 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Maximum Independent Sets in Dynamic Graphs using Unsupervised Learning
May 19, 2025We present the first unsupervised learning model for finding Maximum Independent Sets (MaxIS) in dynamic graphs where edges change over time. Our method combines structural learning from graph neural networks (GNNs) with a learned distributed update mechanism that, given an edge addition or deletion event, modifies nodes' internal memories and infers their MaxIS membership in a single, parallel step. We parameterize our model by the update mechanism's radius and investigate the resulting performance-runtime tradeoffs for various dynamic graph topologies. We evaluate our model against state-of-the-art MaxIS methods for static graphs, including a mixed integer programming solver, deterministic rule-based algorithms, and a heuristic learning framework based on dynamic programming and GNNs. Across synthetic and real-world dynamic graphs of 100-10,000 nodes, our model achieves competitive approximation ratios with excellent scalability; on large graphs, it significantly outperforms the state-of-the-art heuristic learning framework in solution quality, runtime, and memory usage. Our model generalizes well on graphs 100x larger than the ones used for training, achieving performance at par with both a greedy technique and a commercial mixed integer programming solver while running 1.5-23x faster than greedy.
Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent Testing
Jul 08, 2024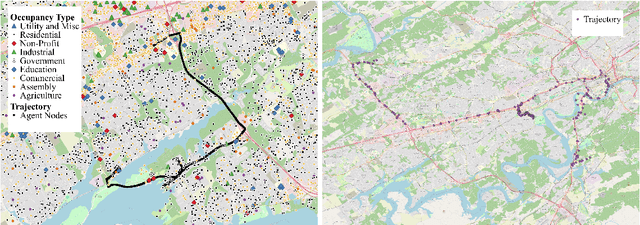

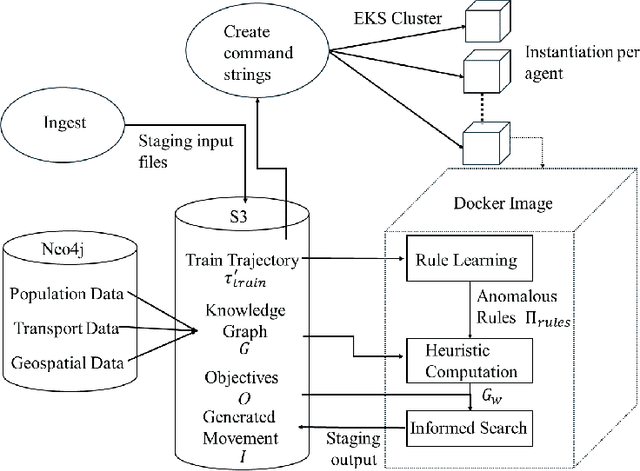
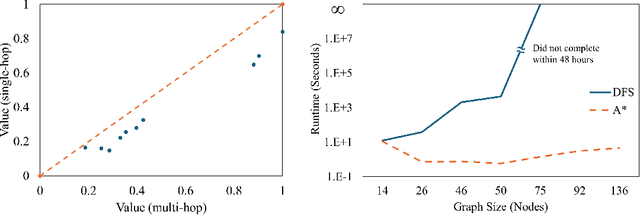
The ability to generate artificial human movement patterns while meeting location and time constraints is an important problem in the security community, particularly as it enables the study of the analog problem of detecting such patterns while maintaining privacy. We frame this problem as an instance of abduction guided by a novel parsimony function represented as an aggregate truth value over an annotated logic program. This approach has the added benefit of affording explainability to an analyst user. By showing that any subset of such a program can provide a lower bound on this parsimony requirement, we are able to abduce movement trajectories efficiently through an informed (i.e., A*) search. We describe how our implementation was enhanced with the application of multiple techniques in order to be scaled and integrated with a cloud-based software stack that included bottom-up rule learning, geolocated knowledge graph retrieval/management, and interfaces with government systems for independently conducted government-run tests for which we provide results. We also report on our own experiments showing that we not only provide exact results but also scale to very large scenarios and provide realistic agent trajectories that can go undetected by machine learning anomaly detectors.
Evolving Collective Behavior in Self-Organizing Particle Systems
Apr 09, 2024

