 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrip-Fusion: Spatiotemporal Fusion for Multispectral Pedestrian Detection
Jan 25, 2026Pedestrian detection is a critical task in robot perception. Multispectral modalities (visible light and thermal) can boost pedestrian detection performance by providing complementary visual information. Several gaps remain with multispectral pedestrian detection methods. First, existing approaches primarily focus on spatial fusion and often neglect temporal information. Second, RGB and thermal image pairs in multispectral benchmarks may not always be perfectly aligned. Pedestrians are also challenging to detect due to varying lighting conditions, occlusion, etc. This work proposes Strip-Fusion, a spatial-temporal fusion network that is robust to misalignment in input images, as well as varying lighting conditions and heavy occlusions. The Strip-Fusion pipeline integrates temporally adaptive convolutions to dynamically weigh spatial-temporal features, enabling our model to better capture pedestrian motion and context over time. A novel Kullback-Leibler divergence loss was designed to mitigate modality imbalance between visible and thermal inputs, guiding feature alignment toward the more informative modality during training. Furthermore, a novel post-processing algorithm was developed to reduce false positives. Extensive experimental results show that our method performs competitively for both the KAIST and the CVC-14 benchmarks. We also observed significant improvements compared to previous state-of-the-art on challenging conditions such as heavy occlusion and misalignment.
Bi-capacity Choquet Integral for Sensor Fusion with Label Uncertainty
Sep 05, 2024
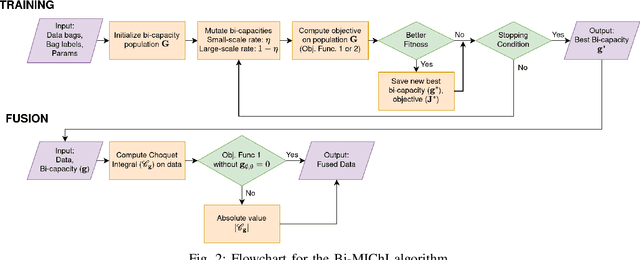


Sensor fusion combines data from multiple sensor sources to improve reliability, robustness, and accuracy of data interpretation. The Fuzzy Integral (FI), in particular, the Choquet integral (ChI), is often used as a powerful nonlinear aggregator for fusion across multiple sensors. However, existing supervised ChI learning algorithms typically require precise training labels for each input data point, which can be difficult or impossible to obtain. Additionally, prior work on ChI fusion is often based only on the normalized fuzzy measures, which bounds the fuzzy measure values between [0, 1]. This can be limiting in cases where the underlying scales of input data sources are bipolar (i.e., between [-1, 1]). To address these challenges, this paper proposes a novel Choquet integral-based fusion framework, named Bi-MIChI (pronounced "bi-mi-kee"), which uses bi-capacities to represent the interactions between pairs of subsets of the input sensor sources on a bi-polar scale. This allows for extended non-linear interactions between the sensor sources and can lead to interesting fusion results. Bi-MIChI also addresses label uncertainty through Multiple Instance Learning, where training labels are applied to "bags" (sets) of data instead of per-instance. Our proposed Bi-MIChI framework shows effective classification and detection performance on both synthetic and real-world experiments for sensor fusion with label uncertainty. We also provide detailed analyses on the behavior of the fuzzy measures to demonstrate our fusion process.
MambaST: A Plug-and-Play Cross-Spectral Spatial-Temporal Fuser for Efficient Pedestrian Detection
Aug 02, 2024This paper proposes MambaST, a plug-and-play cross-spectral spatial-temporal fusion pipeline for efficient pedestrian detection. Several challenges exist for pedestrian detection in autonomous driving applications. First, it is difficult to perform accurate detection using RGB cameras under dark or low-light conditions. Cross-spectral systems must be developed to integrate complementary information from multiple sensor modalities, such as thermal and visible cameras, to improve the robustness of the detections. Second, pedestrian detection models are latency-sensitive. Efficient and easy-to-scale detection models with fewer parameters are highly desirable for real-time applications such as autonomous driving. Third, pedestrian video data provides spatial-temporal correlations of pedestrian movement. It is beneficial to incorporate temporal as well as spatial information to enhance pedestrian detection. This work leverages recent advances in the state space model (Mamba) and proposes a novel Multi-head Hierarchical Patching and Aggregation (MHHPA) structure to extract both fine-grained and coarse-grained information from both RGB and thermal imagery. Experimental results show that the proposed MHHPA is an effective and efficient alternative to a Transformer model for cross-spectral pedestrian detection. Our proposed model also achieves superior performance on small-scale pedestrian detection. The code is available at https://github.com/XiangboGaoBarry/MambaST}{https://github.com/XiangboGaoBarry/MambaST.
