 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajPRed: Trajectory Prediction with Region-based Relation Learning
Apr 10, 2024


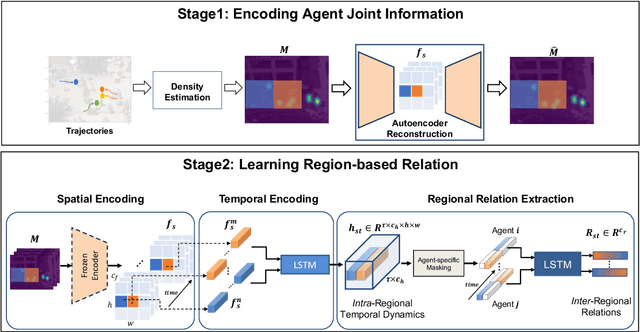
Forecasting human trajectories in traffic scenes is critical for safety within mixed or fully autonomous systems. Human future trajectories are driven by two major stimuli, social interactions, and stochastic goals. Thus, reliable forecasting needs to capture these two stimuli. Edge-based relation modeling represents social interactions using pairwise correlations from precise individual states. Nevertheless, edge-based relations can be vulnerable under perturbations. To alleviate these issues, we propose a region-based relation learning paradigm that models social interactions via region-wise dynamics of joint states, i.e., the changes in the density of crowds. In particular, region-wise agent joint information is encoded within convolutional feature grids. Social relations are modeled by relating the temporal changes of local joint information from a global perspective. We show that region-based relations are less susceptible to perturbations. In order to account for the stochastic individual goals, we exploit a conditional variational autoencoder to realize multi-goal estimation and diverse future prediction. Specifically, we perform variational inference via the latent distribution, which is conditioned on the correlation between input states and associated target goals. Sampling from the latent distribution enables the framework to reliably capture the stochastic behavior in test data. We integrate multi-goal estimation and region-based relation learning to model the two stimuli, social interactions, and stochastic goals, in a prediction framework. We evaluate our framework on the ETH-UCY dataset and Stanford Drone Dataset (SDD). We show that the diverse prediction better fits the ground truth when incorporating the relation module. Our framework outperforms the state-of-the-art models on SDD by $27.61\%$/$18.20\%$ of ADE/FDE metrics.
DatasetEquity: Are All Samples Created Equal? In The Quest For Equity Within Datasets
Aug 22, 2023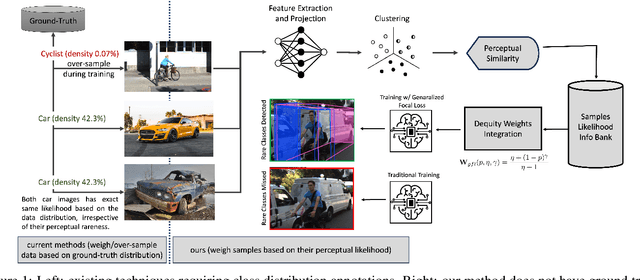

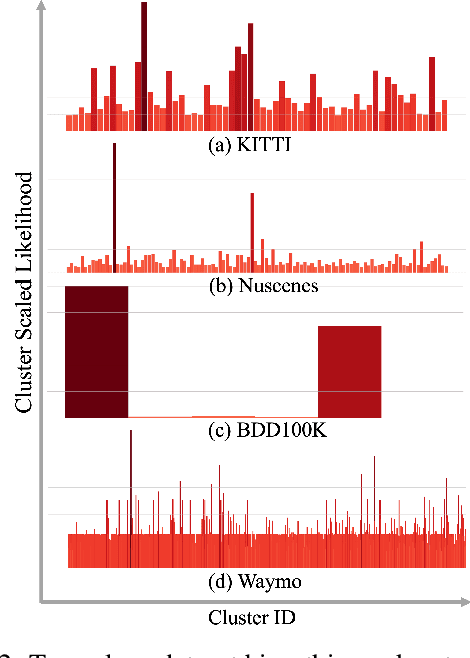
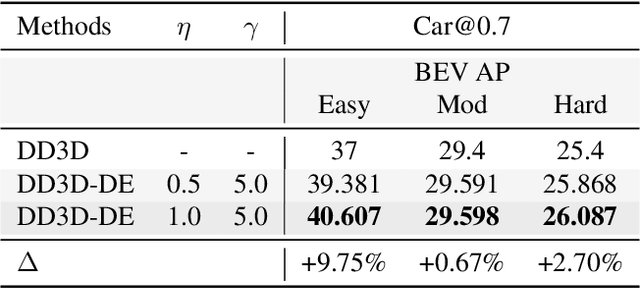
Data imbalance is a well-known issue in the field of machine learning, attributable to the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. Compared to categorical distributions using class labels, image appearance reveals complex relationships between objects beyond what class labels provide. Clustering deep perceptual features extracted from raw pixels gives a richer representation of the data. This paper presents a novel method for addressing data imbalance in machine learning. The method computes sample likelihoods based on image appearance using deep perceptual embeddings and clustering. It then uses these likelihoods to weigh samples differently during training with a proposed $\textbf{Generalized Focal Loss}$ function. This loss can be easily integrated with deep learning algorithms. Experiments validate the method's effectiveness across autonomous driving vision datasets including KITTI and nuScenes. The loss function improves state-of-the-art 3D object detection methods, achieving over $200\%$ AP gains on under-represented classes (Cyclist) in the KITTI dataset. The results demonstrate the method is generalizable, complements existing techniques, and is particularly beneficial for smaller datasets and rare classes. Code is available at: https://github.com/towardsautonomy/DatasetEquity
