 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2VIS: Amodal-Aware Approach to Video Instance Segmentation
Dec 02, 2024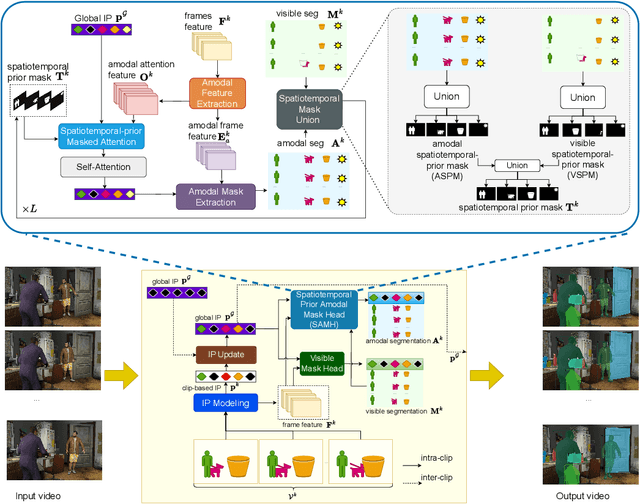
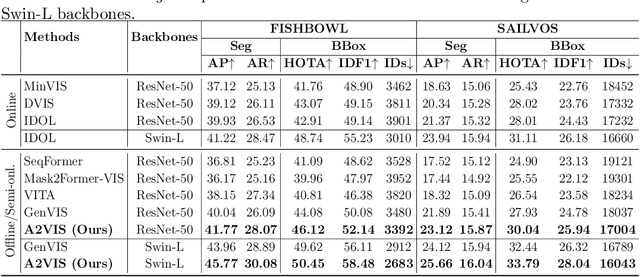
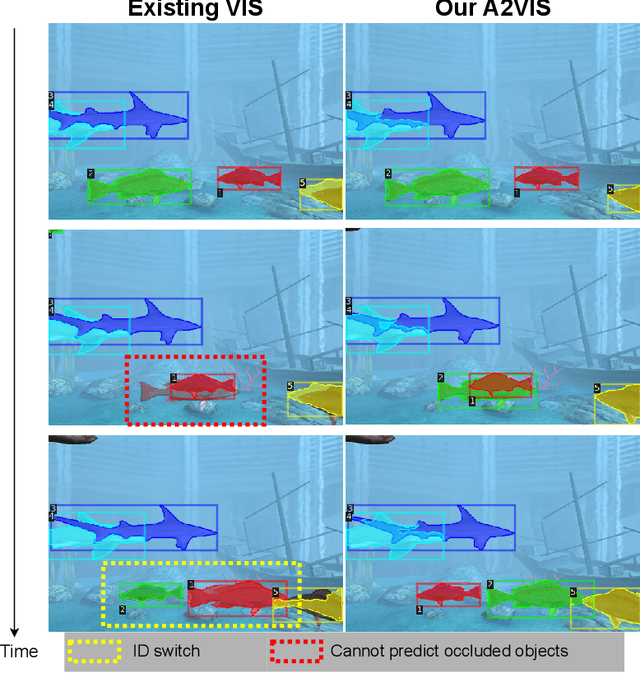
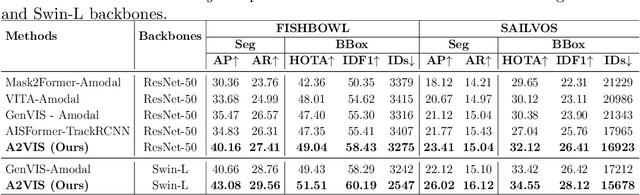
Handling occlusion remains a significant challenge for video instance-level tasks like Multiple Object Tracking (MOT) and Video Instance Segmentation (VIS). In this paper, we propose a novel framework, Amodal-Aware Video Instance Segmentation (A2VIS), which incorporates amodal representations to achieve a reliable and comprehensive understanding of both visible and occluded parts of objects in a video. The key intuition is that awareness of amodal segmentation through spatiotemporal dimension enables a stable stream of object information. In scenarios where objects are partially or completely hidden from view, amodal segmentation offers more consistency and less dramatic changes along the temporal axis compared to visible segmentation. Hence, both amodal and visible information from all clips can be integrated into one global instance prototype. To effectively address the challenge of video amodal segmentation, we introduce the spatiotemporal-prior Amodal Mask Head, which leverages visible information intra clips while extracting amodal characteristics inter clips. Through extensive experiments and ablation studies, we show that A2VIS excels in both MOT and VIS tasks in identifying and tracking object instances with a keen understanding of their full shape.
Open-Fusion: Real-time Open-Vocabulary 3D Mapping and Queryable Scene Representation
Oct 05, 2023



Precise 3D environmental mapping is pivotal in robotics. Existing methods often rely on predefined concepts during training or are time-intensive when generating semantic maps. This paper presents Open-Fusion, a groundbreaking approach for real-time open-vocabulary 3D mapping and queryable scene representation using RGB-D data. Open-Fusion harnesses the power of a pre-trained vision-language foundation model (VLFM) for open-set semantic comprehension and employs the Truncated Signed Distance Function (TSDF) for swift 3D scene reconstruction. By leveraging the VLFM, we extract region-based embeddings and their associated confidence maps. These are then integrated with 3D knowledge from TSDF using an enhanced Hungarian-based feature-matching mechanism. Notably, Open-Fusion delivers outstanding annotation-free 3D segmentation for open-vocabulary without necessitating additional 3D training. Benchmark tests on the ScanNet dataset against leading zero-shot methods highlight Open-Fusion's superiority. Furthermore, it seamlessly combines the strengths of region-based VLFM and TSDF, facilitating real-time 3D scene comprehension that includes object concepts and open-world semantics. We encourage the readers to view the demos on our project page: https://uark-aicv.github.io/OpenFusion
Music-Driven Group Choreography
Mar 27, 2023



Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/