 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterNeRF: Neural Radiance Fields for Underwater Scenes
Sep 27, 2022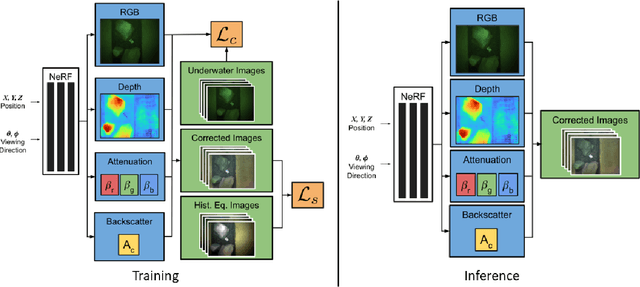



Underwater imaging is a critical task performed by marine robots for a wide range of applications including aquaculture, marine infrastructure inspection, and environmental monitoring. However, water column effects, such as attenuation and backscattering, drastically change the color and quality of imagery captured underwater. Due to varying water conditions and range-dependency of these effects, restoring underwater imagery is a challenging problem. This impacts downstream perception tasks including depth estimation and 3D reconstruction. In this paper, we advance state-of-the-art in neural radiance fields (NeRFs) to enable physics-informed dense depth estimation and color correction. Our proposed method, WaterNeRF, estimates parameters of a physics-based model for underwater image formation, leading to a hybrid data-driven and model-based solution. After determining the scene structure and radiance field, we can produce novel views of degraded as well as corrected underwater images, along with dense depth of the scene. We evaluate the proposed method qualitatively and quantitatively on a real underwater dataset.
CLONeR: Camera-Lidar Fusion for Occupancy Grid-aided Neural Representations
Sep 06, 2022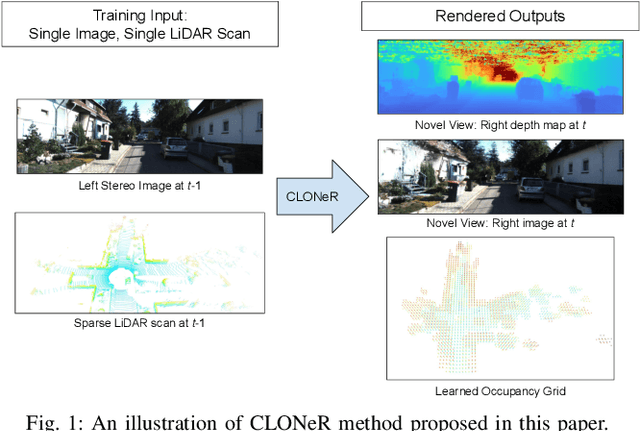

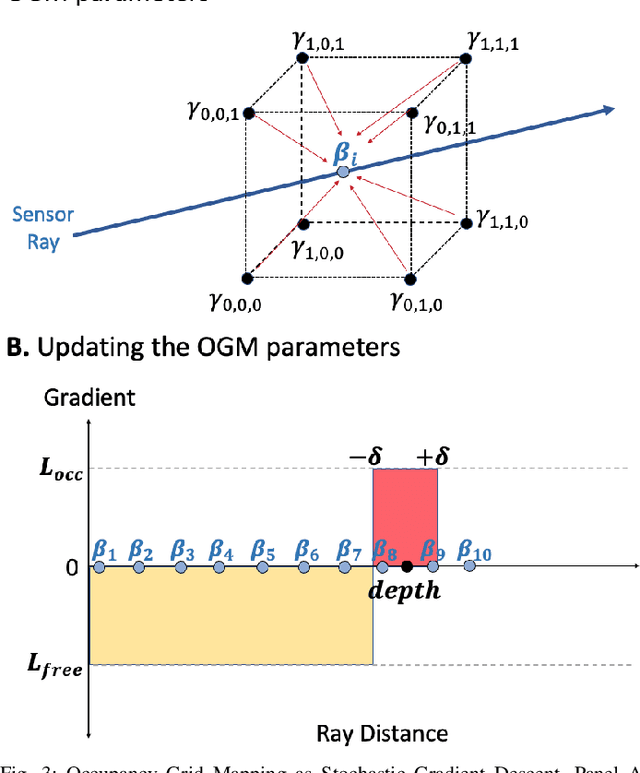

Recent advances in neural radiance fields (NeRFs) achieve state-of-the-art novel view synthesis and facilitate dense estimation of scene properties. However, NeRFs often fail for large, unbounded scenes that are captured under very sparse views with the scene content concentrated far away from the camera, as is typical for field robotics applications. In particular, NeRF-style algorithms perform poorly: (1) when there are insufficient views with little pose diversity, (2) when scenes contain saturation and shadows, and (3) when finely sampling large unbounded scenes with fine structures becomes computationally intensive. This paper proposes CLONeR, which significantly improves upon NeRF by allowing it to model large outdoor driving scenes that are observed from sparse input sensor views. This is achieved by decoupling occupancy and color learning within the NeRF framework into separate Multi-Layer Perceptrons (MLPs) trained using LiDAR and camera data, respectively. In addition, this paper proposes a novel method to build differentiable 3D Occupancy Grid Maps (OGM) alongside the NeRF model, and leverage this occupancy grid for improved sampling of points along a ray for volumetric rendering in metric space. Through extensive quantitative and qualitative experiments on scenes from the KITTI dataset, this paper demonstrates that the proposed method outperforms state-of-the-art NeRF models on both novel view synthesis and dense depth prediction tasks when trained on sparse input data.
