 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVESPATIAL: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
May 22, 2026Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes. We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning. Evaluating 15 representative VLMs reveals a substantial human-model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction emerging as the key bottleneck. Further diagnostics show that language-only prompting is insufficient, while explicit BEV grounding consistently improves performance. These results suggest that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence. DriveSpatial and its construction pipeline will be released to support future research.
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Apr 24, 2026Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
SemLT3D: Semantic-Guided Expert Distillation for Camera-only Long-Tailed 3D Object Detection
Apr 20, 2026Camera-only 3D object detection has emerged as a cost-effective and scalable alternative to LiDAR for autonomous driving, yet existing methods primarily prioritize overall performance while overlooking the severe long-tail imbalance inherent in real-world datasets. In practice, many rare but safety-critical categories such as children, strollers, or emergency vehicles are heavily underrepresented, leading to biased learning and degraded performance. This challenge is further exacerbated by pronounced inter-class ambiguity (e.g., visually similar subclasses) and substantial intra-class diversity (e.g., objects varying widely in appearance, scale, pose, or context), which together hinder reliable long-tail recognition. In this work, we introduce SemLT3D, a Semantic-Guided Expert Distillation framework designed to enrich the representation space for underrepresented classes through semantic priors. SemLT3D consists of: (1) a language-guided mixture-of-experts module that routes 3D queries to specialized experts according to their semantic affinity, enabling the model to better disentangle confusing classes and specialize on tail distributions; and (2) a semantic projection distillation pipeline that aligns 3D queries with CLIP-informed 2D semantics, producing more coherent and discriminative features across diverse visual manifestations. Although motivated by long-tail imbalance, the semantically structured learning in SemLT3D also improves robustness under broader appearance variations and challenging corner cases, offering a principled step toward more reliable camera-only 3D perception.
Domain Expansion: A Latent Space Construction Framework for Multi-Task Learning
Jan 27, 2026Training a single network with multiple objectives often leads to conflicting gradients that degrade shared representations, forcing them into a compromised state that is suboptimal for any single task--a problem we term latent representation collapse. We introduce Domain Expansion, a framework that prevents these conflicts by restructuring the latent space itself. Our framework uses a novel orthogonal pooling mechanism to construct a latent space where each objective is assigned to a mutually orthogonal subspace. We validate our approach across diverse benchmarks--including ShapeNet, MPIIGaze, and Rotated MNIST--on challenging multi-objective problems combining classification with pose and gaze estimation. Our experiments demonstrate that this structure not only prevents collapse but also yields an explicit, interpretable, and compositional latent space where concepts can be directly manipulated.
Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
Dec 27, 2025Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
Amodal Instance Segmentation with Diffusion Shape Prior Estimation
Sep 26, 2024Amodal Instance Segmentation (AIS) presents an intriguing challenge, including the segmentation prediction of both visible and occluded parts of objects within images. Previous methods have often relied on shape prior information gleaned from training data to enhance amodal segmentation. However, these approaches are susceptible to overfitting and disregard object category details. Recent advancements highlight the potential of conditioned diffusion models, pretrained on extensive datasets, to generate images from latent space. Drawing inspiration from this, we propose AISDiff with a Diffusion Shape Prior Estimation (DiffSP) module. AISDiff begins with the prediction of the visible segmentation mask and object category, alongside occlusion-aware processing through the prediction of occluding masks. Subsequently, these elements are inputted into our DiffSP module to infer the shape prior of the object. DiffSP utilizes conditioned diffusion models pretrained on extensive datasets to extract rich visual features for shape prior estimation. Additionally, we introduce the Shape Prior Amodal Predictor, which utilizes attention-based feature maps from the shape prior to refine amodal segmentation. Experiments across various AIS benchmarks demonstrate the effectiveness of our AISDiff.
