 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kinematic Model for Trajectory Prediction in General Highway Scenarios
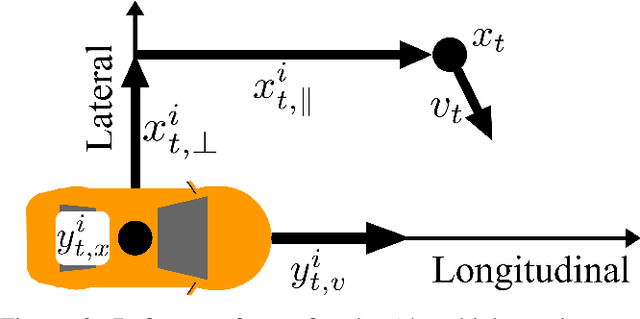
Mar 30, 2021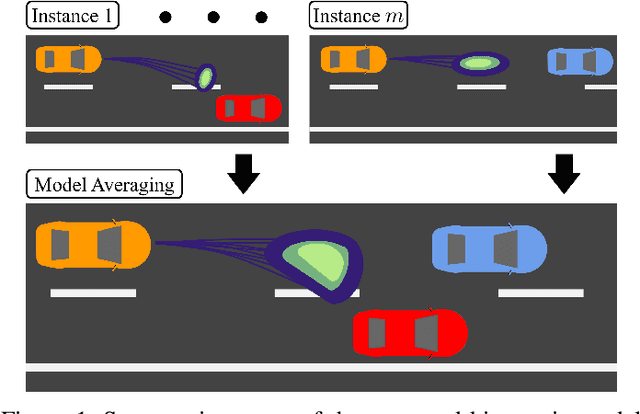
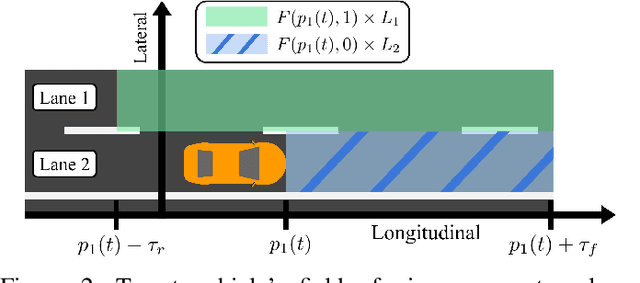


Highway driving invariably combines high speeds with the need to interact closely with other drivers. Prediction methods enable autonomous vehicles (AVs) to anticipate drivers' future trajectories and plan accordingly. Kinematic methods for prediction have traditionally ignored the presence of other drivers, or made predictions only for a limited set of scenarios. Data-driven approaches fill this gap by learning from large datasets to predict trajectories in general scenarios. While they achieve high accuracy, they also lose the interpretability and tools for model validation enjoyed by kinematic methods. This letter proposes a novel kinematic model to describe car-following and lane change behavior, and extends it to predict trajectories in general scenarios. Experiments on highway datasets under varied sensing conditions demonstrate that the proposed method outperforms state-of-the-art methods.
Off The Beaten Sidewalk: Pedestrian Prediction In Shared Spaces For Autonomous Vehicles
Jun 01, 2020

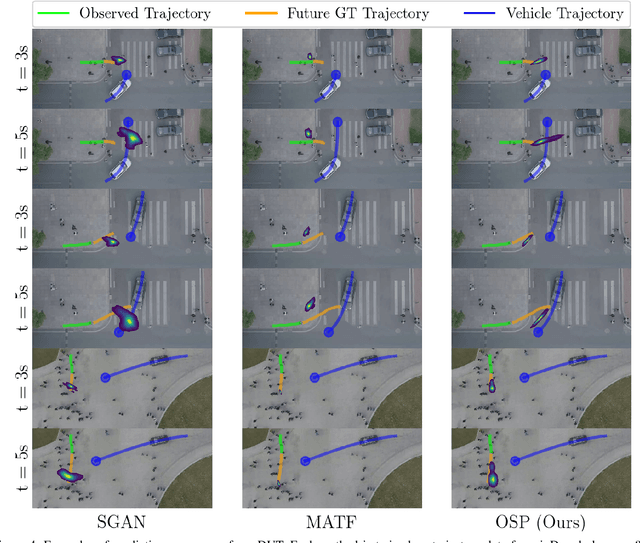
Pedestrians and drivers interact closely in a wide range of environments. Autonomous vehicles (AVs) correspondingly face the need to predict pedestrians' future trajectories in these same environments. Traditional model-based prediction methods have been limited to making predictions in highly structured scenes with signalized intersections, marked crosswalks, or curbs. Deep learning methods have instead leveraged datasets to learn predictive features that generalize across scenes, at the cost of model interpretability. This paper aims to achieve both widely applicable and interpretable predictions by proposing a risk-based attention mechanism to learn when pedestrians yield, and a model of vehicle influence to learn how yielding affects motion. A novel probabilistic method, Off the Sidewalk Predictions (OSP), uses these to achieve accurate predictions in both shared spaces and traditional scenes. Experiments on urban datasets demonstrate that the realtime method achieves state-of-the-art performance.
