 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajPRed: Trajectory Prediction with Region-based Relation Learning
Apr 10, 2024


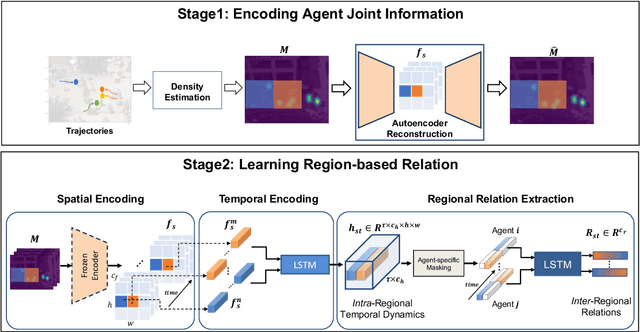
Forecasting human trajectories in traffic scenes is critical for safety within mixed or fully autonomous systems. Human future trajectories are driven by two major stimuli, social interactions, and stochastic goals. Thus, reliable forecasting needs to capture these two stimuli. Edge-based relation modeling represents social interactions using pairwise correlations from precise individual states. Nevertheless, edge-based relations can be vulnerable under perturbations. To alleviate these issues, we propose a region-based relation learning paradigm that models social interactions via region-wise dynamics of joint states, i.e., the changes in the density of crowds. In particular, region-wise agent joint information is encoded within convolutional feature grids. Social relations are modeled by relating the temporal changes of local joint information from a global perspective. We show that region-based relations are less susceptible to perturbations. In order to account for the stochastic individual goals, we exploit a conditional variational autoencoder to realize multi-goal estimation and diverse future prediction. Specifically, we perform variational inference via the latent distribution, which is conditioned on the correlation between input states and associated target goals. Sampling from the latent distribution enables the framework to reliably capture the stochastic behavior in test data. We integrate multi-goal estimation and region-based relation learning to model the two stimuli, social interactions, and stochastic goals, in a prediction framework. We evaluate our framework on the ETH-UCY dataset and Stanford Drone Dataset (SDD). We show that the diverse prediction better fits the ground truth when incorporating the relation module. Our framework outperforms the state-of-the-art models on SDD by $27.61\%$/$18.20\%$ of ADE/FDE metrics.
FOCAL: A Cost-Aware Video Dataset for Active Learning
Nov 17, 2023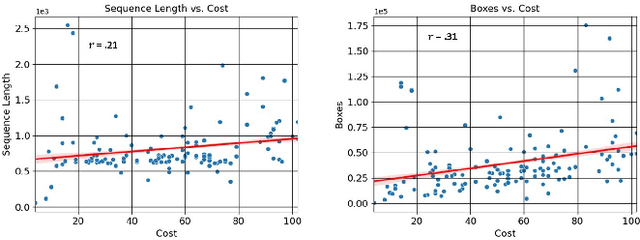
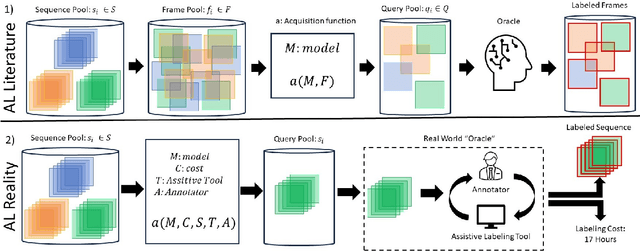
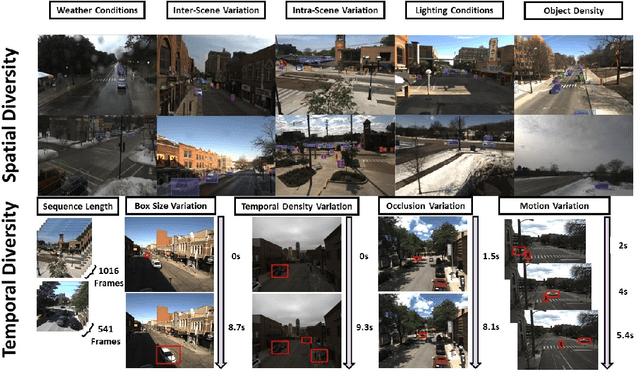
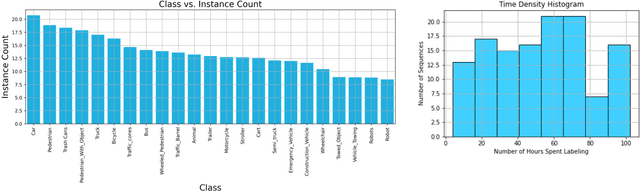
In this paper, we introduce the FOCAL (Ford-OLIVES Collaboration on Active Learning) dataset which enables the study of the impact of annotation-cost within a video active learning setting. Annotation-cost refers to the time it takes an annotator to label and quality-assure a given video sequence. A practical motivation for active learning research is to minimize annotation-cost by selectively labeling