 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVR3Dense: Voxel Representation Learning for 3D Object Detection and Monocular Dense Depth Reconstruction
Paper and Code
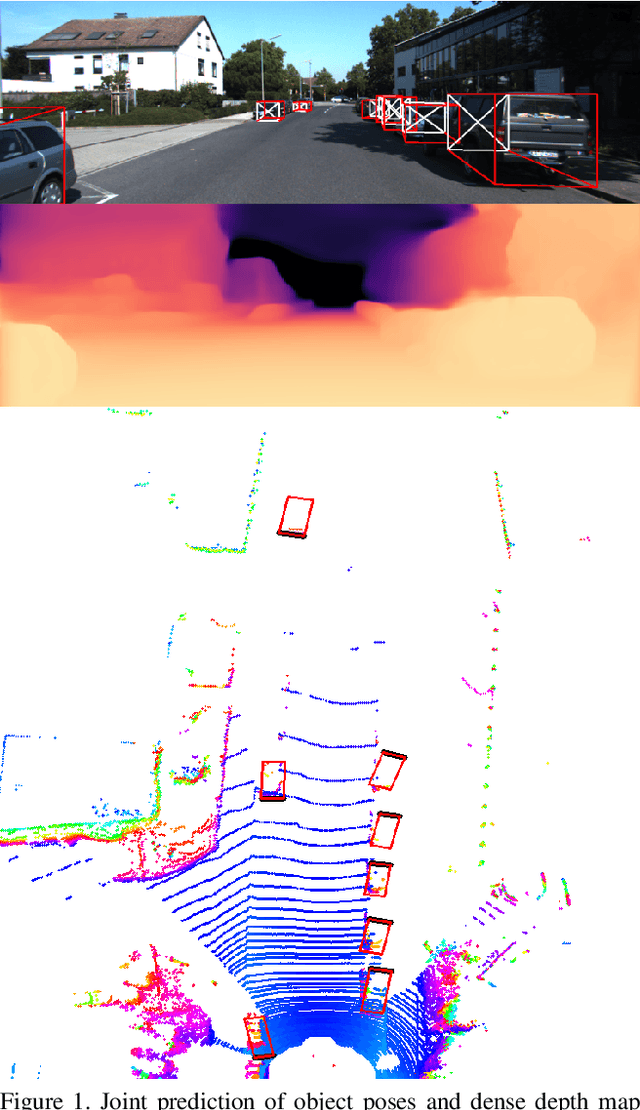

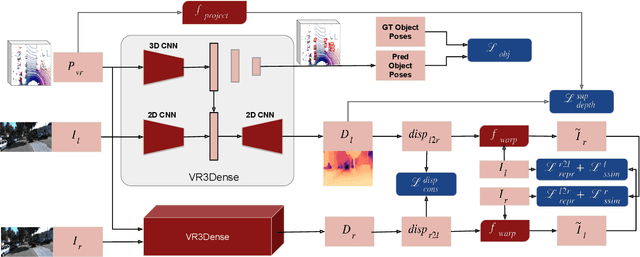
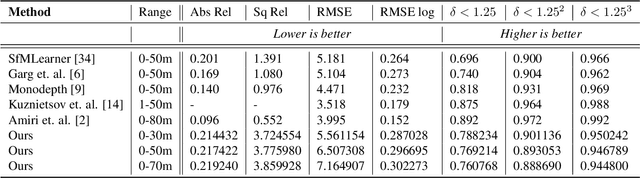
3D object detection and dense depth estimation are one of the most vital tasks in autonomous driving. Multiple sensor modalities can jointly attribute towards better robot perception, and to that end, we introduce a method for jointly training 3D object detection and monocular dense depth reconstruction neural networks. It takes as inputs, a LiDAR point-cloud, and a single RGB image during inference and produces object pose predictions as well as a densely reconstructed depth map. LiDAR point-cloud is converted into a set of voxels, and its features are extracted using 3D convolution layers, from which we regress object pose parameters. Corresponding RGB image features are extracted using another 2D convolutional neural network. We further use these combined features to predict a dense depth map. While our object detection is trained in a supervised manner, the depth prediction network is trained with both self-supervised and supervised loss functions. We also introduce a loss function, edge-preserving smooth loss, and show that this results in better depth estimation compared to the edge-aware smooth loss function, frequently used in depth prediction works.