 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasetEquity: Are All Samples Created Equal? In The Quest For Equity Within Datasets
Aug 22, 2023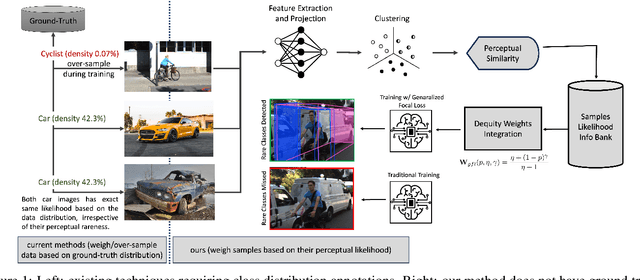

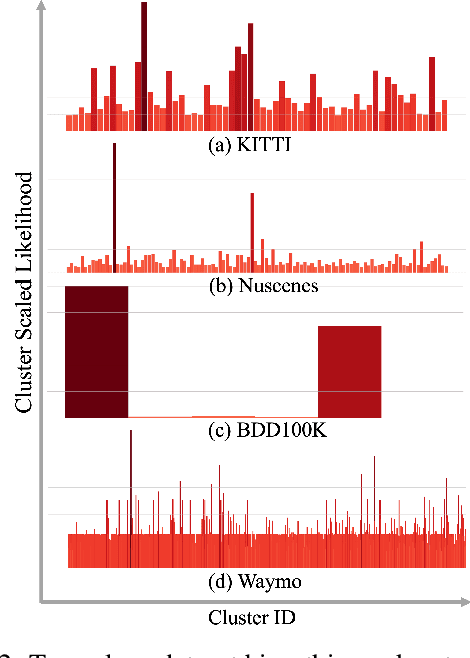
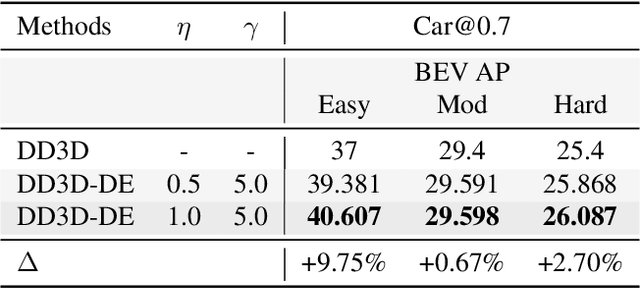
Data imbalance is a well-known issue in the field of machine learning, attributable to the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. Compared to categorical distributions using class labels, image appearance reveals complex relationships between objects beyond what class labels provide. Clustering deep perceptual features extracted from raw pixels gives a richer representation of the data. This paper presents a novel method for addressing data imbalance in machine learning. The method computes sample likelihoods based on image appearance using deep perceptual embeddings and clustering. It then uses these likelihoods to weigh samples differently during training with a proposed $\textbf{Generalized Focal Loss}$ function. This loss can be easily integrated with deep learning algorithms. Experiments validate the method's effectiveness across autonomous driving vision datasets including KITTI and nuScenes. The loss function improves state-of-the-art 3D object detection methods, achieving over $200\%$ AP gains on under-represented classes (Cyclist) in the KITTI dataset. The results demonstrate the method is generalizable, complements existing techniques, and is particularly beneficial for smaller datasets and rare classes. Code is available at: https://github.com/towardsautonomy/DatasetEquity
Ref-DVGO: Reflection-Aware Direct Voxel Grid Optimization for an Improved Quality-Efficiency Trade-Off in Reflective Scene Reconstruction
Aug 21, 2023



Neural Radiance Fields (NeRFs) have revolutionized the field of novel view synthesis, demonstrating remarkable performance. However, the modeling and rendering of reflective objects remain challenging problems. Recent methods have shown significant improvements over the baselines in handling reflective scenes, albeit at the expense of efficiency. In this work, we aim to strike a balance between efficiency and quality. To this end, we investigate an implicit-explicit approach based on conventional volume rendering to enhance the reconstruction quality and accelerate the training and rendering processes. We adopt an efficient density-based grid representation and reparameterize the reflected radiance in our pipeline. Our proposed reflection-aware approach achieves a competitive quality efficiency trade-off compared to competing methods. Based on our experimental results, we propose and discuss hypotheses regarding the factors influencing the results of density-based methods for reconstructing reflective objects. The source code is available at https://github.com/gkouros/ref-dvgo.