Pixel-Wise Motion Deblurring of Thermal Videos
Jun 08, 2020

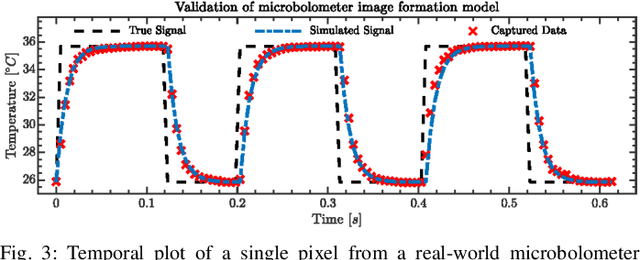
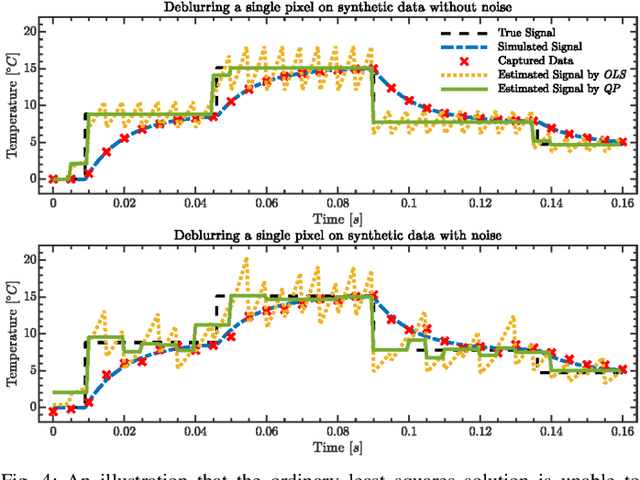
Uncooled microbolometers can enable robots to see in the absence of visible illumination by imaging the "heat" radiated from the scene. Despite this ability to see in the dark, these sensors suffer from significant motion blur. This has limited their application on robotic systems. As described in this paper, this motion blur arises due to the thermal inertia of each pixel. This has meant that traditional motion deblurring techniques, which rely on identifying an appropriate spatial blur kernel to perform spatial deconvolution, are unable to reliably perform motion deblurring on thermal camera images. To address this problem, this paper formulates reversing the effect of thermal inertia at a single pixel as a Least Absolute Shrinkage and Selection Operator (LASSO) problem which we can solve rapidly using a quadratic programming solver. By leveraging sparsity and a high frame rate, this pixel-wise LASSO formulation is able to recover motion deblurred frames of thermal videos without using any spatial information. To compare its quality against state-of-the-art visible camera based deblurring methods, this paper evaluated the performance of a family of pre-trained object detectors on a set of images restored by different deblurring algorithms. All evaluated object detectors performed systematically better on images restored by the proposed algorithm rather than any other tested, state-of-the-art methods.
