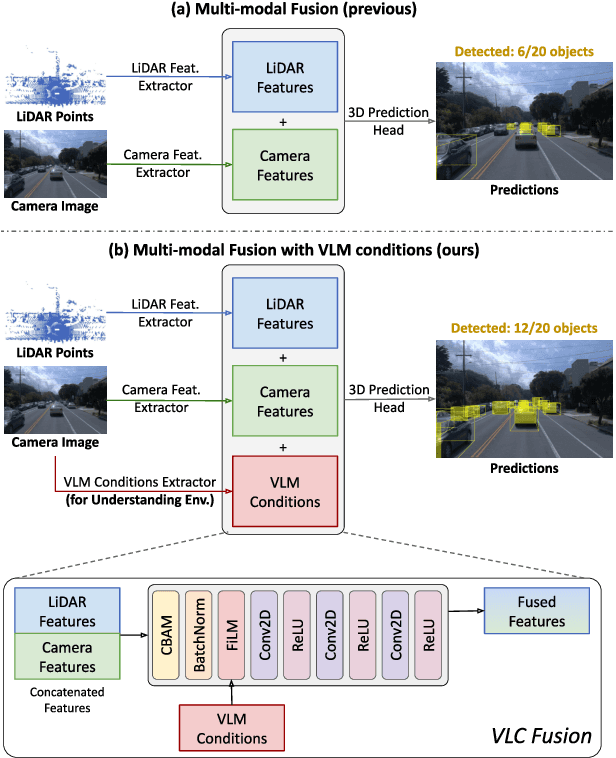
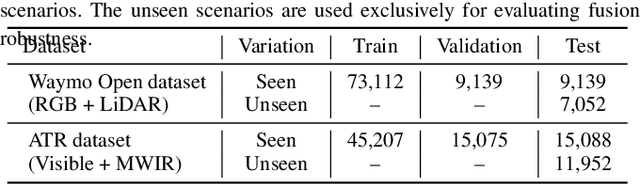

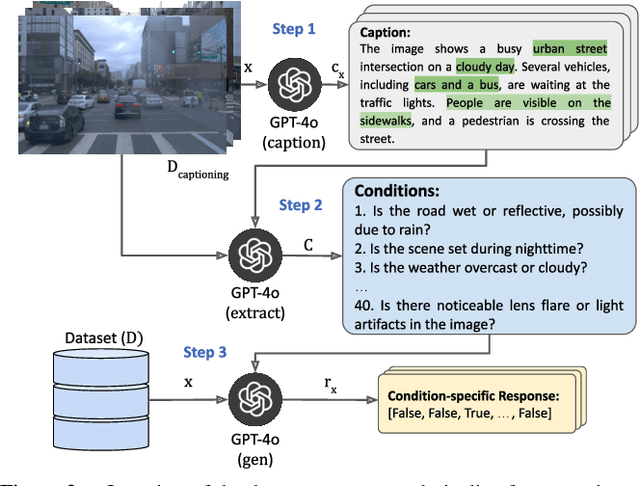
Although fusing multiple sensor modalities can enhance object detection performance, existing fusion approaches often overlook subtle variations in environmental conditions and sensor inputs. As a result, they struggle to adaptively weight each modality under such variations. To address this challenge, we introduce Vision-Language Conditioned Fusion (VLC Fusion), a novel fusion framework that leverages a Vision-Language Model (VLM) to condition the fusion process on nuanced environmental cues. By capturing high-level environmental context such as as darkness, rain, and camera blurring, the VLM guides the model to dynamically adjust modality weights based on the current scene. We evaluate VLC Fusion on real-world autonomous driving and military target detection datasets that include image, LIDAR, and mid-wave infrared modalities. Our experiments show that VLC Fusion consistently outperforms conventional fusion baselines, achieving improved detection accuracy in both seen and unseen scenarios.
A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models
Feb 18, 2025



Deep Reinforcement Learning (RL) has been explored and verified to be effective in solving decision-making tasks in various domains, such as robotics, transportation, recommender systems, etc. It learns from the interaction with environments and updates the policy using the collected experience. However, due to the limited real-world data and unbearable consequences of taking detrimental actions, the learning of RL policy is mainly restricted within the simulators. This practice guarantees safety in learning but introduces an inevitable sim-to-real gap in terms of deployment, thus causing degraded performance and risks in execution. There are attempts to solve the sim-to-real problems from different domains with various techniques, especially in the era with emerging techniques such as large foundations or language models that have cast light on the sim-to-real. This survey paper, to the best of our knowledge, is the first taxonomy that formally frames the sim-to-real techniques from key elements of the Markov Decision Process (State, Action, Transition, and Reward). Based on the framework, we cover comprehensive literature from the classic to the most advanced methods including the sim-to-real techniques empowered by foundation models, and we also discuss the specialties that are worth attention in different domains of sim-to-real problems. Then we summarize the formal evaluation process of sim-to-real performance with accessible code or benchmarks. The challenges and opportunities are also presented to encourage future exploration of this direction. We are actively maintaining a to include the most up-to-date sim-to-real research outcomes to help the researchers in their work.