Locking On: Leveraging Dynamic Vehicle-Imposed Motion Constraints to Improve Visual Localization
Jun 30, 2023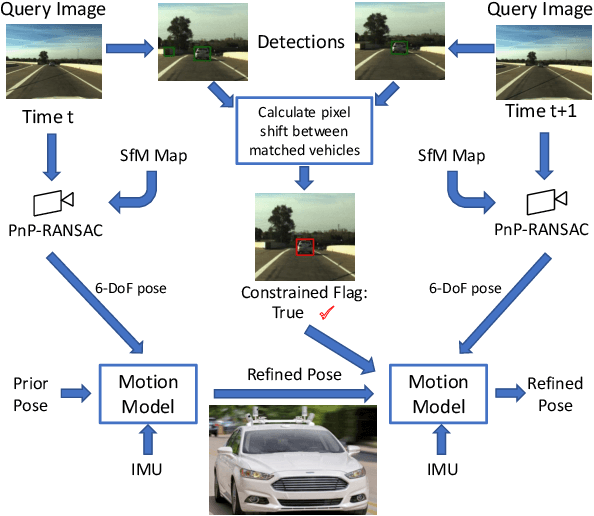
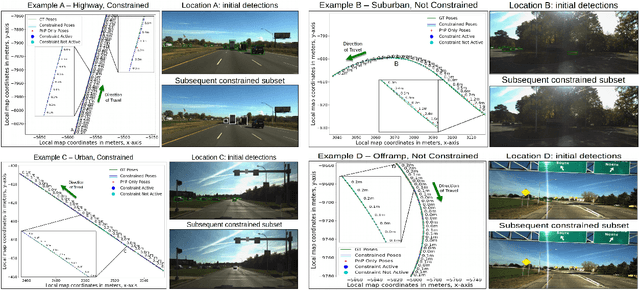

Most 6-DoF localization and SLAM systems use static landmarks but ignore dynamic objects because they cannot be usefully incorporated into a typical pipeline. Where dynamic objects have been incorporated, typical approaches have attempted relatively sophisticated identification and localization of these objects, limiting their robustness or general utility. In this research, we propose a middle ground, demonstrated in the context of autonomous vehicles, using dynamic vehicles to provide limited pose constraint information in a 6-DoF frame-by-frame PnP-RANSAC localization pipeline. We refine initial pose estimates with a motion model and propose a method for calculating the predicted quality of future pose estimates, triggered based on whether or not the autonomous vehicle's motion is constrained by the relative frame-to-frame location of dynamic vehicles in the environment. Our approach detects and identifies suitable dynamic vehicles to define these pose constraints to modify a pose filter, resulting in improved recall across a range of localization tolerances from $0.25m$ to $5m$, compared to a state-of-the-art baseline single image PnP method and its vanilla pose filtering. Our constraint detection system is active for approximately $35\%$ of the time on the Ford AV dataset and localization is particularly improved when the constraint detection is active.
