 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Jailbreak Attempts in Clinical Training LLMs Through Automated Linguistic Feature Extraction
Feb 10, 2026Detecting jailbreak attempts in clinical training large language models (LLMs) requires accurate modeling of linguistic deviations that signal unsafe or off-task user behavior. Prior work on the 2-Sigma clinical simulation platform showed that manually annotated linguistic features could support jailbreak detection. However, reliance on manual annotation limited both scalability and expressiveness. In this study, we extend this framework by using experts' annotations of four core linguistic features (Professionalism, Medical Relevance, Ethical Behavior, and Contextual Distraction) and training multiple general-domain and medical-domain BERT-based LLM models to predict these features directly from text. The most reliable feature regressor for each dimension was selected and used as the feature extractor in a second layer of classifiers. We evaluate a suite of predictive models, including tree-based, linear, probabilistic, and ensemble methods, to determine jailbreak likelihood from the extracted features. Across cross-validation and held-out evaluations, the system achieves strong overall performance, indicating that LLM-derived linguistic features provide an effective basis for automated jailbreak detection. Error analysis further highlights key limitations in current annotations and feature representations, pointing toward future improvements such as richer annotation schemes, finer-grained feature extraction, and methods that capture the evolving risk of jailbreak behavior over the course of a dialogue. This work demonstrates a scalable and interpretable approach for detecting jailbreak behavior in safety-critical clinical dialogue systems.
Distribution Matching via Generalized Consistency Models
Aug 17, 2025Recent advancement in generative models have demonstrated remarkable performance across various data modalities. Beyond their typical use in data synthesis, these models play a crucial role in distribution matching tasks such as latent variable modeling, domain translation, and domain adaptation. Generative Adversarial Networks (GANs) have emerged as the preferred method of distribution matching due to their efficacy in handling high-dimensional data and their flexibility in accommodating various constraints. However, GANs often encounter challenge in training due to their bi-level min-max optimization objective and susceptibility to mode collapse. In this work, we propose a novel approach for distribution matching inspired by the consistency models employed in Continuous Normalizing Flow (CNF). Our model inherits the advantages of CNF models, such as having a straight forward norm minimization objective, while remaining adaptable to different constraints similar to GANs. We provide theoretical validation of our proposed objective and demonstrate its performance through experiments on synthetic and real-world datasets.
LLM-as-a-Fuzzy-Judge: Fine-Tuning Large Language Models as a Clinical Evaluation Judge with Fuzzy Logic