Exploiting the Distortion-Semantic Interaction in Fisheye Data
May 06, 2023



In this work, we present a methodology to shape a fisheye-specific representation space that reflects the interaction between distortion and semantic context present in this data modality. Fisheye data has the wider field of view advantage over other types of cameras, but this comes at the expense of high radial distortion. As a result, objects further from the center exhibit deformations that make it difficult for a model to identify their semantic context. While previous work has attempted architectural and training augmentation changes to alleviate this effect, no work has attempted to guide the model towards learning a representation space that reflects this interaction between distortion and semantic context inherent to fisheye data. We introduce an approach to exploit this relationship by first extracting distortion class labels based on an object's distance from the center of the image. We then shape a backbone's representation space with a weighted contrastive loss that constrains objects of the same semantic class and distortion class to be close to each other within a lower dimensional embedding space. This backbone trained with both semantic and distortion information is then fine-tuned within an object detection setting to empirically evaluate the quality of the learnt representation. We show this method leads to performance improvements by as much as 1.1% mean average precision over standard object detection strategies and .6% improvement over other state of the art representation learning approaches.
Learning Trajectory-Conditioned Relations to Predict Pedestrian Crossing Behavior
Jan 14, 2023
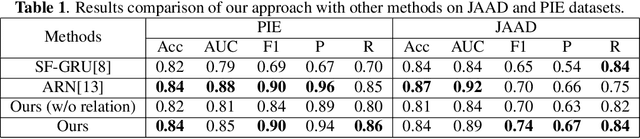
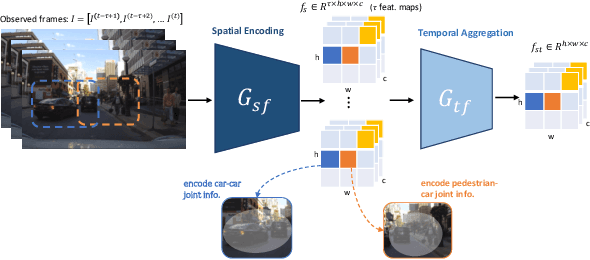

In smart transportation, intelligent systems avoid potential collisions by predicting the intent of traffic agents, especially pedestrians. Pedestrian intent, defined as future action, e.g., start crossing, can be dependent on traffic surroundings. In this paper, we develop a framework to incorporate such dependency given observed pedestrian trajectory and scene frames. Our framework first encodes regional joint information between a pedestrian and surroundings over time into feature-map vectors. The global relation representations are then extracted from pairwise feature-map vectors to estimate intent with past trajectory condition. We evaluate our approach on two public datasets and compare against two state-of-the-art approaches. The experimental results demonstrate that our method helps to inform potential risks during crossing events with 0.04 improvement in F1-score on JAAD dataset and 0.01 improvement in recall on PIE dataset. Furthermore, we conduct ablation experiments to confirm the contribution of the relation extraction in our framework.