PedX: Benchmark Dataset for Metric 3D Pose Estimation of Pedestrians in Complex Urban Intersections
Sep 10, 2018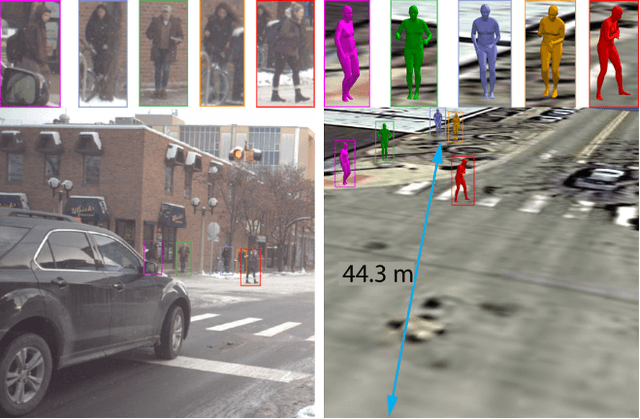
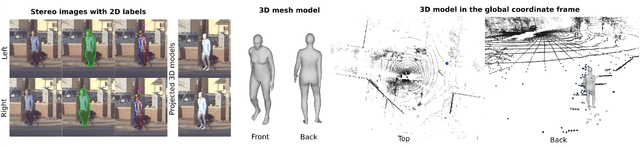
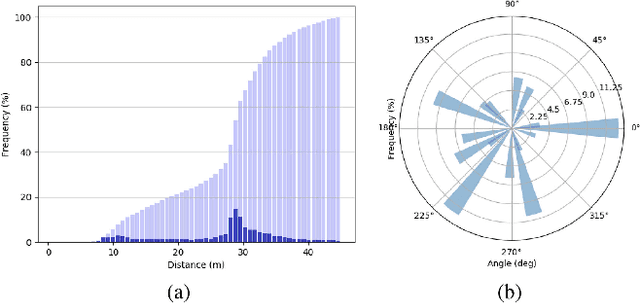

This paper presents a novel dataset titled PedX, a large-scale multimodal collection of pedestrians at complex urban intersections. PedX consists of more than 5,000 pairs of high-resolution (12MP) stereo images and LiDAR data along with providing 2D and 3D labels of pedestrians. We also present a novel 3D model fitting algorithm for automatic 3D labeling harnessing constraints across different modalities and novel shape and temporal priors. All annotated 3D pedestrians are localized into the real-world metric space, and the generated 3D models are validated using a mocap system configured in a controlled outdoor environment to simulate pedestrians in urban intersections. We also show that the manual 2D labels can be replaced by state-of-the-art automated labeling approaches, thereby facilitating automatic generation of large scale datasets.
Failing to Learn: Autonomously Identifying Perception Failures for Self-driving Cars
Jul 26, 2018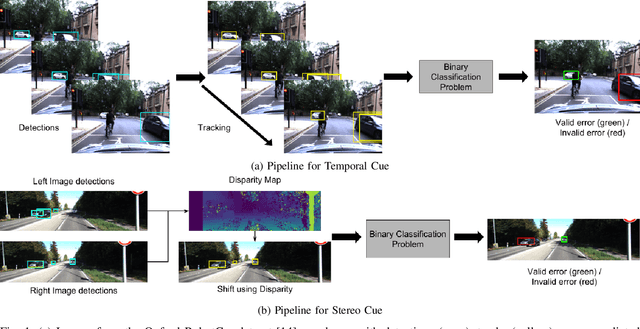
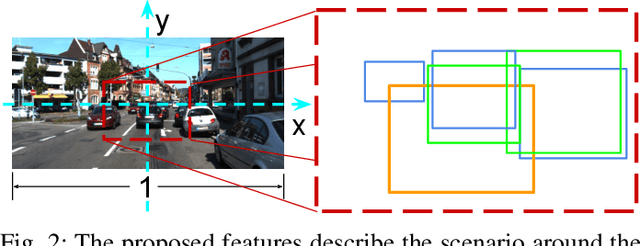
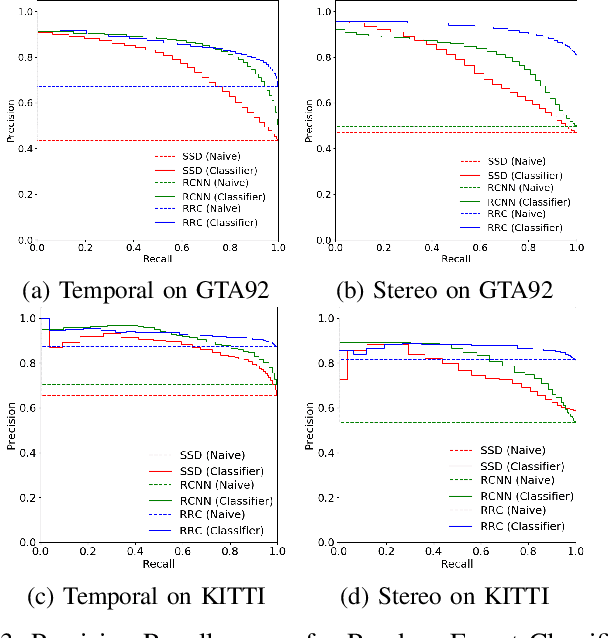
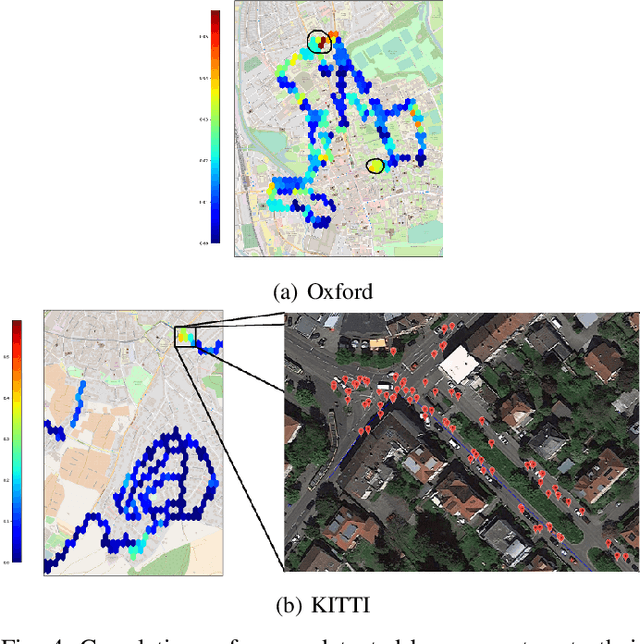
One of the major open challenges in self-driving cars is the ability to detect cars and pedestrians to safely navigate in the world. Deep learning-based object detector approaches have enabled great advances in using camera imagery to detect and classify objects. But for a safety critical application, such as autonomous driving, the error rates of the current state of the art are still too high to enable safe operation. Moreover, the characterization of object detector performance is primarily limited to testing on prerecorded datasets. Errors that occur on novel data go undetected without additional human labels. In this letter, we propose an automated method to identify mistakes made by object detectors without ground truth labels. We show that inconsistencies in the object detector output between a pair of similar images can be used as hypotheses for