Jun 12, 2025Clinical communication skills are critical in medical education, and practicing and assessing clinical communication skills on a scale is challenging. Although LLM-powered clinical scenario simulations have shown promise in enhancing medical students' clinical practice, providing automated and scalable clinical evaluation that follows nuanced physician judgment is difficult. This paper combines fuzzy logic and Large Language Model (LLM) and proposes LLM-as-a-Fuzzy-Judge to address the challenge of aligning the automated evaluation of medical students' clinical skills with subjective physicians' preferences. LLM-as-a-Fuzzy-Judge is an approach that LLM is fine-tuned to evaluate medical students' utterances within student-AI patient conversation scripts based on human annotations from four fuzzy sets, including Professionalism, Medical Relevance, Ethical Behavior, and Contextual Distraction. The methodology of this paper started from data collection from the LLM-powered medical education system, data annotation based on multidimensional fuzzy sets, followed by prompt engineering and the supervised fine-tuning (SFT) of the pre-trained LLMs using these human annotations. The results show that the LLM-as-a-Fuzzy-Judge achieves over 80\% accuracy, with major criteria items over 90\%, effectively leveraging fuzzy logic and LLM as a solution to deliver interpretable, human-aligned assessment. This work suggests the viability of leveraging fuzzy logic and LLM to align with human preferences, advances automated evaluation in medical education, and supports more robust assessment and judgment practices. The GitHub repository of this work is available at https://github.com/2sigmaEdTech/LLMAsAJudge
Jailbreak Detection in Clinical Training LLMs Using Feature-Based Predictive Models
Apr 21, 2025
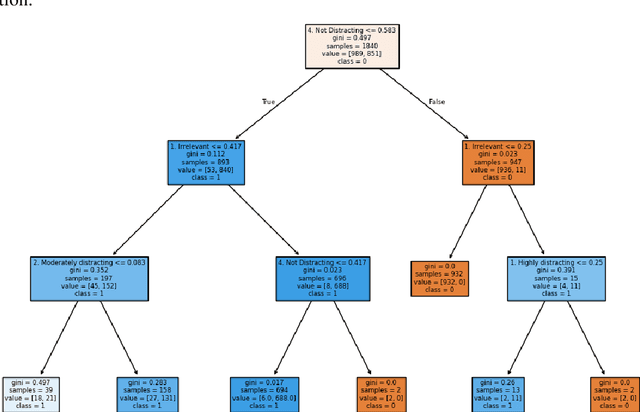


Jailbreaking in Large Language Models (LLMs) threatens their safe use in sensitive domains like education by allowing users to bypass ethical safeguards. This study focuses on detecting jailbreaks in 2-Sigma, a clinical education platform that simulates patient interactions using LLMs. We annotated over 2,300 prompts across 158 conversations using four linguistic variables shown to correlate strongly with jailbreak behavior. The extracted features were used to train several predictive models, including Decision Trees, Fuzzy Logic-based classifiers, Boosting methods, and Logistic Regression. Results show that feature-based predictive models consistently outperformed Prompt Engineering, with the Fuzzy Decision Tree achieving the best overall performance. Our findings demonstrate that linguistic-feature-based models are effective and explainable alternatives for jailbreak detection. We suggest future work explore hybrid frameworks that integrate prompt-based flexibility with rule-based robustness for real-time, spectrum-based jailbreak monitoring in educational LLMs.
Fuzzy Logic -- Based Scheduling System for Part-Time Workforce
