 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Visual Odometry with Deep Learning-Based Point and Line Feature Matching using an Attention Graph Neural Network
Aug 02, 2023



Robust feature matching forms the backbone for most Visual Simultaneous Localization and Mapping (vSLAM), visual odometry, 3D reconstruction, and Structure from Motion (SfM) algorithms. However, recovering feature matches from texture-poor scenes is a major challenge and still remains an open area of research. In this paper, we present a Stereo Visual Odometry (StereoVO) technique based on point and line features which uses a novel feature-matching mechanism based on an Attention Graph Neural Network that is designed to perform well even under adverse weather conditions such as fog, haze, rain, and snow, and dynamic lighting conditions such as nighttime illumination and glare scenarios. We perform experiments on multiple real and synthetic datasets to validate the ability of our method to perform StereoVO under low visibility weather and lighting conditions through robust point and line matches. The results demonstrate that our method achieves more line feature matches than state-of-the-art line matching algorithms, which when complemented with point feature matches perform consistently well in adverse weather and dynamic lighting conditions.
LiSnowNet: Real-time Snow Removal for LiDAR Point Cloud
Nov 18, 2022LiDARs have been widely adopted to modern self-driving vehicles, providing 3D information of the scene and surrounding objects. However, adverser weather conditions still pose significant challenges to LiDARs since point clouds captured during snowfall can easily be corrupted. The resulting noisy point clouds degrade downstream tasks such as mapping. Existing works in de-noising point clouds corrupted by snow are based on nearest-neighbor search, and thus do not scale well with modern LiDARs which usually capture $100k$ or more points at 10Hz. In this paper, we introduce an unsupervised de-noising algorithm, LiSnowNet, running 52$\times$ faster than the state-of-the-art methods while achieving superior performance in de-noising. Unlike previous methods, the proposed algorithm is based on a deep convolutional neural network and can be easily deployed to hardware accelerators such as GPUs. In addition, we demonstrate how to use the proposed method for mapping even with corrupted point clouds.
Learning Rotation-Invariant Representations of Point Clouds Using Aligned Edge Convolutional Neural Networks
Jan 02, 2021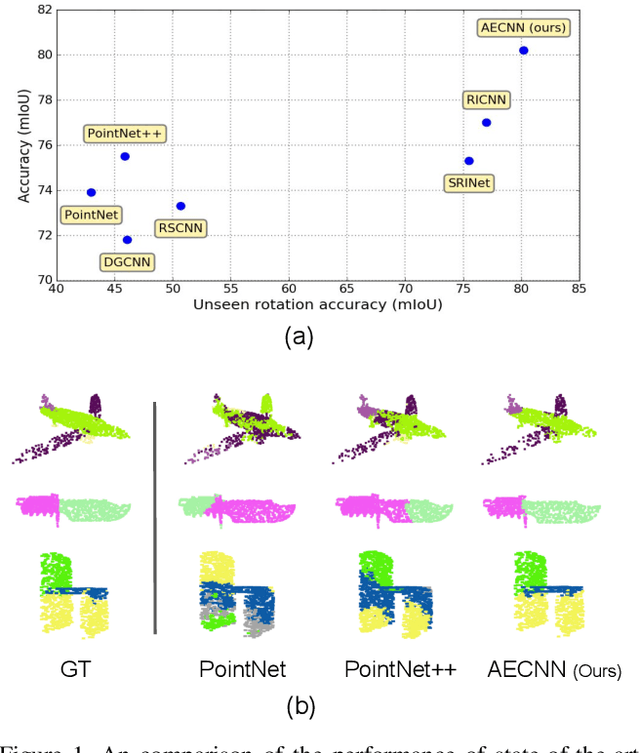
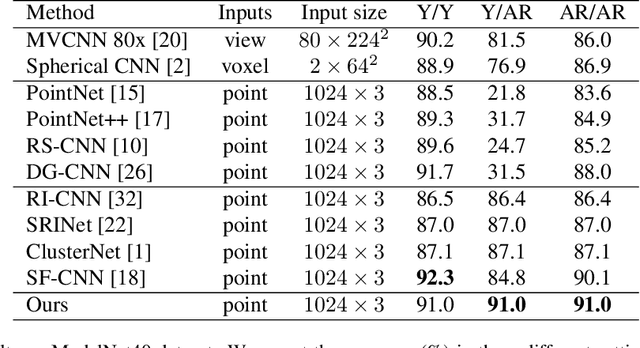
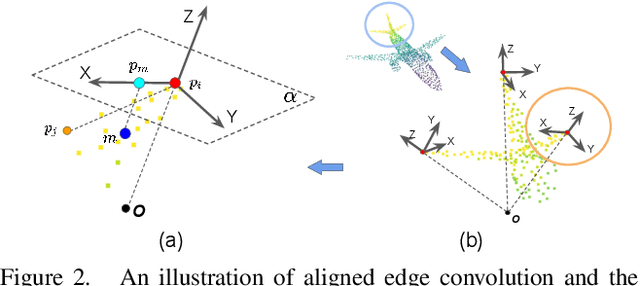