DisPlacing Objects: Improving Dynamic Vehicle Detection via Visual Place Recognition under Adverse Conditions
Jun 30, 2023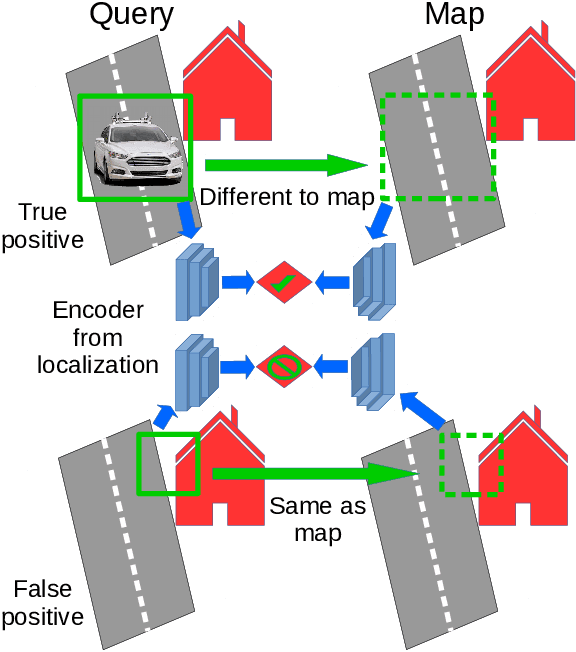
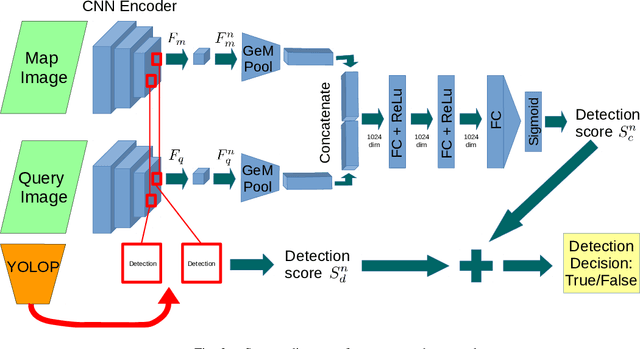
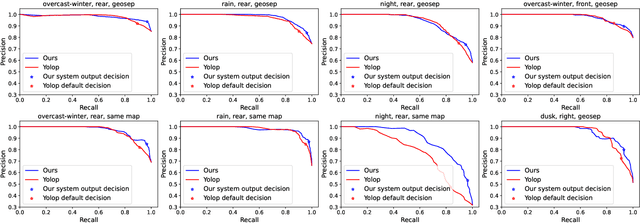

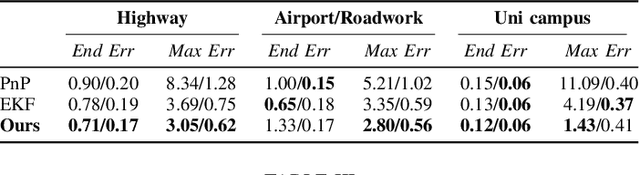
Can knowing where you are assist in perceiving objects in your surroundings, especially under adverse weather and lighting conditions? In this work we investigate whether a prior map can be leveraged to aid in the detection of dynamic objects in a scene without the need for a 3D map or pixel-level map-query correspondences. We contribute an algorithm which refines an initial set of candidate object detections and produces a refined subset of highly accurate detections using a prior map. We begin by using visual place recognition (VPR) to retrieve a reference map image for a given query image, then use a binary classification neural network that compares the query and mapping image regions to validate the query detection. Once our classification network is trained, on approximately 1000 query-map image pairs, it is able to improve the performance of vehicle detection when combined with an existing off-the-shelf vehicle detector. We demonstrate our approach using standard datasets across two cities (Oxford and Zurich) under different settings of train-test separation of map-query traverse pairs. We further emphasize the performance gains of our approach against alternative design choices and show that VPR suffices for the task, eliminating the need for precise ground truth localization.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022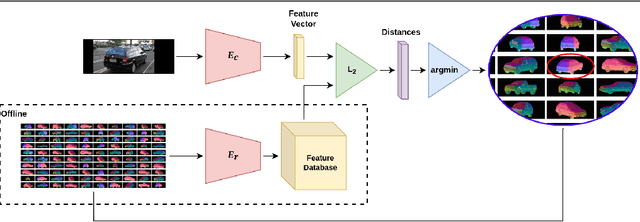
