 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-TSA: CLIP-Assisted Temporal Self-Attention for Weakly-Supervised Video Anomaly Detection
Paper and Code
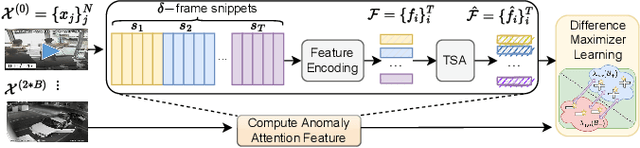

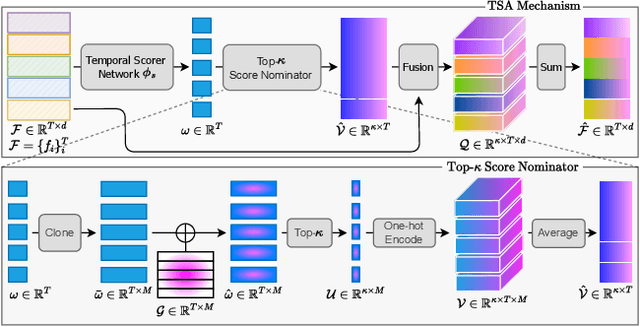
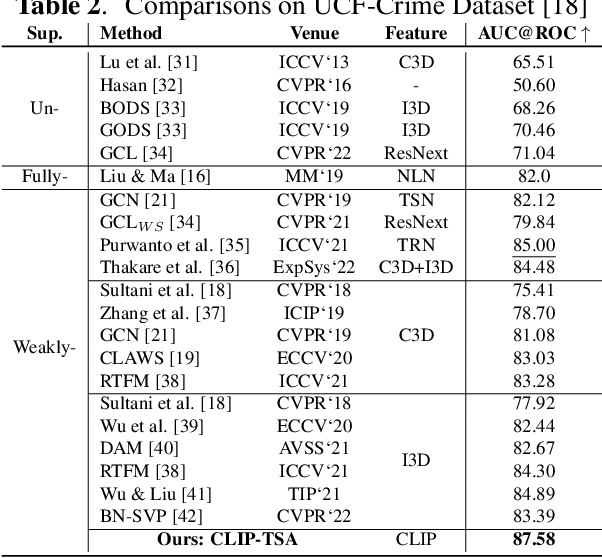
Video anomaly detection (VAD) -- commonly formulated as a multiple-instance learning problem in a weakly-supervised manner due to its labor-intensive nature -- is a challenging problem in video surveillance where the frames of anomaly need to be localized in an untrimmed video. In this paper, we first propose to utilize the ViT-encoded visual features from CLIP, in contrast with the conventional C3D or I3D features in the domain, to efficiently extract discriminative representations in the novel technique. We then model long- and short-range temporal dependencies and nominate the snippets of interest by leveraging our proposed Temporal Self-Attention (TSA). The ablation study conducted on each component confirms its effectiveness in the problem, and the extensive experiments show that our proposed CLIP-TSA outperforms the existing state-of-the-art (SOTA) methods by a large margin on two commonly-used benchmark datasets in the VAD problem (UCF-Crime and ShanghaiTech Campus). The source code will be made publicly available upon acceptance.