Apr 21, 2025This paper explores the application of genetic fuzzy systems to efficiently generate schedules for a team of part-time student workers at a university. Given the preferred number of working hours and availability of employees, our model generates feasible solutions considering various factors, such as maximum weekly hours, required number of workers on duty, and the preferred number of working hours. The algorithm is trained and tested with availability data collected from students at the University of Cincinnati. The results demonstrate the algorithm's efficiency in producing schedules that meet operational criteria and its robustness in understaffed conditions.
A2VIS: Amodal-Aware Approach to Video Instance Segmentation
Dec 02, 2024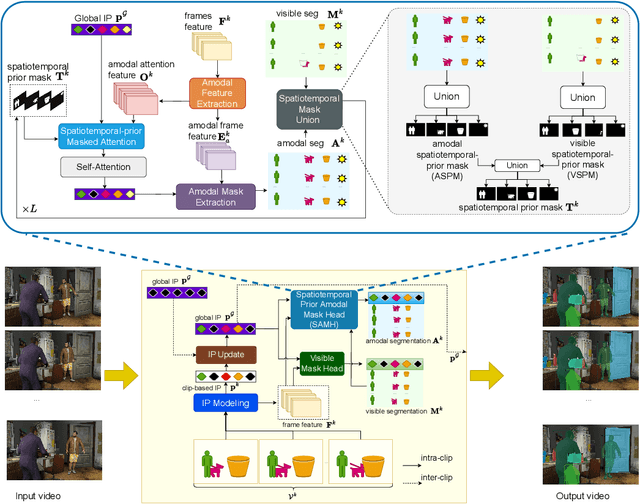
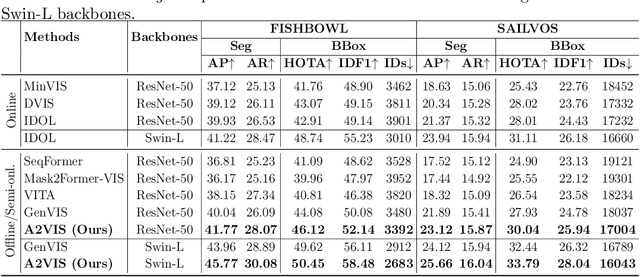
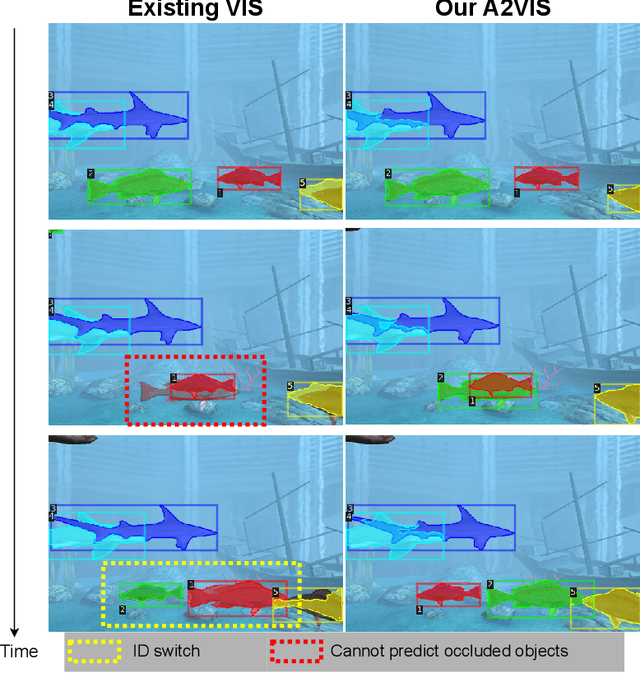
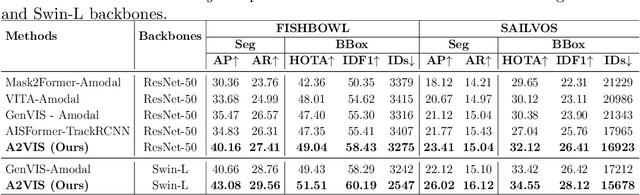
Handling occlusion remains a significant challenge for video instance-level tasks like Multiple Object Tracking (MOT) and Video Instance Segmentation (VIS). In this paper, we propose a novel framework, Amodal-Aware Video Instance Segmentation (A2VIS), which incorporates amodal representations to achieve a reliable and comprehensive understanding of both visible and occluded parts of objects in a video. The key intuition is that awareness of amodal segmentation through spatiotemporal dimension enables a stable stream of object information. In scenarios where objects are partially or completely hidden from view, amodal segmentation offers more consistency and less dramatic changes along the temporal axis compared to visible segmentation. Hence, both amodal and visible information from all clips can be integrated into one global instance prototype. To effectively address the challenge of video amodal segmentation, we introduce the spatiotemporal-prior Amodal Mask Head, which leverages visible information intra clips while extracting amodal characteristics inter clips. Through extensive experiments and ablation studies, we show that A2VIS excels in both MOT and VIS tasks in identifying and tracking object instances with a keen understanding of their full shape.
Amodal Instance Segmentation with Diffusion Shape Prior Estimation
Sep 26, 2024Amodal Instance Segmentation (AIS) presents an intriguing challenge, including the segmentation prediction of both visible and occluded parts of objects within images. Previous methods have often relied on shape prior information gleaned from training data to enhance amodal segmentation. However, these approaches are susceptible to overfitting and disregard object category details. Recent advancements highlight the potential of conditioned diffusion models, pretrained on extensive datasets, to generate images from latent space. Drawing inspiration from this, we propose AISDiff with a Diffusion Shape Prior Estimation (DiffSP) module. AISDiff begins with the prediction of the visible segmentation mask and object category, alongside occlusion-aware processing through the prediction of occluding masks. Subsequently, these elements are inputted into our DiffSP module to infer the shape prior of the object. DiffSP utilizes conditioned diffusion models pretrained on extensive datasets to extract rich visual features for shape prior estimation. Additionally, we introduce the Shape Prior Amodal Predictor, which utilizes attention-based feature maps from the shape prior to refine amodal segmentation. Experiments across various AIS benchmarks demonstrate the effectiveness of our AISDiff.