DEVIANT: Depth EquiVarIAnt NeTwork for Monocular 3D Object Detection
Jul 21, 2022
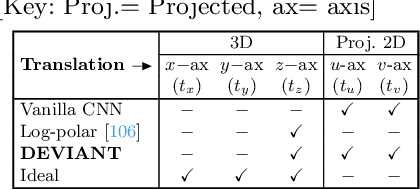
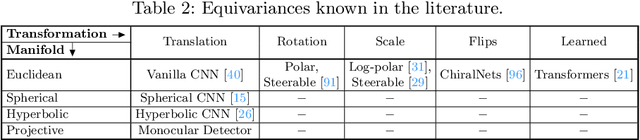
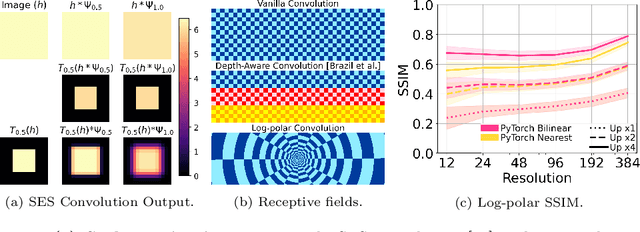
Modern neural networks use building blocks such as convolutions that are equivariant to arbitrary 2D translations. However, these vanilla blocks are not equivariant to arbitrary 3D translations in the projective manifold. Even then, all monocular 3D detectors use vanilla blocks to obtain the 3D coordinates, a task for which the vanilla blocks are not designed for. This paper takes the first step towards convolutions equivariant to arbitrary 3D translations in the projective manifold. Since the depth is the hardest to estimate for monocular detection, this paper proposes Depth EquiVarIAnt NeTwork (DEVIANT) built with existing scale equivariant steerable blocks. As a result, DEVIANT is equivariant to the depth translations in the projective manifold whereas vanilla networks are not. The additional depth equivariance forces the DEVIANT to learn consistent depth estimates, and therefore, DEVIANT achieves state-of-the-art monocular 3D detection results on KITTI and Waymo datasets in the image-only category and performs competitively to methods using extra information. Moreover, DEVIANT works better than vanilla networks in cross-dataset evaluation. Code and models at https://github.com/abhi1kumar/DEVIANT
Real-time Full-stack Traffic Scene Perception for Autonomous Driving with Roadside Cameras
Jun 20, 2022
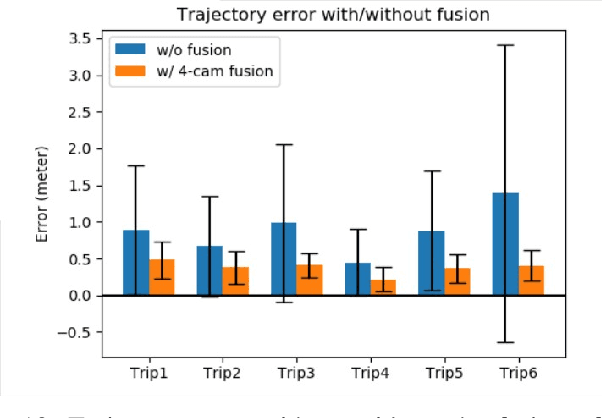
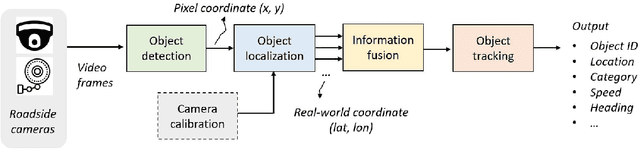
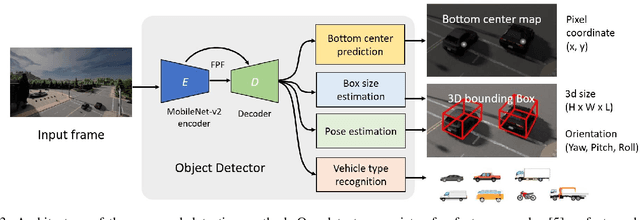
We propose a novel and pragmatic framework for traffic scene perception with roadside cameras. The proposed framework covers a full-stack of roadside perception pipeline for infrastructure-assisted autonomous driving, including object detection, object localization, object tracking, and multi-camera information fusion. Unlike previous vision-based perception frameworks rely upon depth offset or 3D annotation at training, we adopt a modular decoupling design and introduce a landmark-based 3D localization method, where the detection and localization can be well decoupled so that the model can be easily trained based on only 2D annotations. The proposed framework applies to either optical or thermal cameras with pinhole or fish-eye lenses. Our framework is deployed at a two-lane roundabout located at Ellsworth Rd. and State St., Ann Arbor, MI, USA, providing 7x24 real-time traffic flow monitoring and high-precision vehicle trajectory extraction. The whole system runs efficiently on a low-power edge computing device with all-component end-to-end delay of less than 20ms.