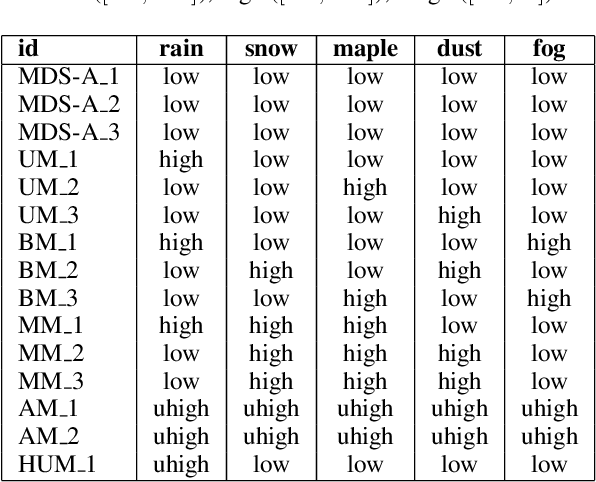
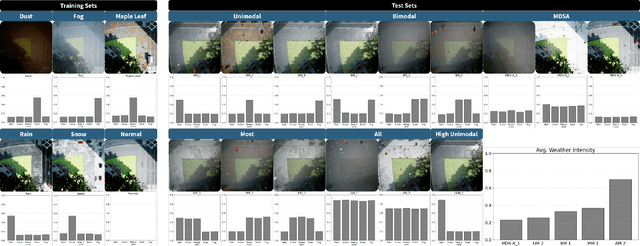
Multiple Distribution Shift -- Aerial (MDS-A): A Dataset for Test-Time Error Detection and Model Adaptation
Feb 18, 2025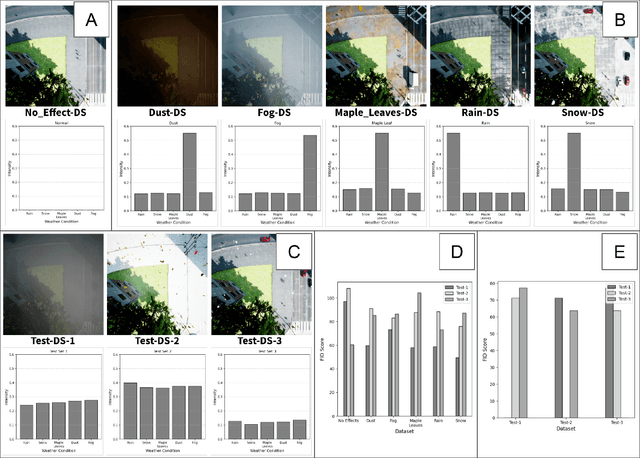
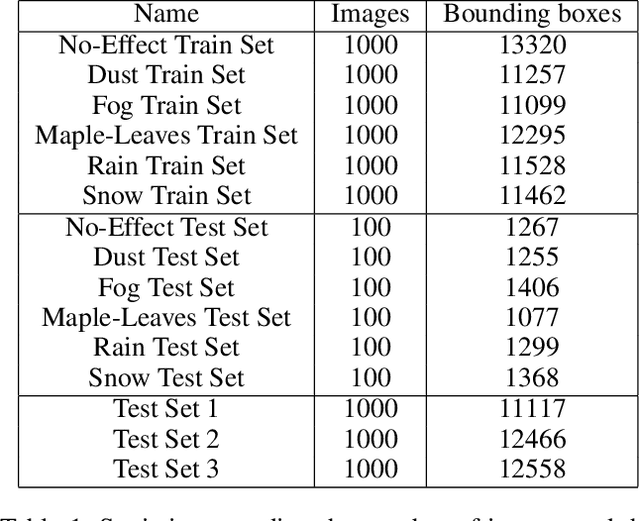

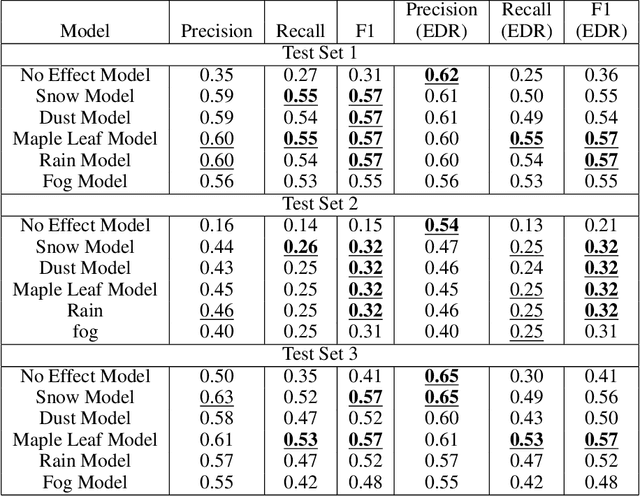
Machine learning models assume that training and test samples are drawn from the same distribution. As such, significant differences between training and test distributions often lead to degradations in performance. We introduce Multiple Distribution Shift -- Aerial (MDS-A) -- a collection of inter-related datasets of the same aerial domain that are perturbed in different ways to better characterize the effects of out-of-distribution performance. Specifically, MDS-A is a set of simulated aerial datasets collected under different weather conditions. We include six datasets under different simulated weather conditions along with six baseline object-detection models, as well as several test datasets that are a mix of weather conditions that we show have significant differences from the training data. In this paper, we present characterizations of MDS-A, provide performance results for the baseline machine learning models (on both their specific training datasets and the test data), as well as results of the baselines after employing recent knowledge-engineering error-detection techniques (EDR) thought to improve out-of-distribution performance. The dataset is available at https://lab-v2.github.io/mdsa-dataset-website.
Abduction of Domain Relationships from Data for VQA
Feb 13, 2025In this paper, we study the problem of visual question answering (VQA) where the image and query are represented by ASP programs that lack domain data. We provide an approach that is orthogonal and complementary to existing knowledge augmentation techniques where we abduce domain relationships of image constructs from past examples. After framing the abduction problem, we provide a baseline approach, and an implementation that significantly improves the accuracy of query answering yet requires few examples.
* In Proceedings ICLP 2024, arXiv:2502.08453
Probabilistic Foundations for Metacognition via Hybrid-AI
