 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Maximum Mean Discrepancy for Inference in Noisy Data
Apr 13, 2026Modern data analyses frequently encounter settings where samples of variables are contaminated by measurement error. Ignoring measurement noise can substantially degrade statistical inference, while existing correction techniques are often computationally costly and inefficient. Recent advances in kernel methods, particularly those based on Maximum Mean Discrepancy (MMD), have enabled flexible, distribution-free inference, yet typically assume precise data and overlook contamination by measurement error. In this work, we introduce a novel framework for inference with samples corrupted by potentially heteroscedastic noise from a known distribution. Central to our approach is the convolutional MMD (convMMD), which compares distributions after noise convolution and retains metric validity under standard kernel conditions. We establish finite-sample deviation bounds that are unaffected by measurement error and prove an equivalence between testing under noise and kernel smoothing. Leveraging these insights, we introduce a convMMD-based estimator for inference with noisy, heteroscedastic observations. We establish its consistency and asymptotic normality, and provide an efficient implementation using stochastic gradient descent. We demonstrate the practical effectiveness of our approach through simulations and applications in astronomy and social sciences.
Cosmo3DFlow: Wavelet Flow Matching for Spatial-to-Spectral Compression in Reconstructing the Early Universe
Feb 10, 2026Reconstructing the early Universe from the evolved present-day Universe is a challenging and computationally demanding problem in modern astrophysics. We devise a novel generative framework, Cosmo3DFlow, designed to address dimensionality and sparsity, the critical bottlenecks inherent in current state-of-the-art methods for cosmological inference. By integrating 3D Discrete Wavelet Transform (DWT) with flow matching, we effectively represent high-dimensional cosmological structures. The Wavelet Transform addresses the ``void problem'' by translating spatial emptiness into spectral sparsity. It decouples high-frequency details from low-frequency structures through spatial compression, and wavelet-space velocity fields facilitate stable ordinary differential equation (ODE) solvers with large step sizes. Using large-scale cosmological $N$-body simulations, at $128^3$ resolution, we achieve up to $50\times$ faster sampling than diffusion models, combining a $10\times$ reduction in integration steps with lower per-step computational cost from wavelet compression. Our results enable initial conditions to be sampled in seconds, compared to minutes for previous methods.
Simulation-Based Inference via Regression Projection and Batched Discrepancies
Feb 03, 2026We analyze a lightweight simulation-based inference method that infers simulator parameters using only a regression-based projection of the observed data. After fitting a surrogate linear regression once, the procedure simulates small batches at the proposed parameter values and assigns kernel weights based on the resulting batch-residual discrepancy, producing a self-normalized pseudo-posterior that is simple, parallelizable, and requires access only to the fitted regression coefficients rather than raw observations. We formalize the construction as an importance-sampling approximation to a population target that averages over simulator randomness, prove consistency as the number of parameter draws grows, and establish stability in estimating the surrogate regression from finite samples. We then characterize the asymptotic concentration as the batch size increases and the bandwidth shrinks, showing that the pseudo-posterior concentrates on an identified set determined by the chosen projection, thereby clarifying when the method yields point versus set identification. Experiments on a tractable nonlinear model and on a cosmological calibration task using the DREAMS simulation suite illustrate the computational advantages of regression-based projections and the identifiability limitations arising from low-information summaries.
Density-Informed Pseudo-Counts for Calibrated Evidential Deep Learning
Feb 01, 2026Evidential Deep Learning (EDL) is a popular framework for uncertainty-aware classification that models predictive uncertainty via Dirichlet distributions parameterized by neural networks. Despite its popularity, its theoretical foundations and behavior under distributional shift remain poorly understood. In this work, we provide a principled statistical interpretation by proving that EDL training corresponds to amortized variational inference in a hierarchical Bayesian model with a tempered pseudo-likelihood. This perspective reveals a major drawback: standard EDL conflates epistemic and aleatoric uncertainty, leading to systematic overconfidence on out-of-distribution (OOD) inputs. To address this, we introduce Density-Informed Pseudo-count EDL (DIP-EDL), a new parametrization that decouples class prediction from the magnitude of uncertainty by separately estimating the conditional label distribution and the marginal covariate density. This separation preserves evidence in high-density regions while shrinking predictions toward a uniform prior for OOD data. Theoretically, we prove that DIP-EDL achieves asymptotic concentration. Empirically, we show that our method enhances interpretability and improves robustness and uncertainty calibration under distributional shift.
