 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Visual Odometry with Deep Learning-Based Point and Line Feature Matching using an Attention Graph Neural Network
Aug 02, 2023



Robust feature matching forms the backbone for most Visual Simultaneous Localization and Mapping (vSLAM), visual odometry, 3D reconstruction, and Structure from Motion (SfM) algorithms. However, recovering feature matches from texture-poor scenes is a major challenge and still remains an open area of research. In this paper, we present a Stereo Visual Odometry (StereoVO) technique based on point and line features which uses a novel feature-matching mechanism based on an Attention Graph Neural Network that is designed to perform well even under adverse weather conditions such as fog, haze, rain, and snow, and dynamic lighting conditions such as nighttime illumination and glare scenarios. We perform experiments on multiple real and synthetic datasets to validate the ability of our method to perform StereoVO under low visibility weather and lighting conditions through robust point and line matches. The results demonstrate that our method achieves more line feature matches than state-of-the-art line matching algorithms, which when complemented with point feature matches perform consistently well in adverse weather and dynamic lighting conditions.
GraffMatch: Global Matching of 3D Lines and Planes for Wide Baseline LiDAR Registration
Dec 24, 2022Using geometric landmarks like lines and planes can increase navigation accuracy and decrease map storage requirements compared to commonly-used LiDAR point cloud maps. However, landmark-based registration for applications like loop closure detection is challenging because a reliable initial guess is not available. Global landmark matching has been investigated in the literature, but these methods typically use ad hoc representations of 3D line and plane landmarks that are not invariant to large viewpoint changes, resulting in incorrect matches and high registration error. To address this issue, we adopt the affine Grassmannian manifold to represent 3D lines and planes and prove that the distance between two landmarks is invariant to rotation and translation if a shift operation is performed before applying the Grassmannian metric. This invariance property enables the use of our graph-based data association framework for identifying landmark matches that can subsequently be used for registration in the least-squares sense. Evaluated on a challenging landmark matching and registration task using publicly-available LiDAR datasets, our approach yields a 1.7x and 3.5x improvement in successful registrations compared to methods that use viewpoint-dependent centroid and "closest point" representations, respectively.
* accepted to RA-L; 8 pages. arXiv admin note: text overlap with arXiv:2205.08556
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021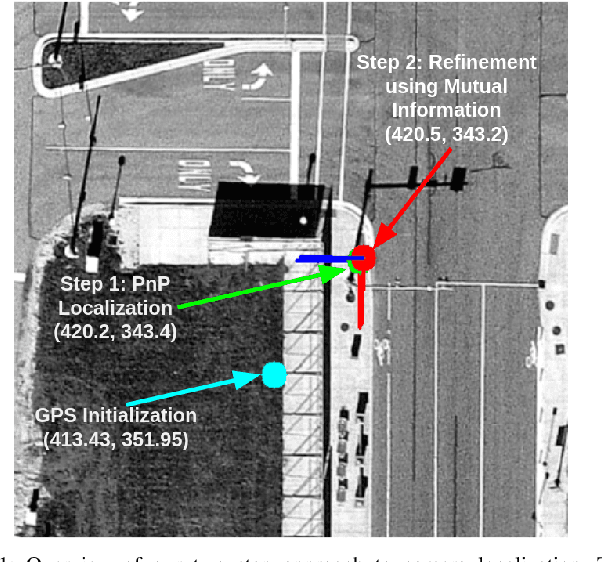


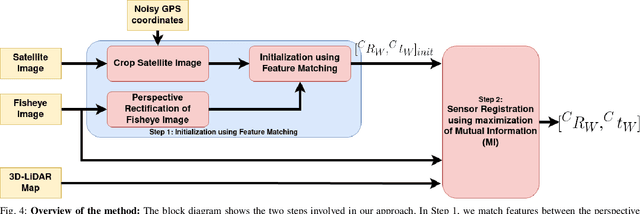
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.