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021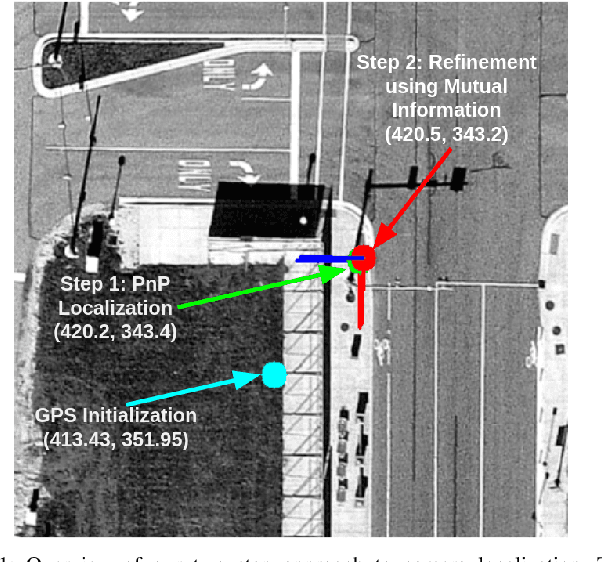


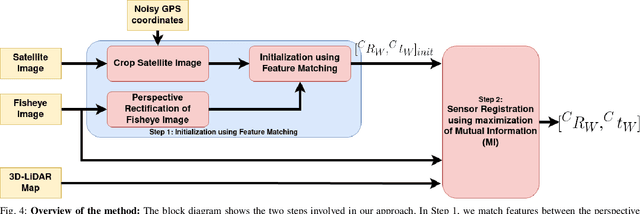
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.
Infrastructure Node-based Vehicle Localization for Autonomous Driving
Sep 21, 2021



Vehicle localization is essential for autonomous vehicle (AV) navigation and Advanced Driver Assistance Systems (ADAS). Accurate vehicle localization is often achieved via expensive inertial navigation systems or by employing compute-intensive vision processing (LiDAR/camera) to augment the low-cost and noisy inertial sensors. Here we have developed a framework for fusing the information obtained from a smart infrastructure node (ix-node) with the autonomous vehicles on-board localization engine to estimate the robust and accurate pose of the ego-vehicle even with cheap inertial sensors. A smart ix-node is typically used to augment the perception capability of an autonomous vehicle, especially when the onboard perception sensors of AVs are blocked by the dynamic and static objects in the environment thereby making them ineffectual. In this work, we utilize this perception output from an ix-node to increase the localization accuracy of the AV. The fusion of ix-node perception output with the vehicle's low-cost inertial sensors allows us to perform reliable vehicle localization without the need for relying on expensive inertial navigation systems or compute-intensive vision processing onboard the AVs. The proposed approach has been tested on real-world datasets collected from a test track in Ann Arbor, Michigan. Detailed analysis of the experimental results shows that incorporating ix-node data improves localization performance.