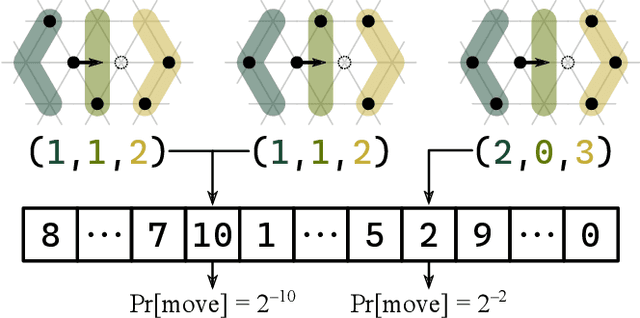

Local interactions drive emergent collective behavior, which pervades biological and social complex systems. But uncovering the interactions that produce a desired behavior remains a core challenge. In this paper, we present EvoSOPS, an evolutionary framework that searches landscapes of stochastic distributed algorithms for those that achieve a mathematically specified target behavior. These algorithms govern self-organizing particle systems (SOPS) comprising individuals with no persistent memory and strictly local sensing and movement. For aggregation, phototaxing, and separation behaviors, EvoSOPS discovers algorithms that achieve 4.2-15.3% higher fitness than those from the existing "stochastic approach to SOPS" based on mathematical theory from statistical physics. EvoSOPS is also flexibly applied to new behaviors such as object coating where the stochastic approach would require bespoke, extensive analysis. Finally, we distill insights from the diverse, best-fitness genomes produced for aggregation across repeated EvoSOPS runs to demonstrate how EvoSOPS can bootstrap future theoretical investigations into SOPS algorithms for new behaviors.
Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning
Oct 15, 2023
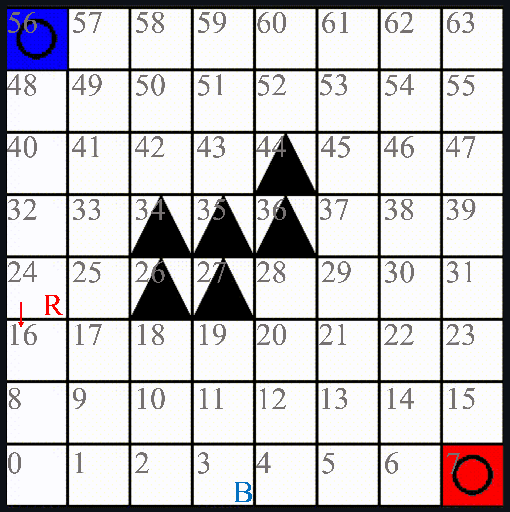
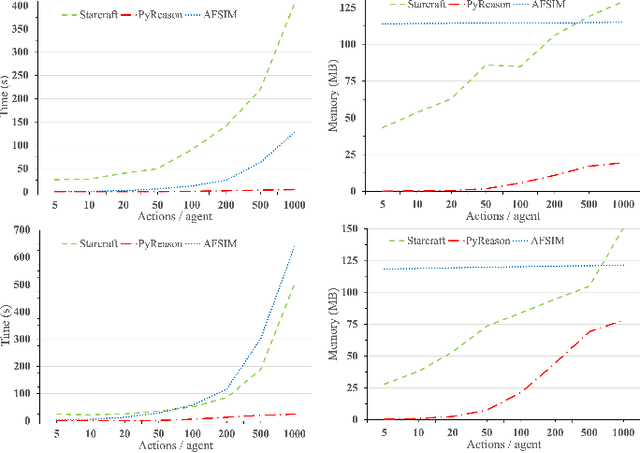
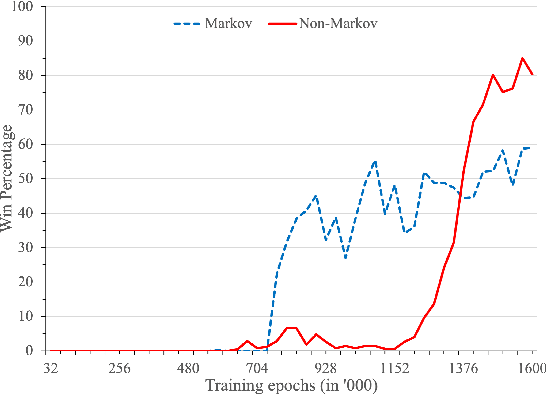
Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned. In addition, we show the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.