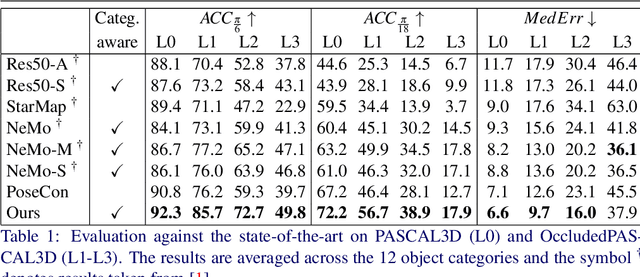
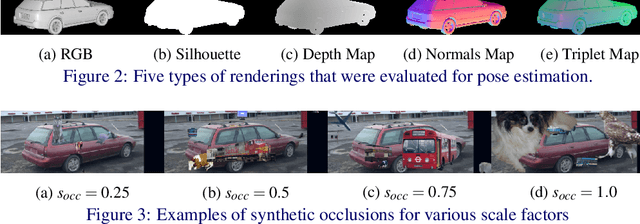
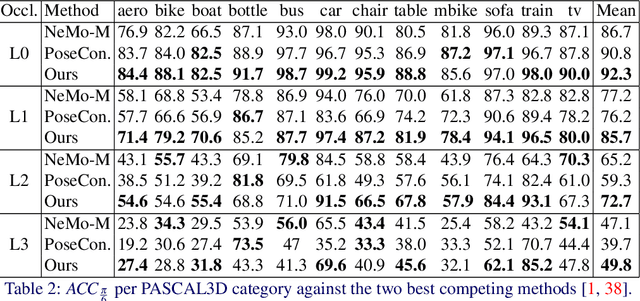
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Improving Worst Case Visual Localization Coverage via Place-specific Sub-selection in Multi-camera Systems
Jun 28, 2022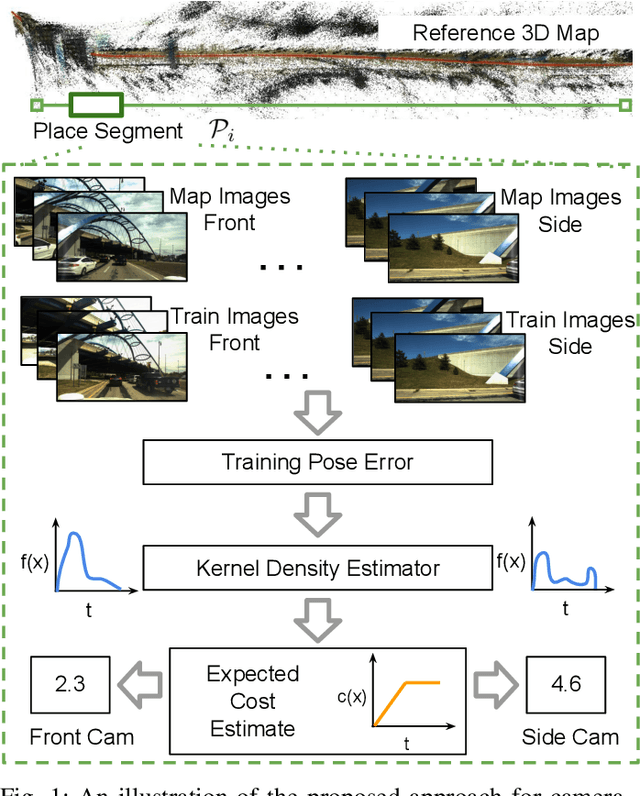
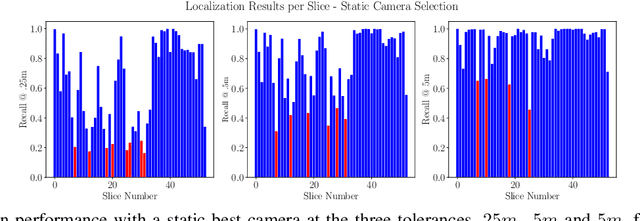
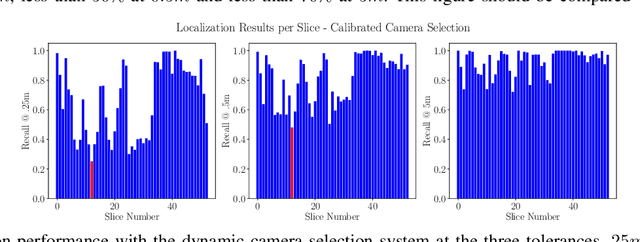
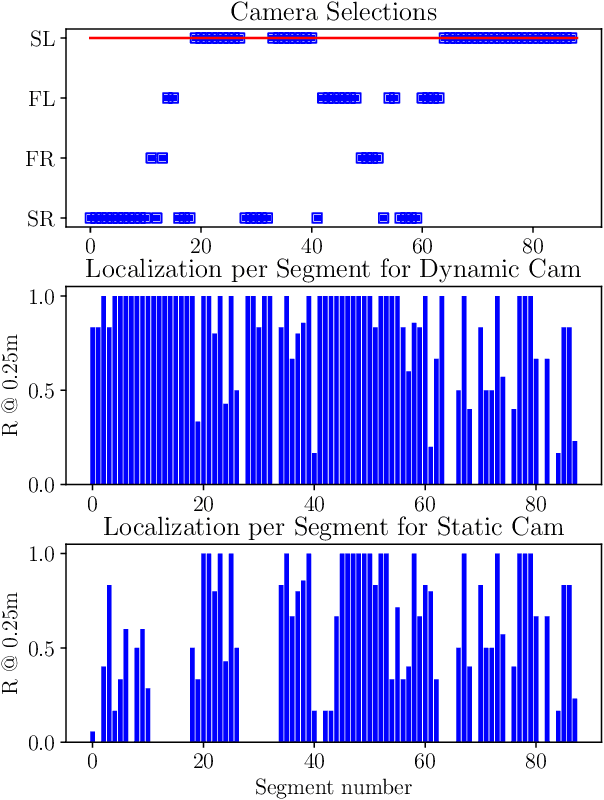
6-DoF visual localization systems utilize principled approaches rooted in 3D geometry to perform accurate camera pose estimation of images to a map. Current techniques use hierarchical pipelines and learned 2D feature extractors to improve scalability and increase performance. However, despite gains in typical recall@0.25m type metrics, these systems still have limited utility for real-world applications like autonomous vehicles because of their `worst' areas of performance - the locations where they provide insufficient recall at a certain required error tolerance. Here we investigate the utility of using `place specific configurations', where a map is segmented into a number of places, each with its own configuration for modulating the pose estimation step, in this case selecting a camera within a multi-camera system. On the Ford AV benchmark dataset, we demonstrate substantially improved worst-case localization performance compared to using off-the-shelf pipelines - minimizing the percentage of the dataset which has low recall at a certain error tolerance, as well as improved overall localization performance. Our proposed approach is particularly applicable to the crowdsharing model of autonomous vehicle deployment, where a fleet of AVs are regularly traversing a known route.
