 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCAL: A Cost-Aware Video Dataset for Active Learning
Nov 17, 2023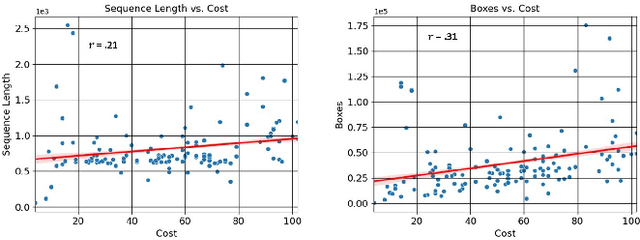
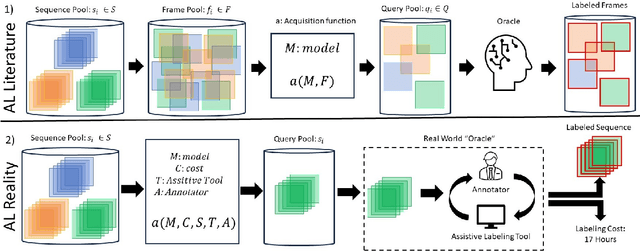
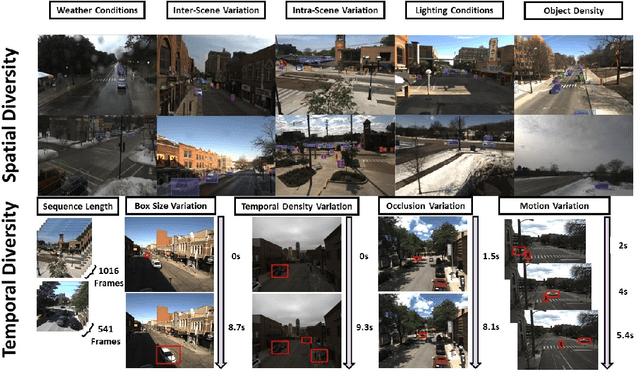
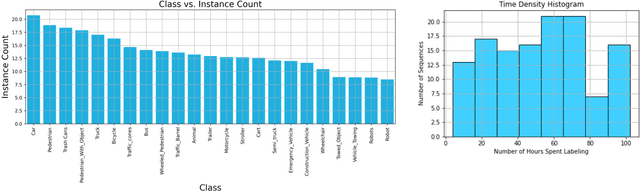
In this paper, we introduce the FOCAL (Ford-OLIVES Collaboration on Active Learning) dataset which enables the study of the impact of annotation-cost within a video active learning setting. Annotation-cost refers to the time it takes an annotator to label and quality-assure a given video sequence. A practical motivation for active learning research is to minimize annotation-cost by selectively labeling informative samples that will maximize performance within a given budget constraint. However, previous work in video active learning lacks real-time annotation labels for accurately assessing cost minimization and instead operates under the assumption that annotation-cost scales linearly with the amount of data to annotate. This assumption does not take into account a variety of real-world confounding factors that contribute to a nonlinear cost such as the effect of an assistive labeling tool and the variety of interactions within a scene such as occluded objects, weather, and motion of objects. FOCAL addresses this discrepancy by providing real annotation-cost labels for 126 video sequences across 69 unique city scenes with a variety of weather, lighting, and seasonal conditions. We also introduce a set of conformal active learning algorithms that take advantage of the sequential structure of video data in order to achieve a better trade-off between annotation-cost and performance while also reducing floating point operations (FLOPS) overhead by at least 77.67%. We show how these approaches better reflect how annotations on videos are done in practice through a sequence selection framework. We further demonstrate the advantage of these approaches by introducing two performance-cost metrics and show that the best conformal active learning method is cheaper than the best traditional active learning method by 113 hours.
Gaussian Switch Sampling: A Second Order Approach to Active Learning
Feb 16, 2023In active learning, acquisition functions define informativeness directly on the representation position within the model manifold. However, for most machine learning models (in particular neural networks) this representation is not fixed due to the training pool fluctuations in between active learning rounds. Therefore, several popular strategies are sensitive to experiment parameters (e.g. architecture) and do not consider model robustness to out-of-distribution settings. To alleviate this issue, we propose a grounded second-order definition of information content and sample importance within the context of active learning. Specifically, we define importance by how often a neural network "forgets" a sample during training - artifacts of second order representation shifts. We show that our definition produces highly accurate importance scores even when the model representations are constrained by the lack of training data. Motivated by our analysis, we develop Gaussian Switch Sampling (GauSS). We show that GauSS is setup agnostic and robust to anomalous distributions with exhaustive experiments on three in-distribution benchmarks, three out-of-distribution benchmarks, and three different architectures. We report an improvement of up to 5% when compared against four popular query strategies.