How DREAMS are made: Emulating Satellite Galaxy and Subhalo Populations with Diffusion Models and Point Clouds
Sep 04, 2024



The connection between galaxies and their host dark matter (DM) halos is critical to our understanding of cosmology, galaxy formation, and DM physics. To maximize the return of upcoming cosmological surveys, we need an accurate way to model this complex relationship. Many techniques have been developed to model this connection, from Halo Occupation Distribution (HOD) to empirical and semi-analytic models to hydrodynamic. Hydrodynamic simulations can incorporate more detailed astrophysical processes but are computationally expensive; HODs, on the other hand, are computationally cheap but have limited accuracy. In this work, we present NeHOD, a generative framework based on variational diffusion model and Transformer, for painting galaxies/subhalos on top of DM with an accuracy of hydrodynamic simulations but at a computational cost similar to HOD. By modeling galaxies/subhalos as point clouds, instead of binning or voxelization, we can resolve small spatial scales down to the resolution of the simulations. For each halo, NeHOD predicts the positions, velocities, masses, and concentrations of its central and satellite galaxies. We train NeHOD on the TNG-Warm DM suite of the DREAMS project, which consists of 1024 high-resolution zoom-in hydrodynamic simulations of Milky Way-mass halos with varying warm DM mass and astrophysical parameters. We show that our model captures the complex relationships between subhalo properties as a function of the simulation parameters, including the mass functions, stellar-halo mass relations, concentration-mass relations, and spatial clustering. Our method can be used for a large variety of downstream applications, from galaxy clustering to strong lensing studies.
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Mar 22, 2024Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
Deep Learning From Crowdsourced Labels: Coupled Cross-entropy Minimization, Identifiability, and Regularization
Jun 05, 2023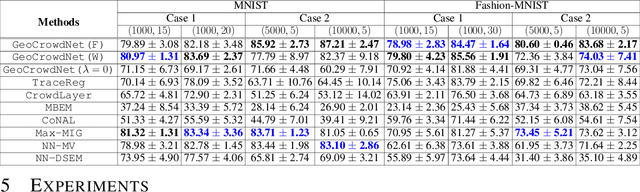
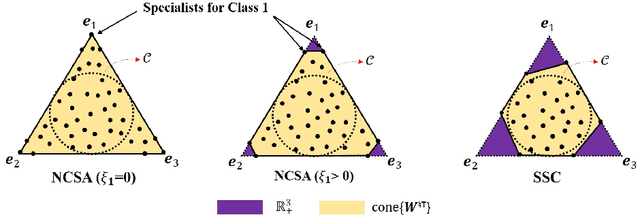
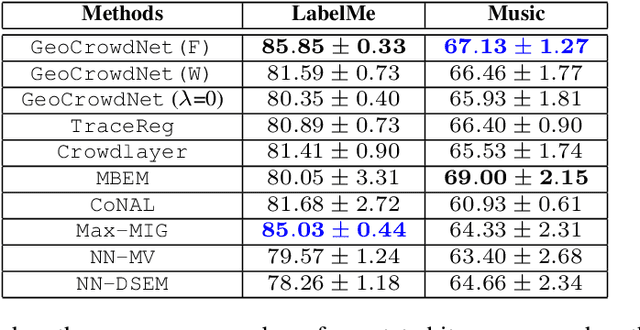
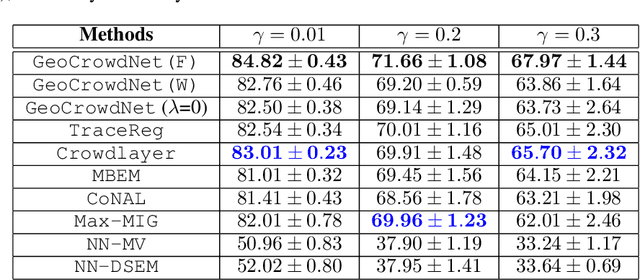
Using noisy crowdsourced labels from multiple annotators, a deep learning-based end-to-end (E2E) system aims to learn the label correction mechanism and the neural classifier simultaneously. To this end, many E2E systems concatenate the neural classifier with multiple annotator-specific ``label confusion'' layers and co-train the two parts in a parameter-coupled manner. The formulated coupled cross-entropy minimization (CCEM)-type criteria are intuitive and work well in practice. Nonetheless, theoretical understanding of the CCEM criterion has been limited. The contribution of this work is twofold: First, performance guarantees of the CCEM criterion are presented. Our analysis reveals for the first time that the CCEM can indeed correctly identify the annotators' confusion characteristics and the desired ``ground-truth'' neural classifier under realistic conditions, e.g., when only incomplete annotator labeling and finite samples are available. Second, based on the insights learned from our analysis, two regularized variants of the CCEM are proposed. The regularization terms provably enhance the identifiability of the target model parameters in various more challenging cases. A series of synthetic and real data experiments are presented to showcase the effectiveness of our approach.