QAGAN: Adversarial Approach To Learning Domain Invariant Language Features
Jun 24, 2022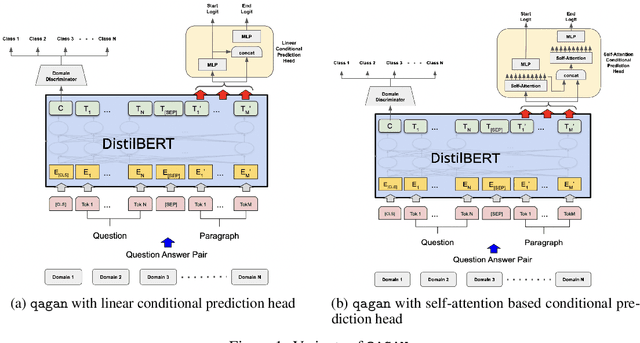
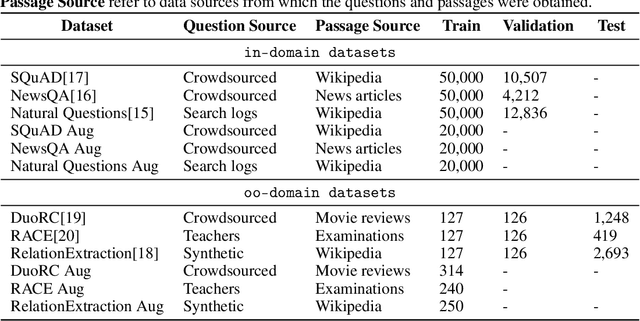

Training models that are robust to data domain shift has gained an increasing interest both in academia and industry. Question-Answering language models, being one of the typical problem in Natural Language Processing (NLP) research, has received much success with the advent of large transformer models. However, existing approaches mostly work under the assumption that data is drawn from same distribution during training and testing which is unrealistic and non-scalable in the wild. In this paper, we explore adversarial training approach towards learning domain-invariant features so that language models can generalize well to out-of-domain datasets. We also inspect various other ways to boost our model performance including data augmentation by paraphrasing sentences, conditioning end of answer span prediction on the start word, and carefully designed annealing function. Our initial results show that in combination with these methods, we are able to achieve $15.2\%$ improvement in EM score and $5.6\%$ boost in F1 score on out-of-domain validation dataset over the baseline. We also dissect our model outputs and visualize the model hidden-states by projecting them onto a lower-dimensional space, and discover that our specific adversarial training approach indeed encourages the model to learn domain invariant embedding and bring them closer in the multi-dimensional space.