false negatives (e.g., missed detections) and using a novel set of features for each hypothesis, an off-the-shelf binary classifier can be used to find valid errors. In particular, we study two distinct cues - temporal and stereo inconsistencies - using data that are readily available on most autonomous vehicles. Our method can be used with any camera-based object detector and we illustrate the technique on several sets of real world data. We show that a state-of-the-art detector, tracker, and our classifier trained only on synthetic data can identify valid errors on KITTI tracking dataset with an average precision of 0.94. We also release a new tracking dataset with 104 sequences totaling 80,655 labeled pairs of stereo images along with ground truth disparity from a game engine to facilitate further research. The dataset and code are available at https://fcav.engin.umich.edu/research/failing-to-learn
A Motion Planning Strategy for the Active Vision-Based Mapping of Ground-Level Structures
Nov 11, 2017



This paper presents a strategy to guide a mobile ground robot equipped with a camera or depth sensor, in order to autonomously map the visible part of a bounded three-dimensional structure. We describe motion planning algorithms that determine appropriate successive viewpoints and attempt to fill holes automatically in a point cloud produced by the sensing and perception layer. The emphasis is on accurately reconstructing a 3D model of a structure of moderate size rather than mapping large open environments, with applications for example in architecture, construction and inspection. The proposed algorithms do not require any initialization in the form of a mesh model or a bounding box, and the paths generated are well adapted to situations where the vision sensor is used simultaneously for mapping and for localizing the robot, in the absence of additional absolute positioning system. We analyze the coverage properties of our policy, and compare its performance to the classic frontier based exploration algorithm. We illustrate its efficacy for different structure sizes, levels of localization accuracy and range of the depth sensor, and validate our design on a real-world experiment.