Error Detection and Constraint Recovery in Hierarchical Multi-Label Classification without Prior Knowledge
Jul 21, 2024
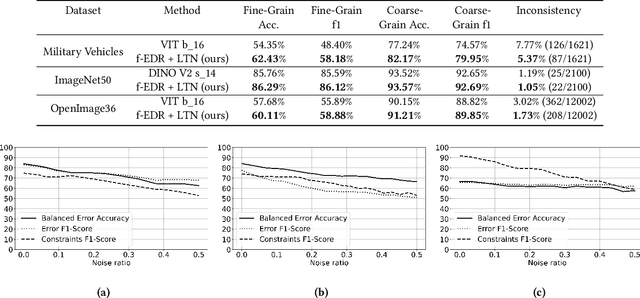
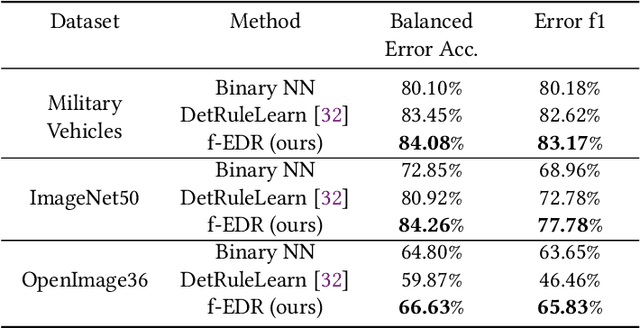
Recent advances in Hierarchical Multi-label Classification (HMC), particularly neurosymbolic-based approaches, have demonstrated improved consistency and accuracy by enforcing constraints on a neural model during training. However, such work assumes the existence of such constraints a-priori. In this paper, we relax this strong assumption and present an approach based on Error Detection Rules (EDR) that allow for learning explainable rules about the failure modes of machine learning models. We show that these rules are not only effective in detecting when a machine learning classifier has made an error but also can be leveraged as constraints for HMC, thereby allowing the recovery of explainable constraints even if they are not provided. We show that our approach is effective in detecting machine learning errors and recovering constraints, is noise tolerant, and can function as a source of knowledge for neurosymbolic models on multiple datasets, including a newly introduced military vehicle recognition dataset.
HENASY: Learning to Assemble Scene-Entities for Egocentric Video-Language Model
Jun 01, 2024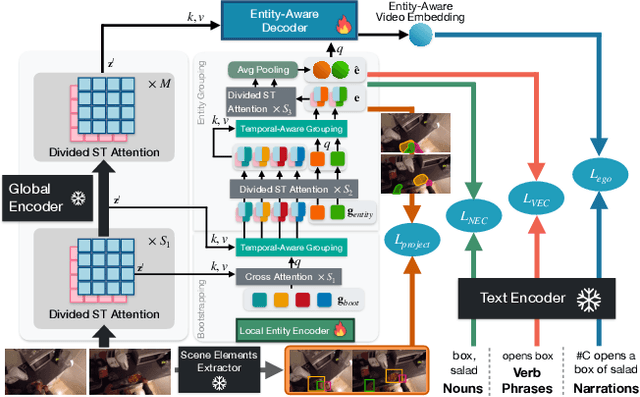



Video-Language Models (VLMs), pre-trained on large-scale video-caption datasets, are now standard for robust visual-language representation and downstream tasks. However, their reliance on global contrastive alignment limits their ability to capture fine-grained interactions between visual and textual elements. To address these challenges, we introduce HENASY (Hierarchical ENtities ASsemblY), a novel framework designed for egocentric video analysis that enhances the granularity of video content representations. HENASY employs a compositional approach using an enhanced slot-attention and grouping mechanisms for videos, assembling dynamic entities from video patches. It integrates a local entity encoder for dynamic modeling, a global encoder for broader contextual understanding, and an entity-aware decoder for late-stage fusion, enabling effective video scene dynamics modeling and granular-level alignment between visual entities and text. By incorporating innovative contrastive losses, HENASY significantly improves entity and activity recognition, delivering superior performance on benchmarks such as Ego4D and EpicKitchen, and setting new standards in both zero-shot and extensive video understanding tasks. Our results confirm groundbreaking capabilities of HENASY and establish it as a significant advancement in video-language multimodal research.