informative samples that will maximize performance within a given budget constraint. However, previous work in video active learning lacks real-time annotation labels for accurately assessing cost minimization and instead operates under the assumption that annotation-cost scales linearly with the amount of data to annotate. This assumption does not take into account a variety of real-world confounding factors that contribute to a nonlinear cost such as the effect of an assistive labeling tool and the variety of interactions within a scene such as occluded objects, weather, and motion of objects. FOCAL addresses this discrepancy by providing real annotation-cost labels for 126 video sequences across 69 unique city scenes with a variety of weather, lighting, and seasonal conditions. We also introduce a set of conformal active learning algorithms that take advantage of the sequential structure of video data in order to achieve a better trade-off between annotation-cost and performance while also reducing floating point operations (FLOPS) overhead by at least 77.67%. We show how these approaches better reflect how annotations on videos are done in practice through a sequence selection framework. We further demonstrate the advantage of these approaches by introducing two performance-cost metrics and show that the best conformal active learning method is cheaper than the best traditional active learning method by 113 hours.
Learning Trajectory-Conditioned Relations to Predict Pedestrian Crossing Behavior
Jan 14, 2023
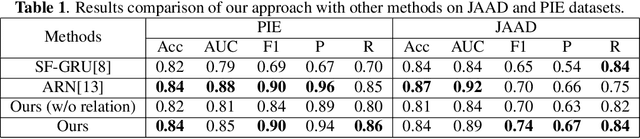
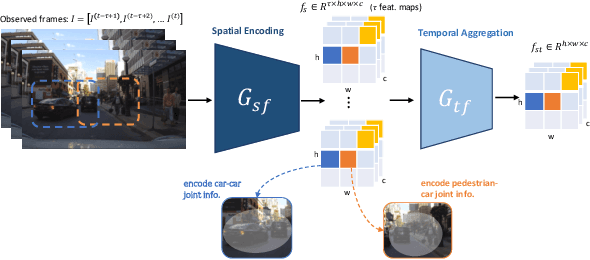

In smart transportation, intelligent systems avoid potential collisions by predicting the intent of traffic agents, especially pedestrians. Pedestrian intent, defined as future action, e.g., start crossing, can be dependent on traffic surroundings. In this paper, we develop a framework to incorporate such dependency given observed pedestrian trajectory and scene frames. Our framework first encodes regional joint information between a pedestrian and surroundings over time into feature-map vectors. The global relation representations are then extracted from pairwise feature-map vectors to estimate intent with past trajectory condition. We evaluate our approach on two public datasets and compare against two state-of-the-art approaches. The experimental results demonstrate that our method helps to inform potential risks during crossing events with 0.04 improvement in F1-score on JAAD dataset and 0.01 improvement in recall on PIE dataset. Furthermore, we conduct ablation experiments to confirm the contribution of the relation extraction in our framework.