 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Regularization by Enforcing Mutual-Exclusiveness
Paper and Code
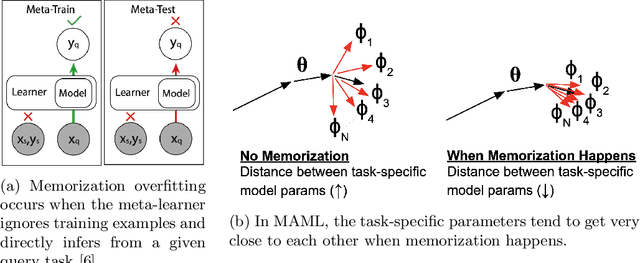
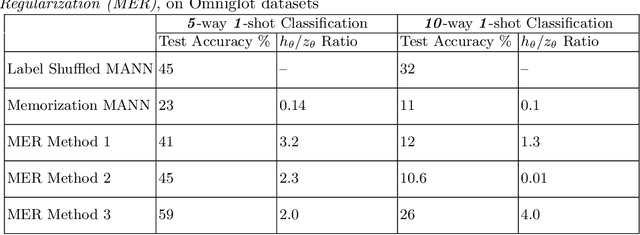
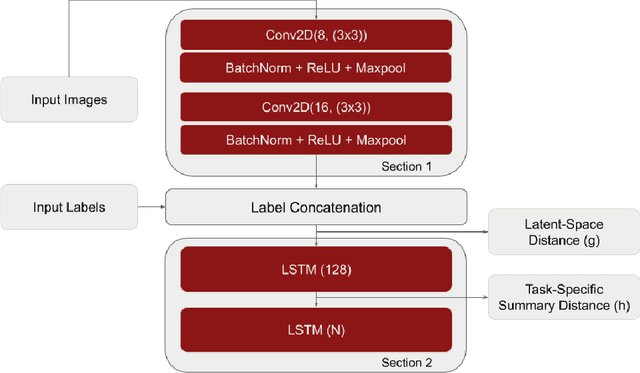
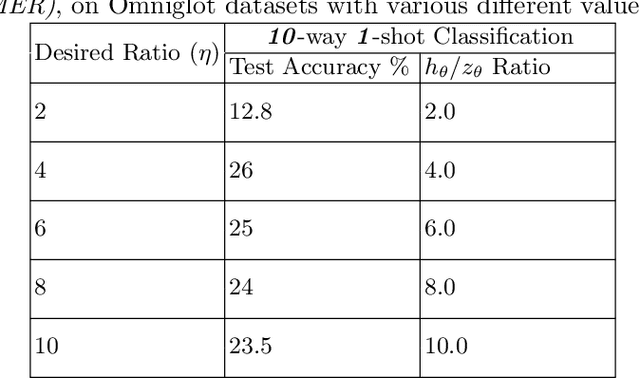
Meta-learning models have two objectives. First, they need to be able to make predictions over a range of task distributions while utilizing only a small amount of training data. Second, they also need to adapt to new novel unseen tasks at meta-test time again by using only a small amount of training data from that task. It is the second objective where meta-learning models fail for non-mutually exclusive tasks due to task overfitting. Given that guaranteeing mutually exclusive tasks is often difficult, there is a significant need for regularization methods that can help reduce the impact of task-memorization in meta-learning. For example, in the case of N-way, K-shot classification problems, tasks becomes non-mutually exclusive when the labels associated with each task is fixed. Under this design, the model will simply memorize the class labels of all the training tasks, and thus will fail to recognize a new task (class) at meta-test time. A direct observable consequence of this memorization is that the meta-learning model simply ignores the task-specific training data in favor of directly classifying based on the test-data input. In our work, we propose a regularization technique for meta-learning models that gives the model designer more control over the information flow during meta-training. Our method consists of a regularization function that is constructed by maximizing the distance between task-summary statistics, in the case of black-box models and task specific network parameters in the case of optimization based models during meta-training. Our proposed regularization function shows an accuracy boost of $\sim$ $36\%$ on the Omniglot dataset for 5-way, 1-shot classification using black-box method and for 20-way, 1-shot classification problem using optimization-based method.