Efficient Multi-Resolution Fusion for Remote Sensing Data with Label Uncertainty
Feb 07, 2024



Multi-modal sensor data fusion takes advantage of complementary or reinforcing information from each sensor and can boost overall performance in applications such as scene classification and target detection. This paper presents a new method for fusing multi-modal and multi-resolution remote sensor data without requiring pixel-level training labels, which can be difficult to obtain. Previously, we developed a Multiple Instance Multi-Resolution Fusion (MIMRF) framework that addresses label uncertainty for fusion, but it can be slow to train due to the large search space for the fuzzy measures used to integrate sensor data sources. We propose a new method based on binary fuzzy measures, which reduces the search space and significantly improves the efficiency of the MIMRF framework. We present experimental results on synthetic data and a real-world remote sensing detection task and show that the proposed MIMRF-BFM algorithm can effectively and efficiently perform multi-resolution fusion given remote sensing data with uncertainty.
BiPOCO: Bi-Directional Trajectory Prediction with Pose Constraints for Pedestrian Anomaly Detection
Jul 05, 2022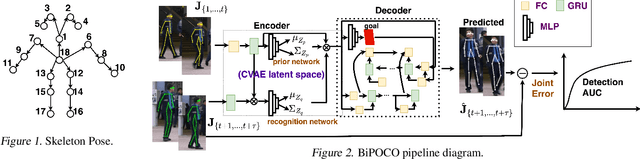
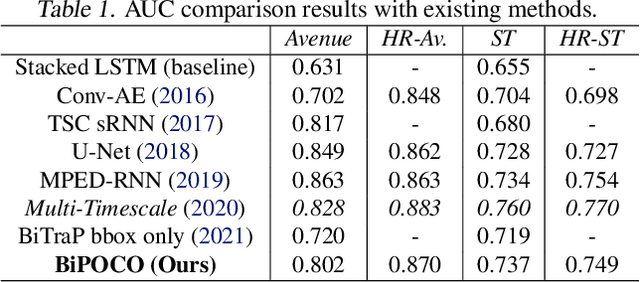
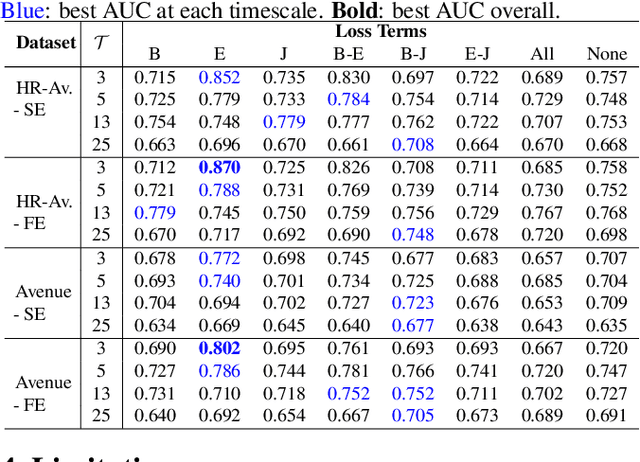
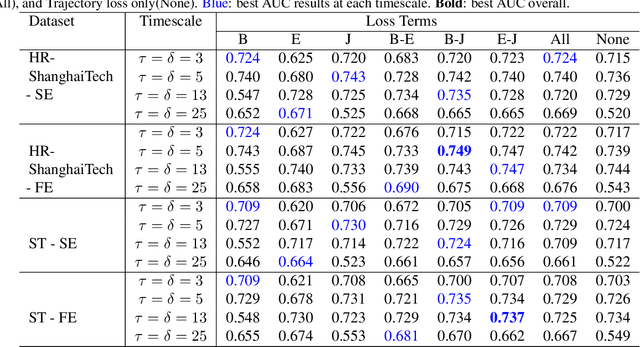
We present BiPOCO, a Bi-directional trajectory predictor with POse COnstraints, for detecting anomalous activities of pedestrians in videos. In contrast to prior work based on feature reconstruction, our work identifies pedestrian anomalous events by forecasting their future trajectories and comparing the predictions with their expectations. We introduce a set of novel compositional pose-based losses with our predictor and leverage prediction errors of each body joint for pedestrian anomaly detection. Experimental results show that our BiPOCO approach can detect pedestrian anomalous activities with a high detection rate (up to 87.0%) and incorporating pose constraints helps distinguish normal and anomalous poses in prediction. This work extends current literature of using prediction-based methods for anomaly detection and can benefit safety-critical applications such as autonomous driving and surveillance. Code is available at https://github.com/akanuasiegbu/BiPOCO.