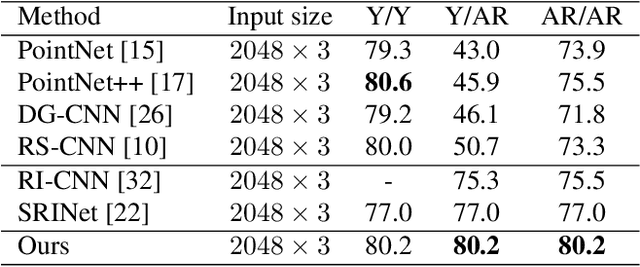
Point cloud analysis is an area of increasing interest due to the development of 3D sensors that are able to rapidly measure the depth of scenes accurately. Unfortunately, applying deep learning techniques to perform point cloud analysis is non-trivial due to the inability of these methods to generalize to unseen rotations. To address this limitation, one usually has to augment the training data, which can lead to extra computation and require larger model complexity. This paper proposes a new neural network called the Aligned Edge Convolutional Neural Network (AECNN) that learns a feature representation of point clouds relative to Local Reference Frames (LRFs) to ensure invariance to rotation. In particular, features are learned locally and aligned with respect to the LRF of an automatically computed reference point. The proposed approach is evaluated on point cloud classification and part segmentation tasks. This paper illustrates that the proposed technique outperforms a variety of state of the art approaches (even those trained on augmented datasets) in terms of robustness to rotation without requiring any additional data augmentation.
Risk Assessment and Planning with Bidirectional Reachability for Autonomous Driving
Sep 17, 2019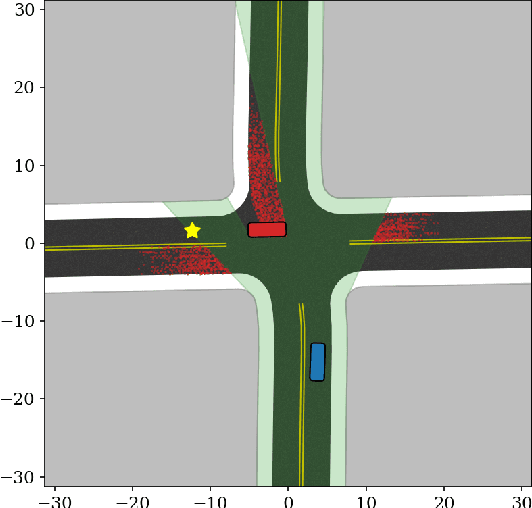
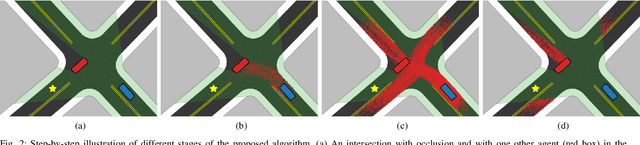
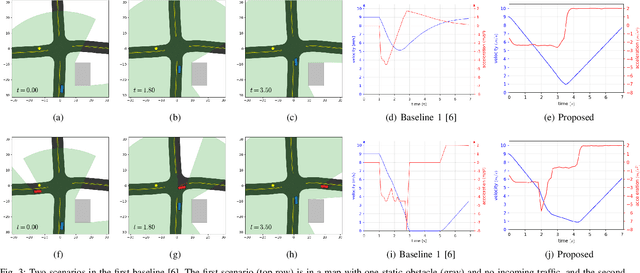
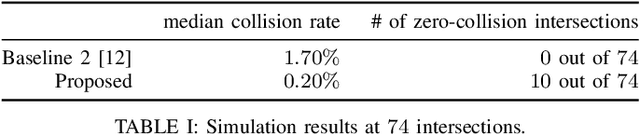
Knowing and predicting dangerous factors within a scene are two key components during autonomous driving, especially in a crowded urban environment. To navigate safely in environments, risk assessment is needed to quantify and associate the risk of taking a certain action. Risk assessment and planning is usually done by first tracking and predicting trajectories of other agents, such as vehicles and pedestrians, and then choosing an action to avoid collision in the future. However, few existing risk assessment algorithms handle occlusion and other sensory limitations effectively. This paper explores the possibility of efficient risk assessment under occlusion via both forward and backward reachability. The proposed algorithm can not only identify where the risk-induced factors are, but also be used for motion planning by executing low-level commands, such as throttle. The proposed method is evaluated on various four-way highly occluded intersections with up to five other vehicles in the scene. Compared with other risk assessment algorithms, the proposed method shows better efficiency, meaning that the ego vehicle reaches the goal at a higher speed. In addition, it also lowers the median collision rate by 7.5x.
