 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning
Oct 15, 2023
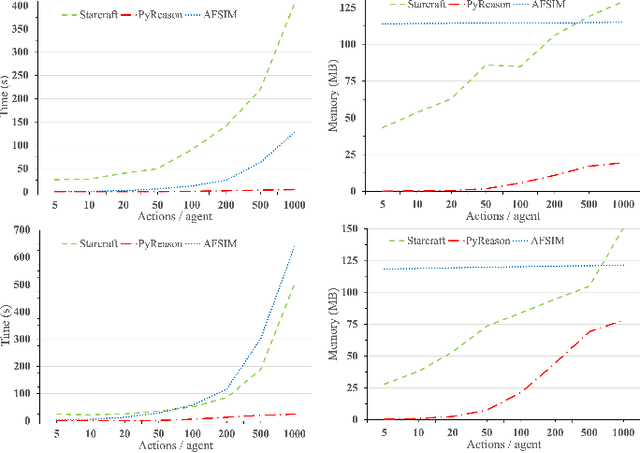
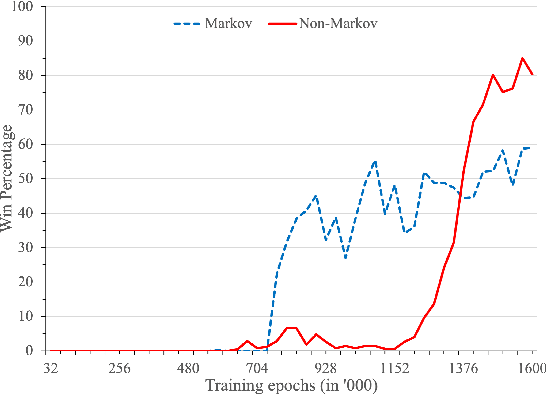
Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned. In addition, we show the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
PyReason: Software for Open World Temporal Logic
Mar 04, 2023



The growing popularity of neuro symbolic reasoning has led to the adoption of various forms of differentiable (i.e., fuzzy) first order logic. We introduce PyReason, a software framework based on generalized annotated logic that both captures the current cohort of differentiable logics and temporal extensions to support inference over finite periods of time with capabilities for open world reasoning. Further, PyReason is implemented to directly support reasoning over graphical structures (e.g., knowledge graphs, social networks, biological networks, etc.), produces fully explainable traces of inference, and includes various practical features such as type checking and a memory-efficient implementation. This paper reviews various extensions of generalized annotated logic integrated into our implementation, our modern, efficient Python-based implementation that conducts exact yet scalable deductive inference, and a suite of experiments. PyReason is available at: github.com/lab-v2/pyreason.