On-Demand Trajectory Predictions for Interaction Aware Highway Driving
Sep 11, 2019
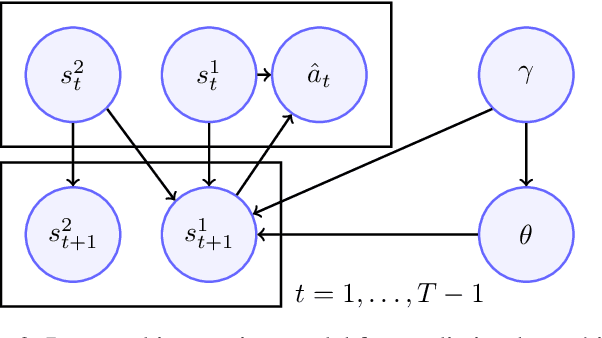
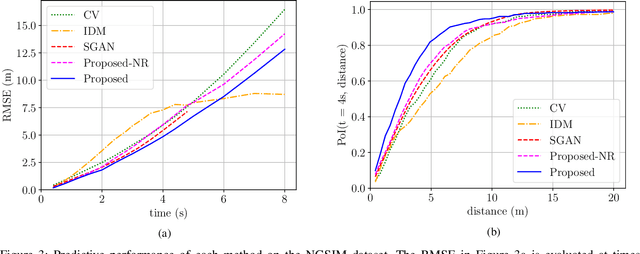
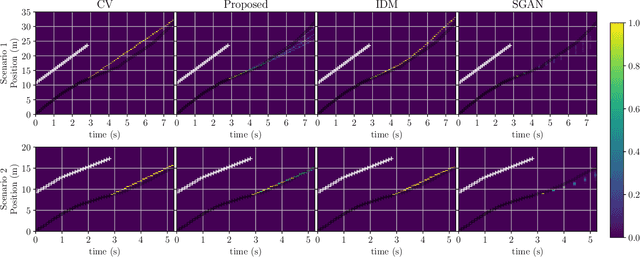
Highway driving places significant demands on human drivers and autonomous vehicles (AVs) alike due to high speeds and the complex interactions in dense traffic. Merging onto the highway poses additional challenges by limiting the amount of time available for decision-making. Predicting others' trajectories accurately and quickly is crucial to safely executing these maneuvers. Many existing prediction methods based on neural networks have focused on modeling interactions to achieve better accuracy while assuming the existence of observation windows over 3s long. This paper proposes a novel probabilistic model for trajectory prediction that performs competitively with as little as 400ms of observations. The proposed method fits a low-dimensional car-following model to observed behavior and introduces nonconvex regularization terms that enforce realistic driving behaviors in the predictions. The resulting inference procedure allows for realtime forecasts up to 10s into the future while accounting for interactions between vehicles. Experiments on dense traffic in the NGSIM dataset demonstrate that the proposed method achieves state-of-the-art performance with both highly constrained and more traditional observation windows.
