 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Boosting for Multilabel Ranking with Top-k Feedback
Nov 06, 2019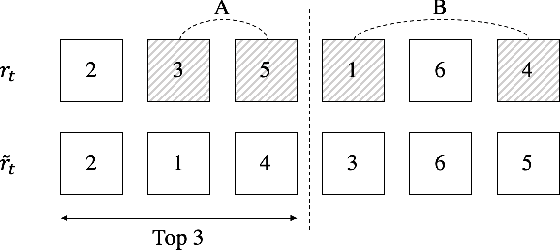
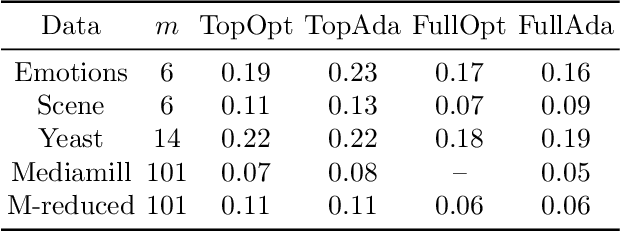
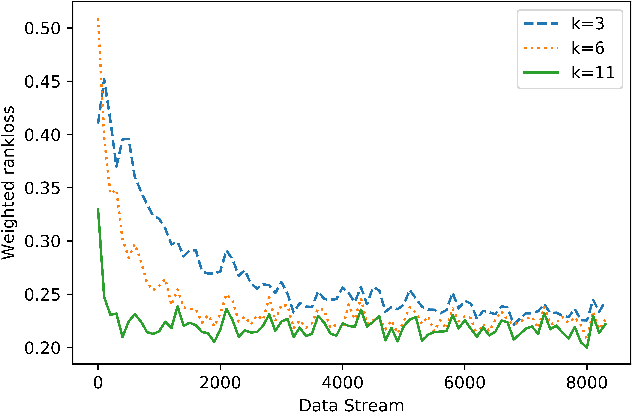

We present online boosting algorithms for multilabel ranking with top-k feedback,where the learner only receives information about the top-k items from the ranking it provides. We propose a novel surrogate loss function and unbiased estimator, allowing weak learners to update themselves with limited information. Using these techniques we adapt full information multilabel ranking algorithms (Jung and Tewari, 2018) to the top-k feedback setting and provide theoretical performance bounds which closely match the bounds of their full information counter parts, with the cost of increased sample complexity. The experimental results also verify these claims.
A Data Science Approach to Understanding Residential Water Contamination in Flint
Jul 05, 2017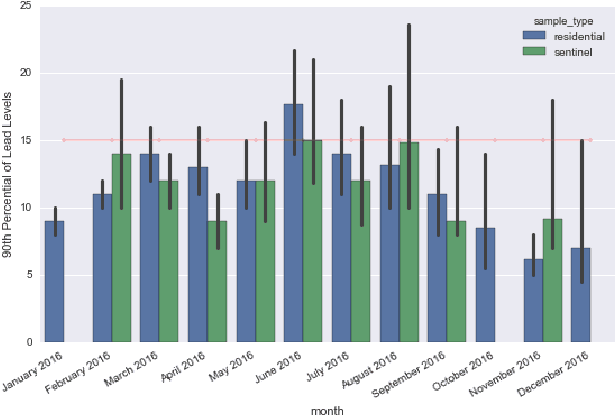

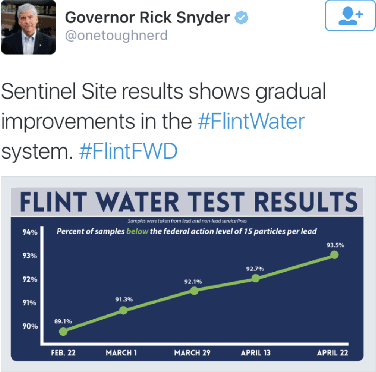
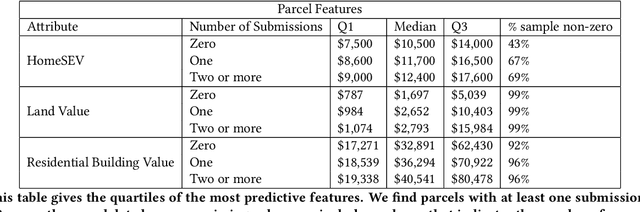
When the residents of Flint learned that lead had contaminated their water system, the local government made water-testing kits available to them free of charge. The city government published the results of these tests, creating a valuable dataset that is key to understanding the causes and extent of the lead contamination event in Flint. This is the nation's largest dataset on lead in a municipal water system. In this paper, we predict the lead contamination for each household's water supply, and we study several related aspects of Flint's water troubles, many of which generalize well beyond this one city. For example, we show that elevated lead risks can be (weakly) predicted from observable home attributes. Then we explore the factors associated with elevated lead. These risk assessments were developed in part via a crowd sourced prediction challenge at the University of Michigan. To inform Flint residents of these assessments, they have been incorporated into a web and mobile application funded by \texttt{Google.org}. We also explore questions of self-selection in the residential testing program, examining which factors are linked to when and how frequently residents voluntarily sample their water.