DEVIANT: Depth EquiVarIAnt NeTwork for Monocular 3D Object Detection
Jul 21, 2022
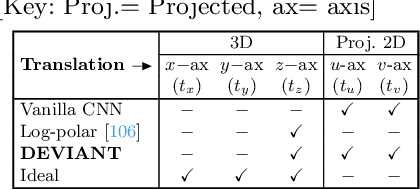
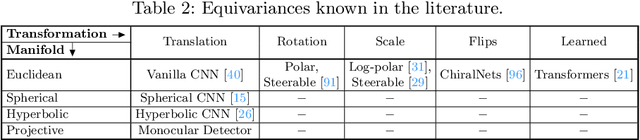
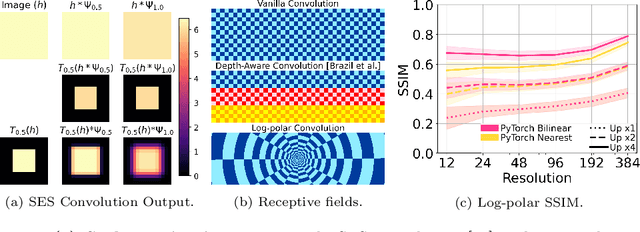
Modern neural networks use building blocks such as convolutions that are equivariant to arbitrary 2D translations. However, these vanilla blocks are not equivariant to arbitrary 3D translations in the projective manifold. Even then, all monocular 3D detectors use vanilla blocks to obtain the 3D coordinates, a task for which the vanilla blocks are not designed for. This paper takes the first step towards convolutions equivariant to arbitrary 3D translations in the projective manifold. Since the depth is the hardest to estimate for monocular detection, this paper proposes Depth EquiVarIAnt NeTwork (DEVIANT) built with existing scale equivariant steerable blocks. As a result, DEVIANT is equivariant to the depth translations in the projective manifold whereas vanilla networks are not. The additional depth equivariance forces the DEVIANT to learn consistent depth estimates, and therefore, DEVIANT achieves state-of-the-art monocular 3D detection results on KITTI and Waymo datasets in the image-only category and performs competitively to methods using extra information. Moreover, DEVIANT works better than vanilla networks in cross-dataset evaluation. Code and models at https://github.com/abhi1kumar/DEVIANT
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021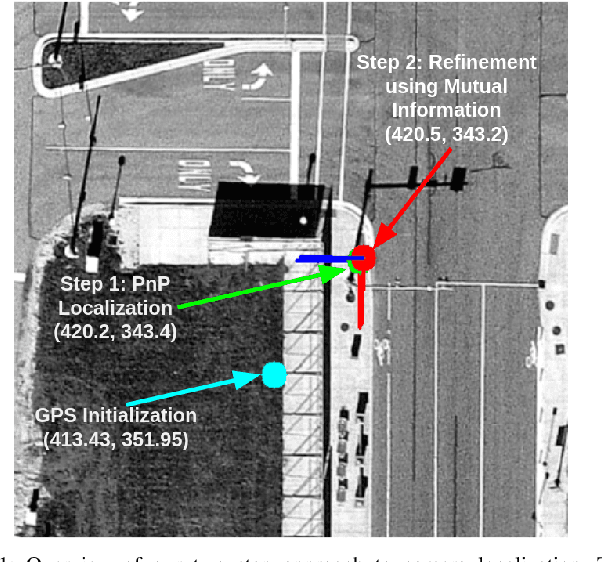


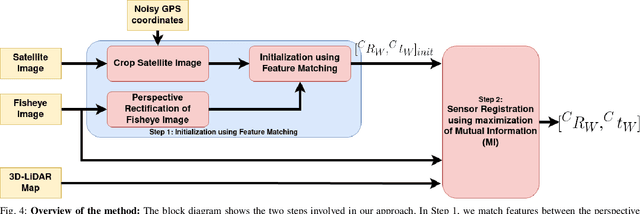
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.