Stochastic Sampling Simulation for Pedestrian Trajectory Prediction
Mar 05, 2019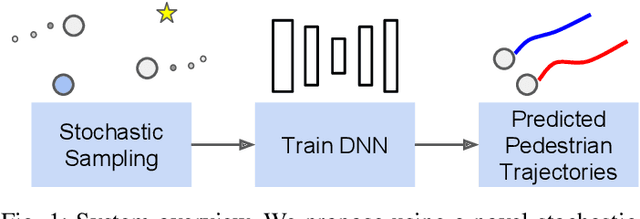
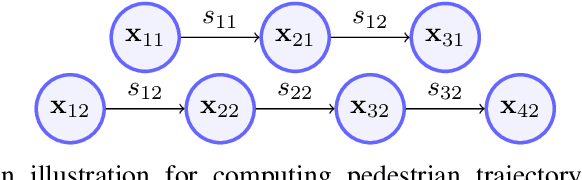

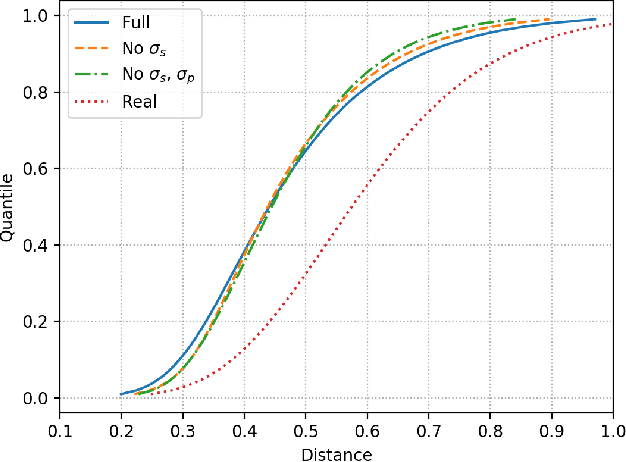
Urban environments pose a significant challenge for autonomous vehicles (AVs) as they must safely navigate while in close proximity to many pedestrians. It is crucial for the AV to correctly understand and predict the future trajectories of pedestrians to avoid collision and plan a safe path. Deep neural networks (DNNs) have shown promising results in accurately predicting pedestrian trajectories, relying on large amounts of annotated real-world data to learn pedestrian behavior. However, collecting and annotating these large real-world pedestrian datasets is costly in both time and labor. This paper describes a novel method using a stochastic sampling-based simulation to train DNNs for pedestrian trajectory prediction with social interaction. Our novel simulation method can generate vast amounts of automatically-annotated, realistic, and naturalistic synthetic pedestrian trajectories based on small amounts of real annotation. We then use such synthetic trajectories to train an off-the-shelf state-of-the-art deep learning approach Social GAN (Generative Adversarial Network) to perform pedestrian trajectory prediction. Our proposed architecture, trained only using synthetic trajectories, achieves better prediction results compared to those trained on human-annotated real-world data using the same network. Our work demonstrates the effectiveness and potential of using simulation as a substitution for human annotation efforts to train high-performing prediction algorithms such as the DNNs.
Failing to Learn: Autonomously Identifying Perception Failures for Self-driving Cars
Jul 26, 2018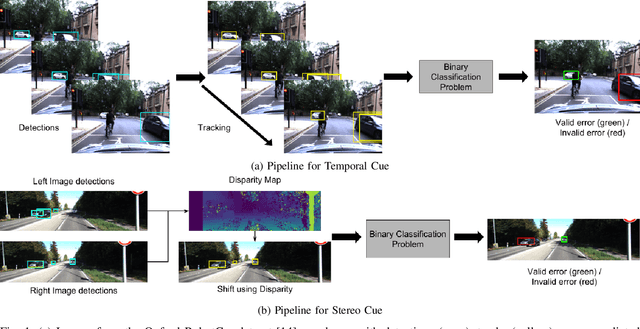
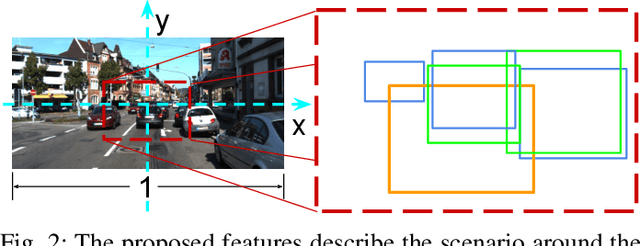
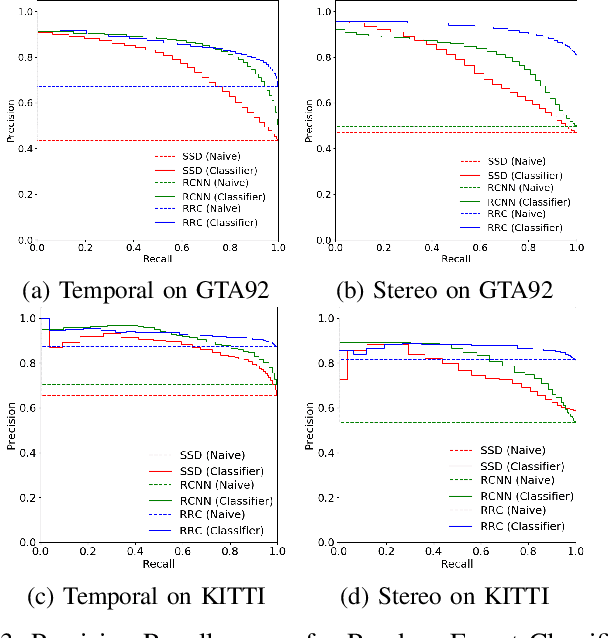
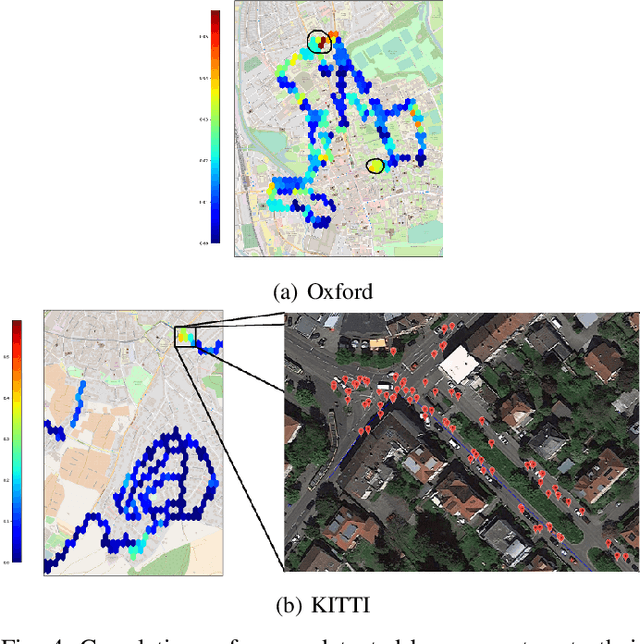
One of the major open challenges in self-driving cars is the ability to detect cars and pedestrians to safely navigate in the world. Deep learning-based object detector approaches have enabled great advances in using camera imagery to detect and classify objects. But for a safety critical application, such as autonomous driving, the error rates of the current state of the art are still too high to enable safe operation. Moreover, the characterization