I-trustworthy Models. A framework for trustworthiness evaluation of probabilistic classifiers
Jan 26, 2025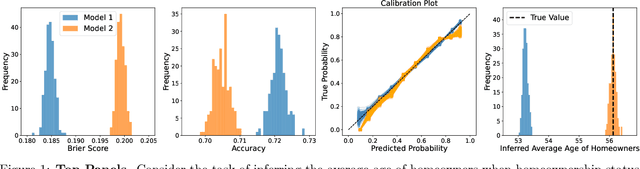

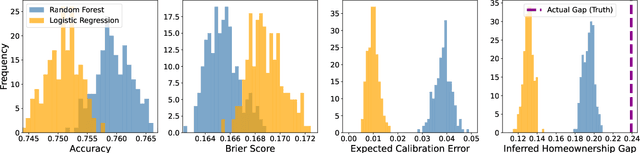
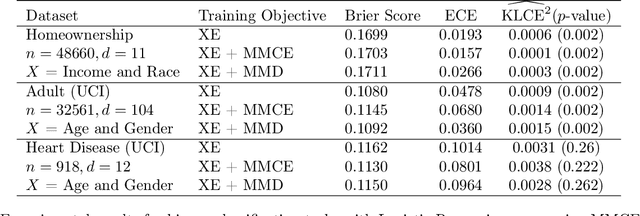
As probabilistic models continue to permeate various facets of our society and contribute to scientific advancements, it becomes a necessity to go beyond traditional metrics such as predictive accuracy and error rates and assess their trustworthiness. Grounded in the competence-based theory of trust, this work formalizes I-trustworthy framework -- a novel framework for assessing the trustworthiness of probabilistic classifiers for inference tasks by linking local calibration to trustworthiness. To assess I-trustworthiness, we use the local calibration error (LCE) and develop a method of hypothesis-testing. This method utilizes a kernel-based test statistic, Kernel Local Calibration Error (KLCE), to test local calibration of a probabilistic classifier. This study provides theoretical guarantees by offering convergence bounds for an unbiased estimator of KLCE. Additionally, we present a diagnostic tool designed to identify and measure biases in cases of miscalibration. The effectiveness of the proposed test statistic is demonstrated through its application to both simulated and real-world datasets. Finally, LCE of related recalibration methods is studied, and we provide evidence of insufficiency of existing methods to achieve I-trustworthiness.
How DREAMS are made: Emulating Satellite Galaxy and Subhalo Populations with Diffusion Models and Point Clouds
Sep 04, 2024



The connection between galaxies and their host dark matter (DM) halos is critical to our understanding of cosmology, galaxy formation, and DM physics. To maximize the return of upcoming cosmological surveys, we need an accurate way to model this complex relationship. Many techniques have been developed to model this connection, from Halo Occupation Distribution (HOD) to empirical and semi-analytic models to hydrodynamic. Hydrodynamic simulations can incorporate more detailed astrophysical processes but are computationally expensive; HODs, on the other hand, are computationally cheap but have limited accuracy. In this work, we present NeHOD, a generative framework based on variational diffusion model and Transformer, for painting galaxies/subhalos on top of DM with an accuracy of hydrodynamic simulations but at a computational cost similar to HOD. By modeling galaxies/subhalos as point clouds, instead of binning or voxelization, we can resolve small spatial scales down to the resolution of the simulations. For each halo, NeHOD predicts the positions, velocities, masses, and concentrations of its central and satellite galaxies. We train NeHOD on the TNG-Warm DM suite of the DREAMS project, which consists of 1024 high-resolution zoom-in hydrodynamic simulations of Milky Way-mass halos with varying warm DM mass and astrophysical parameters. We show that our model captures the complex relationships between subhalo properties as a function of the simulation parameters, including the mass functions, stellar-halo mass relations, concentration-mass relations, and spatial clustering. Our method can be used for a large variety of downstream applications, from galaxy clustering to strong lensing studies.