Propagating State Uncertainty Through Trajectory Forecasting
Oct 18, 2021
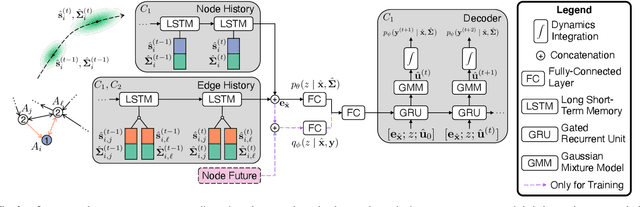
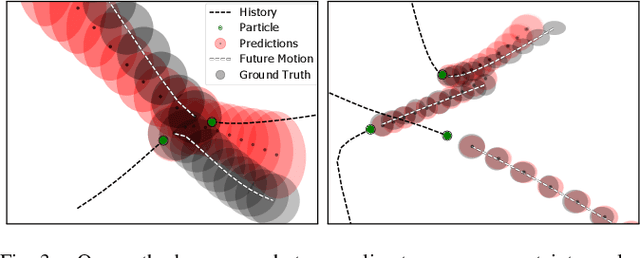
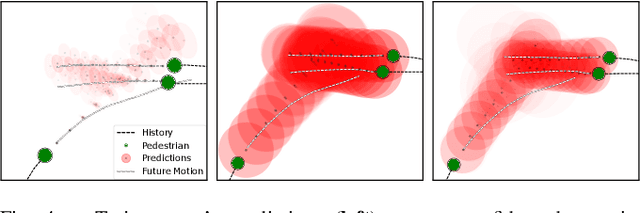
Uncertainty pervades through the modern robotic autonomy stack, with nearly every component (e.g., sensors, detection, classification, tracking, behavior prediction) producing continuous or discrete probabilistic distributions. Trajectory forecasting, in particular, is surrounded by uncertainty as its inputs are produced by (noisy) upstream perception and its outputs are predictions that are often probabilistic for use in downstream planning. However, most trajectory forecasting methods do not account for upstream uncertainty, instead taking only the most-likely values. As a result, perceptual uncertainties are not propagated through forecasting and predictions are frequently overconfident. To address this, we present a novel method for incorporating perceptual state uncertainty in trajectory forecasting, a key component of which is a new statistical distance-based loss function which encourages predicting uncertainties that better match upstream perception. We evaluate our approach both in illustrative simulations and on large-scale, real-world data, demonstrating its efficacy in propagating perceptual state uncertainty through prediction and producing more calibrated predictions.