of object detector performance is primarily limited to testing on prerecorded datasets. Errors that occur on novel data go undetected without additional human labels. In this letter, we propose an automated method to identify mistakes made by object detectors without ground truth labels. We show that inconsistencies in the object detector output between a pair of similar images can be used as hypotheses for false negatives (e.g., missed detections) and using a novel set of features for each hypothesis, an off-the-shelf binary classifier can be used to find valid errors. In particular, we study two distinct cues - temporal and stereo inconsistencies - using data that are readily available on most autonomous vehicles. Our method can be used with any camera-based object detector and we illustrate the technique on several sets of real world data. We show that a state-of-the-art detector, tracker, and our classifier trained only on synthetic data can identify valid errors on KITTI tracking dataset with an average precision of 0.94. We also release a new tracking dataset with 104 sequences totaling 80,655 labeled pairs of stereo images along with ground truth disparity from a game engine to facilitate further research. The dataset and code are available at https://fcav.engin.umich.edu/research/failing-to-learn
Flint Water Crisis: Data-Driven Risk Assessment Via Residential Water Testing
Sep 30, 2016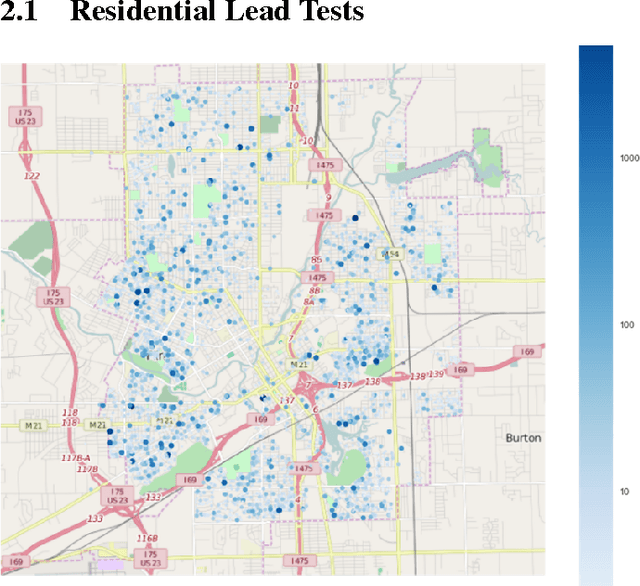

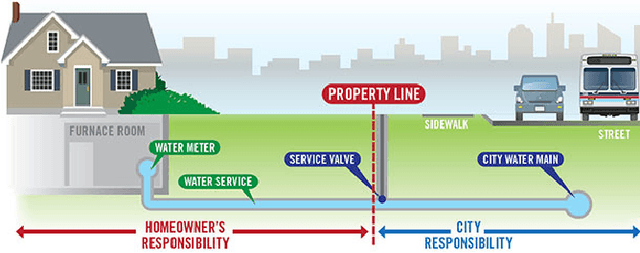
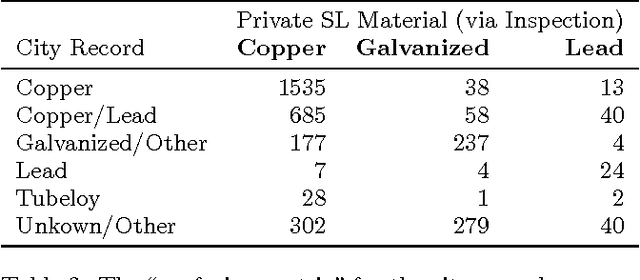
Recovery from the Flint Water Crisis has been hindered by uncertainty in both the water testing process and the causes of contamination. In this work, we develop an ensemble of predictive models to assess the risk of lead contamination in individual homes and neighborhoods. To train these models, we utilize a wide range of data sources, including voluntary residential water tests, historical records, and city infrastructure data. Additionally, we use our models to identify the most prominent factors that contribute to a high risk of lead contamination. In this analysis, we find that lead service lines are not the only factor that is predictive of the risk of lead contamination of water. These results could be used to guide the long-term recovery efforts in Flint, minimize the immediate damages, and improve resource-allocation decisions for similar water infrastructure crises.