Feb 08, 2025Metacognition is the concept of reasoning about an agent's own internal processes, and it has recently received renewed attention with respect to artificial intelligence (AI) and, more specifically, machine learning systems. This paper reviews a hybrid-AI approach known as "error detecting and correcting rules" (EDCR) that allows for the learning of rules to correct perceptual (e.g., neural) models. Additionally, we introduce a probabilistic framework that adds rigor to prior empirical studies, and we use this framework to prove results on necessary and sufficient conditions for metacognitive improvement, as well as limits to the approach. A set of future
Sea-cret Agents: Maritime Abduction for Region Generation to Expose Dark Vessel Trajectories
Feb 03, 2025Bad actors in the maritime industry engage in illegal behaviors after disabling their vessel's automatic identification system (AIS) - which makes finding such vessels difficult for analysts. Machine learning approaches only succeed in identifying the locations of these ``dark vessels'' in the immediate future. This work leverages ideas from the literature on abductive inference applied to locating adversarial agents to solve the problem. Specifically, we combine concepts from abduction, logic programming, and rule learning to create an efficient method that approaches full recall of dark vessels while requiring less search area than machine learning methods. We provide a logic-based paradigm for reasoning about maritime vessels, an abductive inference query method, an automatically extracted rule-based behavior model methodology, and a thorough suite of experiments.
Metal Price Spike Prediction via a Neurosymbolic Ensemble Approach
Oct 16, 2024



Predicting price spikes in critical metals such as Cobalt, Copper, Magnesium, and Nickel is crucial for mitigating economic risks associated with global trends like the energy transition and reshoring of manufacturing. While traditional models have focused on regression-based approaches, our work introduces a neurosymbolic ensemble framework that integrates multiple neural models with symbolic error detection and correction rules. This framework is designed to enhance predictive accuracy by correcting individual model errors and offering interpretability through rule-based explanations. We show that our method provides up to 6.42% improvement in precision, 29.41% increase in recall at 13.24% increase in F1 over the best performing neural models. Further, our method, as it is based on logical rules, has the benefit of affording an explanation as to which combination of neural models directly contribute to a given prediction.