U-Trustworthy Models.Reliability, Competence, and Confidence in Decision-Making
Jan 04, 2024With growing concerns regarding bias and discrimination in predictive models, the AI community has increasingly focused on assessing AI system trustworthiness. Conventionally, trustworthy AI literature relies on the probabilistic framework and calibration as prerequisites for trustworthiness. In this work, we depart from this viewpoint by proposing a novel trust framework inspired by the philosophy literature on trust. We present a precise mathematical definition of trustworthiness, termed $\mathcal{U}$-trustworthiness, specifically tailored for a subset of tasks aimed at maximizing a utility function. We argue that a model's $\mathcal{U}$-trustworthiness is contingent upon its ability to maximize Bayes utility within this task subset. Our first set of results challenges the probabilistic framework by demonstrating its potential to favor less trustworthy models and introduce the risk of misleading trustworthiness assessments. Within the context of $\mathcal{U}$-trustworthiness, we prove that properly-ranked models are inherently $\mathcal{U}$-trustworthy. Furthermore, we advocate for the adoption of the AUC metric as the preferred measure of trustworthiness. By offering both theoretical guarantees and experimental validation, AUC enables robust evaluation of trustworthiness, thereby enhancing model selection and hyperparameter tuning to yield more trustworthy outcomes.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
Aug 17, 2018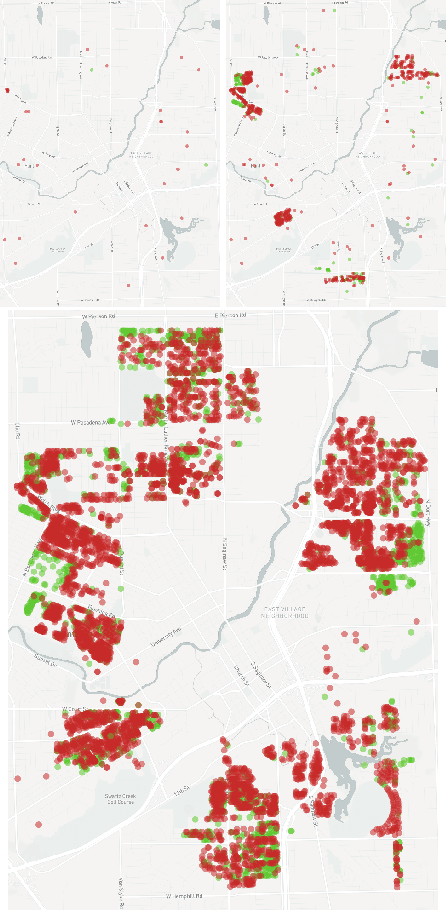

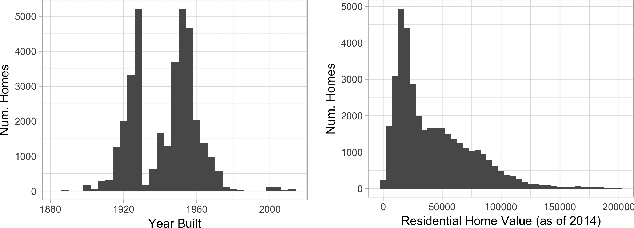
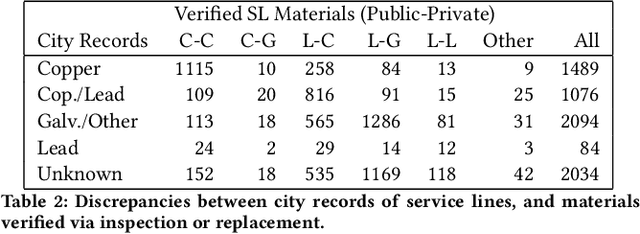
We detail our ongoing work in Flint, Michigan to detect pipes made of lead and other hazardous metals. After elevated levels of lead were detected in residents' drinking water, followed by an increase in blood lead levels in area children, the state and federal governments directed over $125 million to replace water service lines, the pipes connecting each home to the water system. In the absence of accurate records, and with the high cost of determining buried pipe materials, we put forth a number of predictive and procedural tools to aid in the search and removal of lead infrastructure. Alongside these statistical and machine learning approaches, we describe our interactions with government officials in recommending homes for both inspection and replacement, with a focus on the statistical model that adapts to incoming information. Finally, in light of discussions about increased spending on infrastructure development by the federal government, we explore how our approach generalizes beyond Flint to other municipalities nationwide.
A Data Science Approach to Understanding Residential Water Contamination in Flint
Jul 05, 2017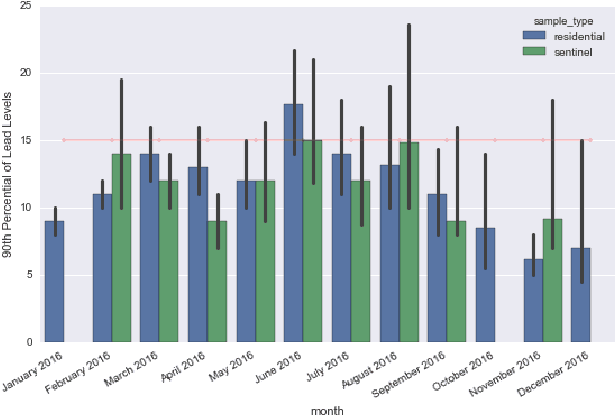

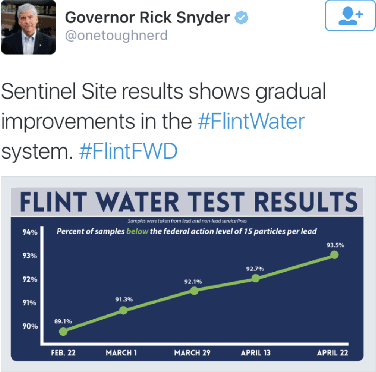
When the residents of Flint learned that lead had contaminated their water system, the local government made water-testing kits available to them free of charge. The city government published the results of these tests, creating a valuable dataset that is key to understanding the causes and extent of the lead contamination event in Flint. This is the nation's largest dataset on lead in a municipal water system. In this paper, we predict the lead contamination for each household's water supply, and we study several related aspects of Flint's water troubles, many of which generalize well beyond this one city. For example, we show that elevated lead risks can be (weakly) predicted from observable home attributes. Then we explore the factors associated with elevated lead. These risk assessments were developed in part via a crowd sourced prediction challenge at the University of Michigan. To inform Flint residents of these assessments, they have been incorporated into a web and mobile application funded by \texttt{Google.org}. We also explore questions of self-selection in the residential testing program, examining which factors are linked to when and how frequently residents voluntarily sample their water.