Efficient data-driven encoding of scene motion using Eccentricity
Mar 03, 2021
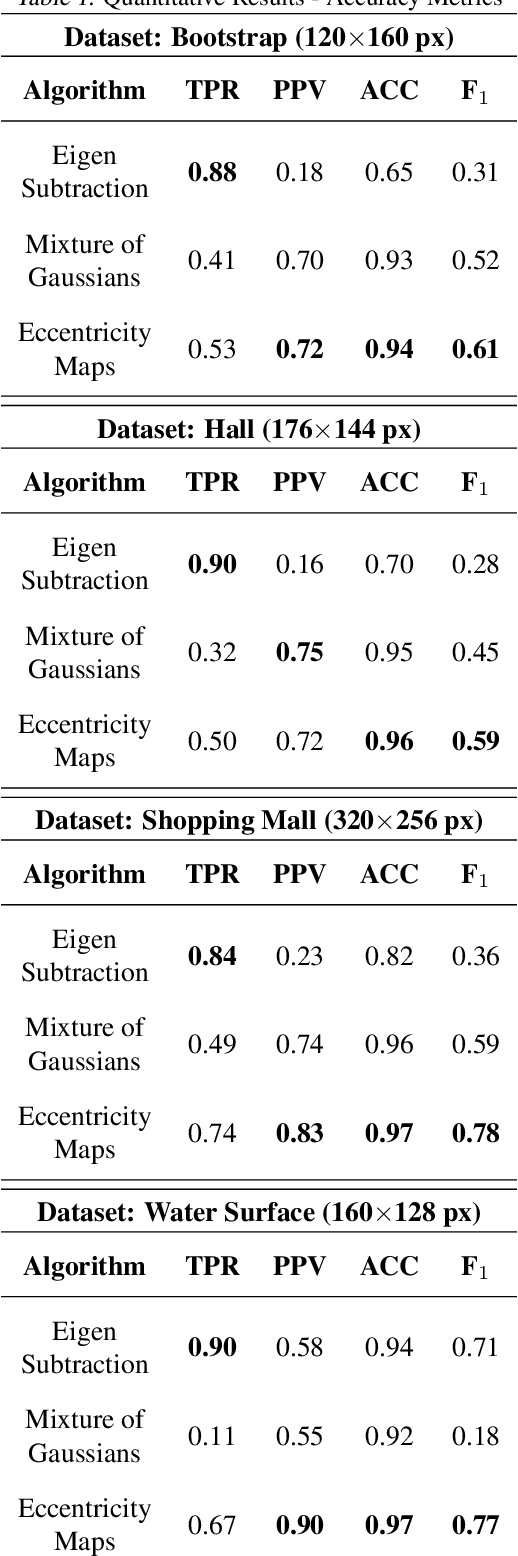

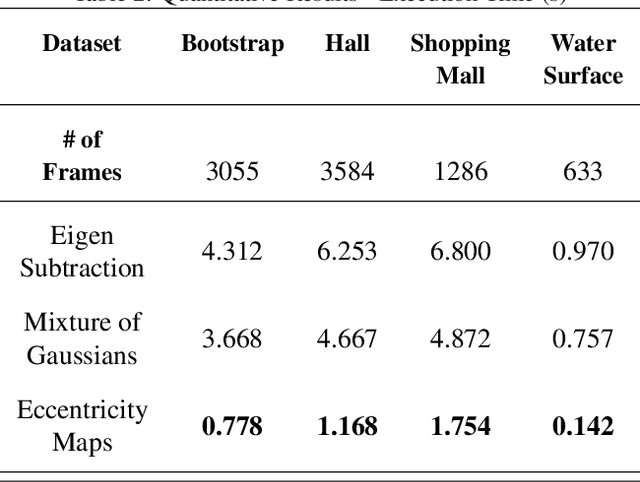
This paper presents a novel approach of representing dynamic visual scenes with static maps generated from video/image streams. Such representation allows easy visual assessment of motion in dynamic environments. These maps are 2D matrices calculated recursively, in a pixel-wise manner, that is based on the recently introduced concept of Eccentricity data analysis. Eccentricity works as a metric of a discrepancy between a particular pixel of an image and its normality model, calculated in terms of mean and variance of past readings of the same spatial region of the image. While Eccentricity maps carry temporal information about the scene, actual images do not need to be stored nor processed in batches. Rather, all the calculations are done recursively, based on a small amount of statistical information stored in memory, thus resulting in a very computationally efficient (processor- and memory-wise) method. The list of potential applications includes video-based activity recognition, intent recognition, object tracking, video description, and so on.