VR3Dense: Voxel Representation Learning for 3D Object Detection and Monocular Dense Depth Reconstruction
Apr 13, 2021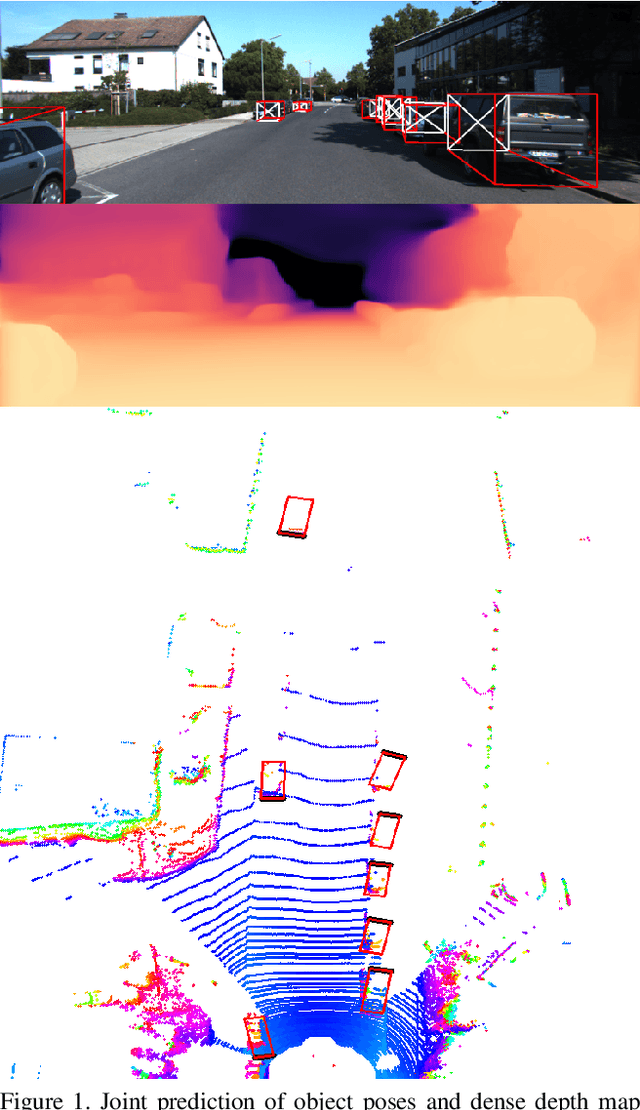

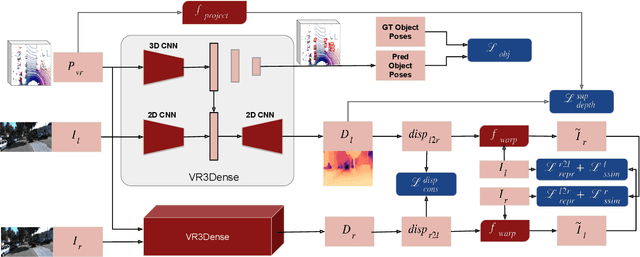
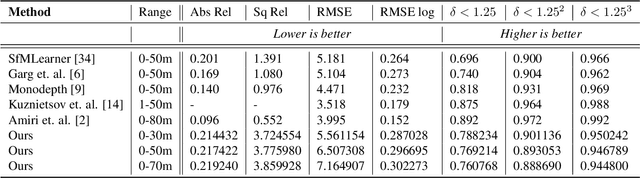
3D object detection and dense depth estimation are one of the most vital tasks in autonomous driving. Multiple sensor modalities can jointly attribute towards better robot perception, and to that end, we introduce a method for jointly training 3D object detection and monocular dense depth reconstruction neural networks. It takes as inputs, a LiDAR point-cloud, and a single RGB image during inference and produces object pose predictions as well as a densely reconstructed depth map. LiDAR point-cloud is converted into a set of voxels, and its features are extracted using 3D convolution layers, from which we regress object pose parameters. Corresponding RGB image features are extracted using another 2D convolutional neural network. We further use these combined features to predict a dense depth map. While our object detection is trained in a supervised manner, the depth prediction network is trained with both self-supervised and supervised loss functions. We also introduce a loss function, edge-preserving smooth loss, and show that this results in better depth estimation compared to the edge-aware smooth loss function, frequently used in depth prediction works.