Leveraging Trajectory Prediction for Pedestrian Video Anomaly Detection
Jul 05, 2022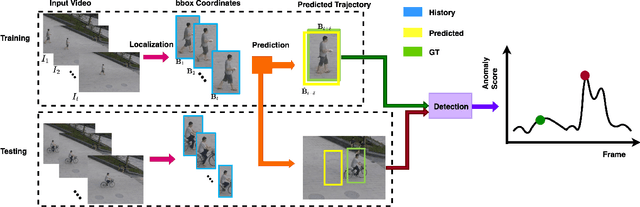
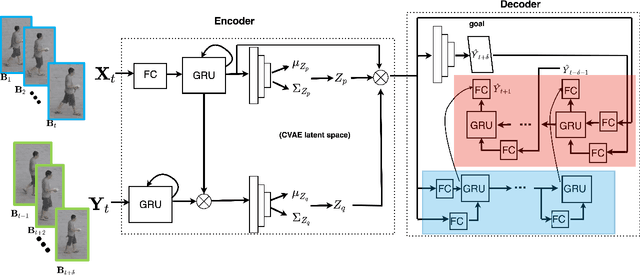

Video anomaly detection is a core problem in vision. Correctly detecting and identifying anomalous behaviors in pedestrians from video data will enable safety-critical applications such as surveillance, activity monitoring, and human-robot interaction. In this paper, we propose to leverage trajectory localization and prediction for unsupervised pedestrian anomaly event detection. Different than previous reconstruction-based approaches, our proposed framework rely on the prediction errors of normal and abnormal pedestrian trajectories to detect anomalies spatially and temporally. We present experimental results on real-world benchmark datasets on varying timescales and show that our proposed trajectory-predictor-based anomaly detection pipeline is effective and efficient at identifying anomalous activities of pedestrians in videos. Code will be made available at https://github.com/akanuasiegbu/Leveraging-Trajectory-Prediction-for-Pedestrian-Video-Anomaly-Detection.
Coupling Intent and Action for Pedestrian Crossing Behavior Prediction
May 10, 2021
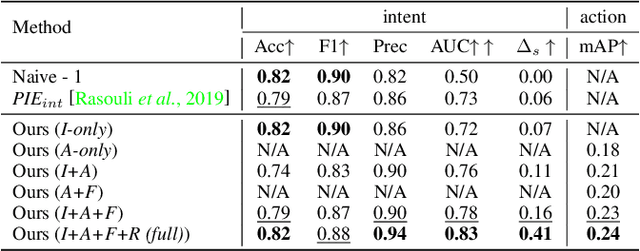
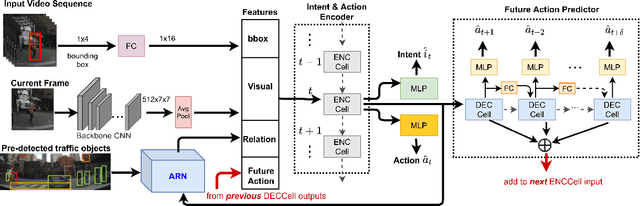
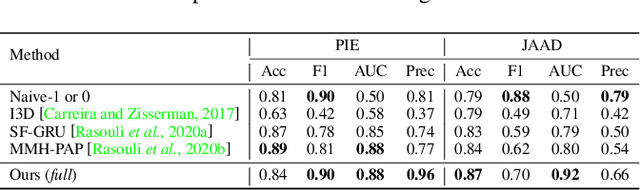
Accurate prediction of pedestrian crossing behaviors by autonomous vehicles can significantly improve traffic safety. Existing approaches often model pedestrian behaviors using trajectories or poses but do not offer a deeper semantic interpretation of a person's actions or how actions influence a pedestrian's intention to cross in the future. In this work, we follow the neuroscience and psychological literature to define pedestrian crossing behavior as a combination of an unobserved inner will (a probabilistic representation of binary intent of crossing vs. not crossing) and a set of multi-class actions (e.g., walking, standing, etc.). Intent generates actions, and the future actions in turn reflect the intent. We present a novel multi-task network that predicts future pedestrian actions and uses predicted future action as a prior to detect the present intent and action of the pedestrian. We also designed an attention relation network to incorporate external environmental contexts thus further improve intent and action detection performance. We evaluated our approach on two naturalistic driving datasets, PIE and JAAD, and extensive experiments show significantly improved and more explainable results for both intent detection and action prediction over state-of-the-art approaches. Our code is available at: https://github.com/umautobots/pedestrian_intent_action_detection.