Occlusion-Aware Risk Assessment for Autonomous Driving in Urban Environments
Sep 12, 2018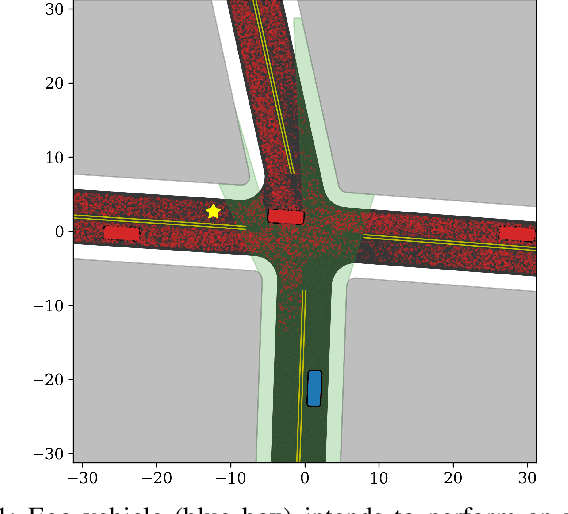

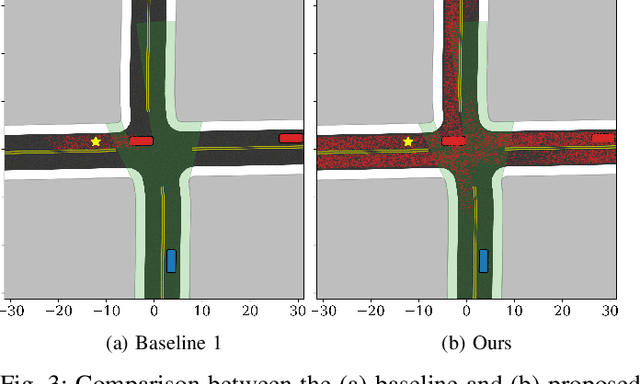
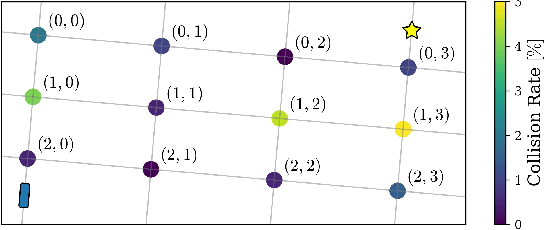
Navigating safely in urban environments remains a challenging problem for autonomous vehicles. Occlusion and limited sensor range can pose significant challenges to safely navigate among pedestrians and other vehicles in the environment. Enabling vehicles to quantify the risk posed by unseen regions allows them to anticipate future possibilities, resulting in increased safety and ride comfort. This paper proposes an algorithm that takes advantage of the known road layouts to forecast, quantify, and aggregate risk associated with occlusions and limited sensor range. This allows us to make predictions of risk induced by unobserved vehicles even in heavily occluded urban environments. The risk can then be used either by a low-level planning algorithm to generate better trajectories, or by a high-level one to plan a better route. The proposed algorithm is evaluated on intersection layouts from real-world map data with up to five other vehicles in the scene, and verified to reduce collision rates by 4.8x comparing to a baseline method while improving driving comfort.
PedX: Benchmark Dataset for Metric 3D Pose Estimation of Pedestrians in Complex Urban Intersections
Sep 10, 2018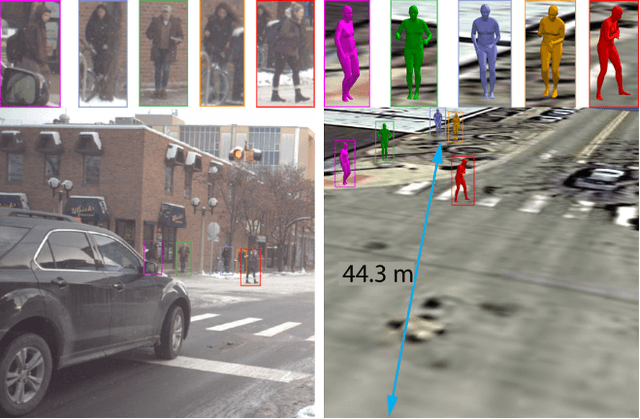
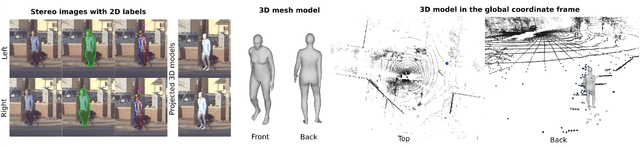

This paper presents a novel dataset titled PedX, a large-scale multimodal collection of pedestrians at complex urban intersections. PedX consists of more than 5,000 pairs of high-resolution (12MP) stereo images and LiDAR data along with providing 2D and 3D labels of pedestrians. We also present a novel 3D model fitting algorithm for automatic 3D labeling harnessing constraints across different modalities and novel shape and temporal priors. All annotated 3D pedestrians are localized into the real-world metric space, and the generated 3D models are validated using a mocap system configured in a controlled outdoor environment to simulate pedestrians in urban intersections. We also show that the manual 2D labels can be replaced by state-of-the-art automated labeling approaches, thereby facilitating automatic generation of large scale datasets.