Meta-Regularization by Enforcing Mutual-Exclusiveness
Jan 24, 2021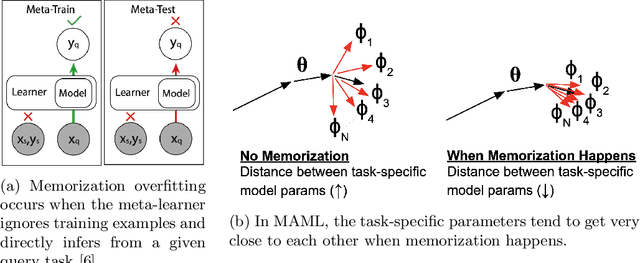
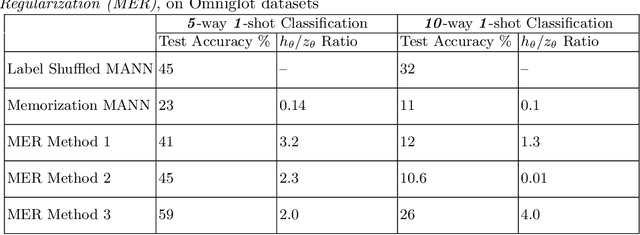
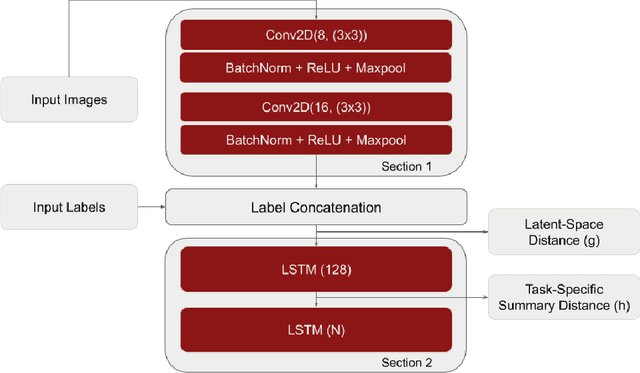
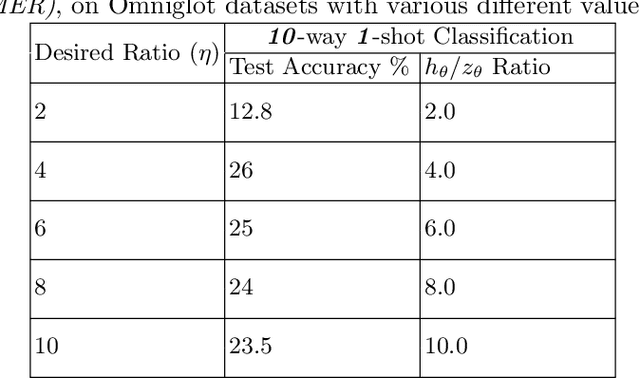
Meta-learning models have two objectives. First, they need to be able to make predictions over a range of task distributions while utilizing only a small amount of training data. Second, they also need to adapt to new novel unseen tasks at meta-test time again by using only a small amount of training data from that task. It is the second objective where meta-learning models fail for non-mutually exclusive tasks due to task overfitting. Given that guaranteeing mutually exclusive tasks is often difficult, there is a significant need for regularization methods that can help reduce the impact of task-memorization in meta-learning. For example, in the case of N-way, K-shot classification problems, tasks becomes non-mutually exclusive when the labels associated with each task is fixed. Under this design, the model will simply memorize the class labels of all the training tasks, and thus will fail to recognize a new task (class) at meta-test time. A direct observable consequence of this memorization is that the meta-learning model simply ignores the task-specific training data in favor of directly classifying based on the test-data input. In our work, we propose a regularization technique for meta-learning models that gives the model designer more control over the information flow during meta-training. Our method consists of a regularization function that is constructed by maximizing the distance between task-summary statistics, in the case of black-box models and task specific network parameters in the case of optimization based models during meta-training. Our proposed regularization function shows an accuracy boost of $\sim$ $36\%$ on the Omniglot dataset for 5-way, 1-shot classification using black-box method and for 20-way, 1-shot classification problem using optimization-based method.