Error Detection and Constraint Recovery in Hierarchical Multi-Label Classification without Prior Knowledge
Jul 21, 2024
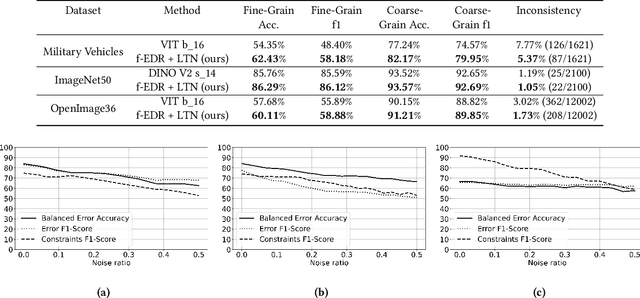
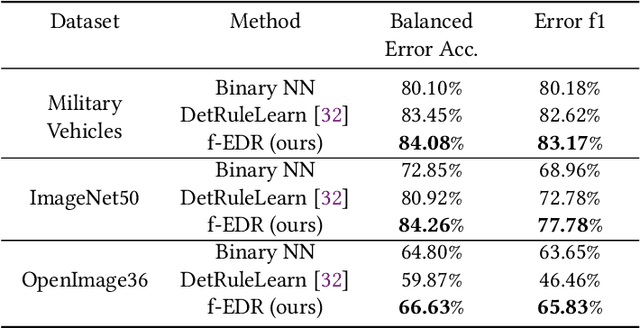
Recent advances in Hierarchical Multi-label Classification (HMC), particularly neurosymbolic-based approaches, have demonstrated improved consistency and accuracy by enforcing constraints on a neural model during training. However, such work assumes the existence of such constraints a-priori. In this paper, we relax this strong assumption and present an approach based on Error Detection Rules (EDR) that allow for learning explainable rules about the failure modes of machine learning models. We show that these rules are not only effective in detecting when a machine learning classifier has made an error but also can be leveraged as constraints for HMC, thereby allowing the recovery of explainable constraints even if they are not provided. We show that our approach is effective in detecting machine learning errors and recovering constraints, is noise tolerant, and can function as a source of knowledge for neurosymbolic models on multiple datasets, including a newly introduced military vehicle recognition dataset.
Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent Testing
Jul 08, 2024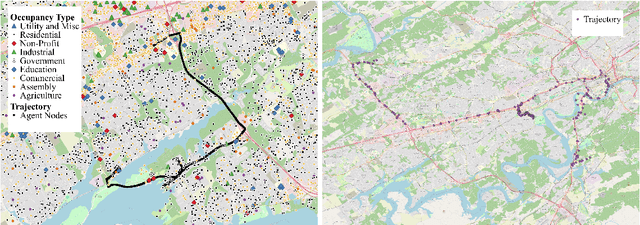

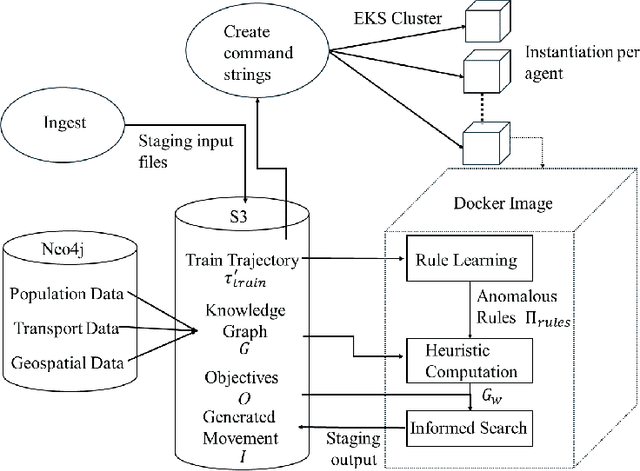
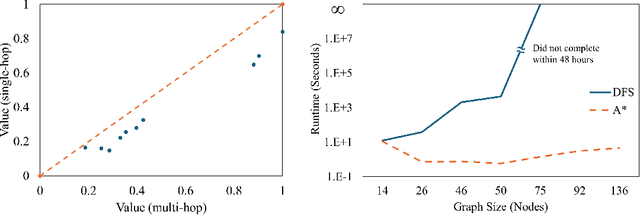
The ability to generate artificial human movement patterns while meeting location and time constraints is an important problem in the security community, particularly as it enables the study of the analog problem of detecting such patterns while maintaining privacy. We frame this problem as an instance of abduction guided by a novel parsimony function represented as an aggregate truth value over an annotated logic program. This approach has the added benefit of affording explainability to an analyst user. By showing that any subset of such a program can provide a lower bound on this parsimony requirement, we are able to abduce movement trajectories efficiently through an informed (i.e., A*) search. We describe how our implementation was enhanced with the application of multiple techniques in order to be scaled and integrated with a cloud-based software stack that included bottom-up rule learning, geolocated knowledge graph retrieval/management, and interfaces with government systems for independently conducted government-run tests for which we provide results. We also report on our own experiments showing that we not only provide exact results but also scale to very large scenarios and provide realistic agent trajectories that can go undetected by machine learning anomaly detectors.