BiTraP: Bi-directional Pedestrian Trajectory Prediction with Multi-modal Goal Estimation
Jul 29, 2020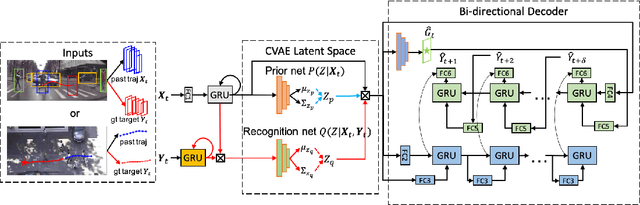
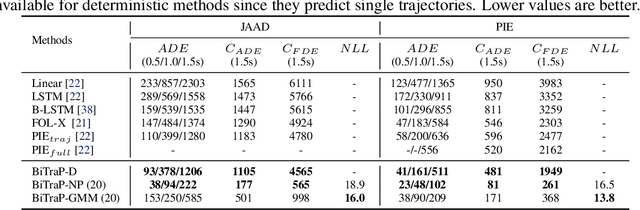
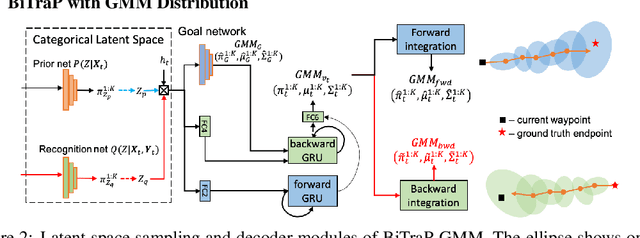
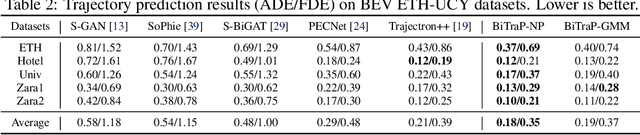
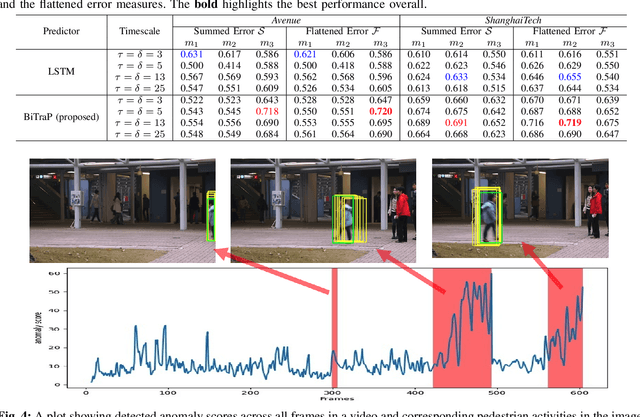
Pedestrian trajectory prediction is an essential task in robotic applications such as autonomous driving and robot navigation. State-of-the-art trajectory predictors use a conditional variational autoencoder (CVAE) with recurrent neural networks (RNNs) to encode observed trajectories and decode multi-modal future trajectories. This process can suffer from accumulated errors over long prediction horizons (>=2 seconds). This paper presents BiTraP, a goal-conditioned bi-directional multi-modal trajectory prediction method based on the CVAE. BiTraP estimates the goal (end-point) of trajectories and introduces a novel bi-directional decoder to improve longer-term trajectory prediction accuracy. Extensive experiments show that BiTraP generalizes to both first-person view (FPV) and bird's-eye view (BEV) scenarios and outperforms state-of-the-art results by ~10-50%. We also show that different choices of non-parametric versus parametric target models in the CVAE directly influence the predicted multi-modal trajectory distributions. These results provide guidance on trajectory predictor design for robotic applications such as collision avoidance and navigation systems.