Flint Water Crisis: Data-Driven Risk Assessment Via Residential Water Testing
Sep 30, 2016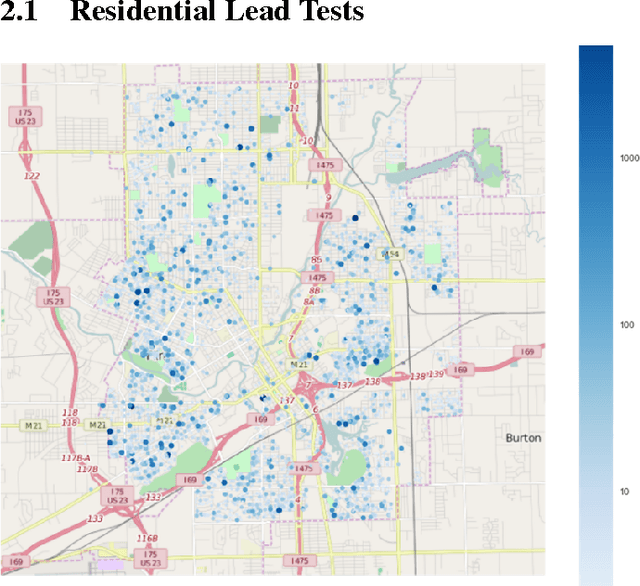

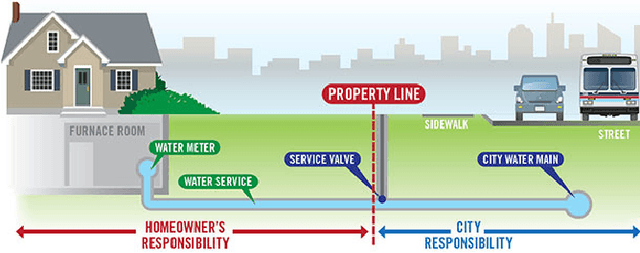
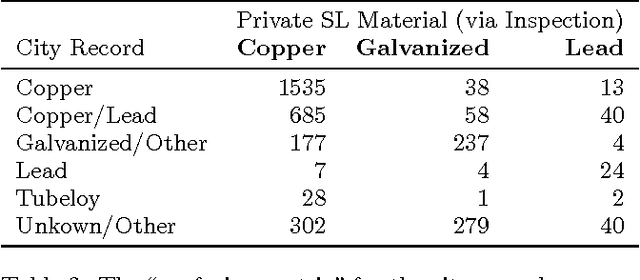
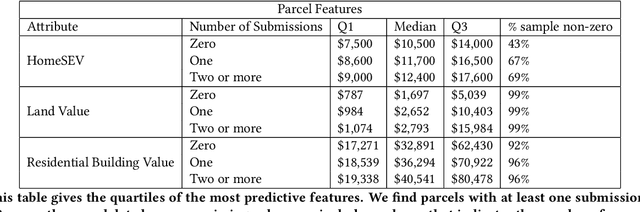
Recovery from the Flint Water Crisis has been hindered by uncertainty in both the water testing process and the causes of contamination. In this work, we develop an ensemble of predictive models to assess the risk of lead contamination in individual homes and neighborhoods. To train these models, we utilize a wide range of data sources, including voluntary residential water tests, historical records, and city infrastructure data. Additionally, we use our models to identify the most prominent factors that contribute to a high risk of lead contamination. In this analysis, we find that lead service lines are not the only factor that is predictive of the risk of lead contamination of water. These results could be used to guide the long-term recovery efforts in Flint, minimize the immediate damages, and improve resource-allocation decisions for similar water infrastructure crises.