Data Science in Service of Performing Arts: Applying Machine Learning to Predicting Audience Preferences
Sep 30, 2016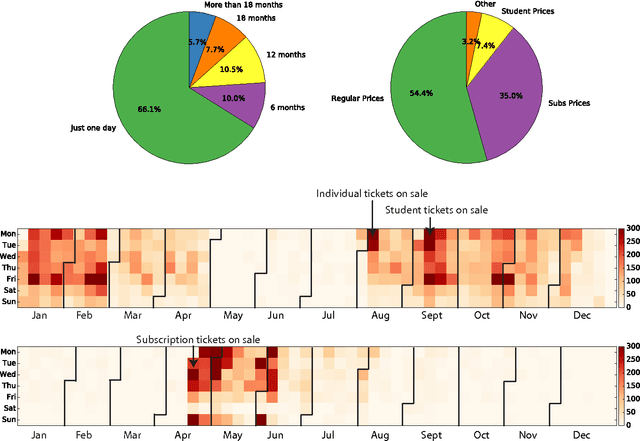
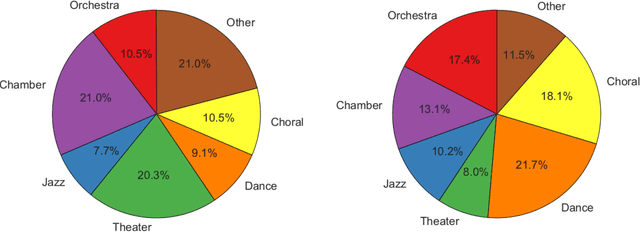
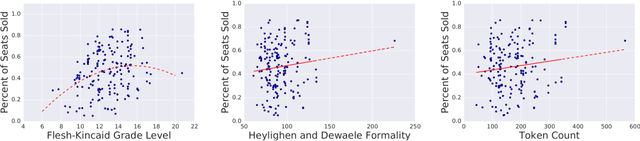
Performing arts organizations aim to enrich their communities through the arts. To do this, they strive to match their performance offerings to the taste of those communities. Success relies on understanding audience preference and predicting their behavior. Similar to most e-commerce or digital entertainment firms, arts presenters need to recommend the right performance to the right customer at the right time. As part of the Michigan Data Science Team (MDST), we partnered with the University Musical Society (UMS), a non-profit performing arts presenter housed in the University of Michigan, Ann Arbor. We are providing UMS with analysis and business intelligence, utilizing historical individual-level sales data. We built a recommendation system based on collaborative filtering, gaining insights into the artistic preferences of customers, along with the similarities between performances. To better understand audience behavior, we used statistical methods from customer-base analysis. We characterized customer heterogeneity via segmentation, and we modeled customer cohorts to understand and predict ticket purchasing patterns. Finally, we combined statistical modeling with natural language processing (NLP) to explore the impact of wording in program descriptions. These ongoing efforts provide a platform to launch targeted marketing campaigns, helping UMS carry out its mission by allocating its resources more efficiently. Celebrating its 138th season, UMS is a 2014 recipient of the National Medal of Arts, and it continues to enrich communities by connecting world-renowned artists with diverse audiences, especially students in their formative years. We aim to contribute to that mission through data science and customer analytics.