Stochastic Sampling Simulation for Pedestrian Trajectory Prediction
Mar 05, 2019
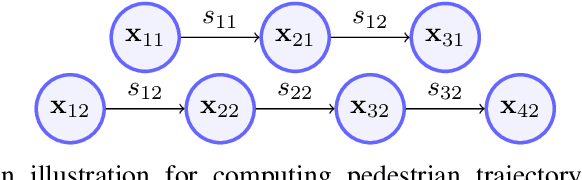

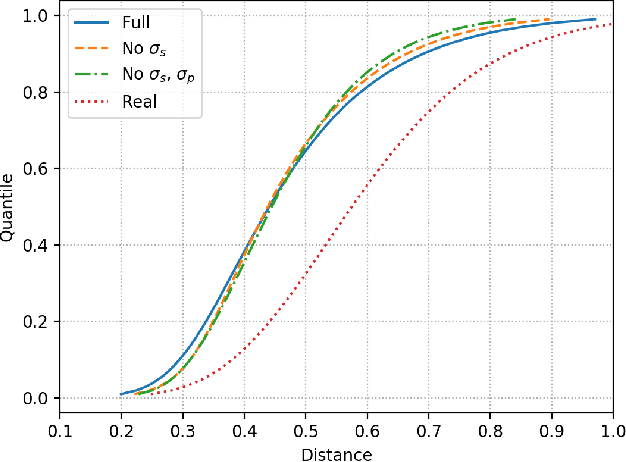
Urban environments pose a significant challenge for autonomous vehicles (AVs) as they must safely navigate while in close proximity to many pedestrians. It is crucial for the AV to correctly understand and predict the future trajectories of pedestrians to avoid collision and plan a safe path. Deep neural networks (DNNs) have shown promising results in accurately predicting pedestrian trajectories, relying on large amounts of annotated real-world data to learn pedestrian behavior. However, collecting and annotating these large real-world pedestrian datasets is costly in both time and labor. This paper describes a novel method using a stochastic sampling-based simulation to train DNNs for pedestrian trajectory prediction with social interaction. Our novel simulation method can generate vast amounts of automatically-annotated, realistic, and naturalistic synthetic pedestrian trajectories based on small amounts of real annotation. We then use such synthetic trajectories to train an off-the-shelf state-of-the-art deep learning approach Social GAN (Generative Adversarial Network) to perform pedestrian trajectory prediction. Our proposed architecture, trained only using synthetic trajectories, achieves better prediction results compared to those trained on human-annotated real-world data using the same network. Our work demonstrates the effectiveness and potential of using simulation as a substitution for human annotation efforts to train high-performing prediction algorithms such as the DNNs.
Bio-LSTM: A Biomechanically Inspired Recurrent Neural Network for 3D Pedestrian Pose and Gait Prediction
Feb 18, 2019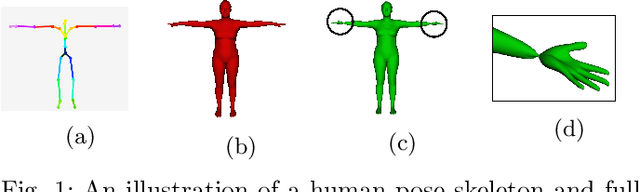
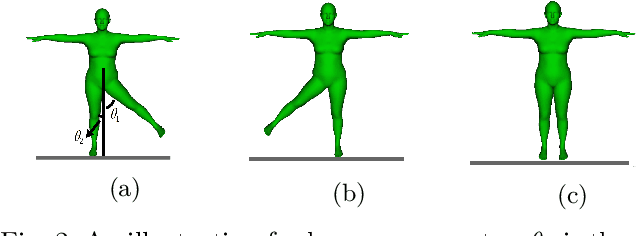
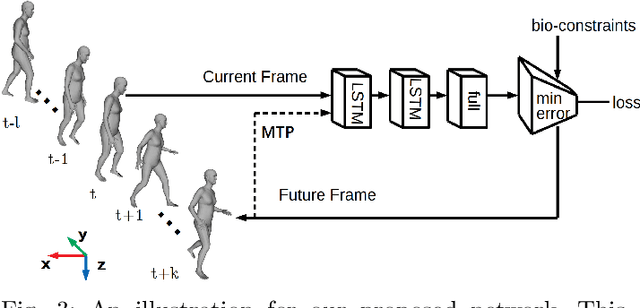

In applications such as autonomous driving, it is important to understand, infer, and anticipate the intention and future behavior of pedestrians. This ability allows vehicles to avoid collisions and improve ride safety and quality. This paper proposes a biomechanically inspired recurrent neural network (Bio-LSTM) that can predict the location and 3D articulated body pose of pedestrians in a global coordinate frame, given 3D poses and locations estimated in prior frames with inaccuracy. The proposed network is able to predict poses and global locations for multiple pedestrians simultaneously, for pedestrians up to 45 meters from the cameras (urban intersection scale). The outputs of the proposed network are full-body 3D meshes represented in Skinned Multi-Person Linear (SMPL) model parameters. The proposed approach relies on a novel objective function that incorporates the periodicity of human walking (gait), the mirror symmetry of the human body, and the change of ground reaction forces in a human gait cycle. This paper presents prediction results on the PedX dataset, a large-scale, in-the-wild data set collected at real urban intersections with heavy pedestrian traffic. Results show that the proposed network can successfully learn the characteristics of pedestrian gait and produce accurate and consistent 3D pose predictions.