 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Worst Case Visual Localization Coverage via Place-specific Sub-selection in Multi-camera Systems
Paper and Code
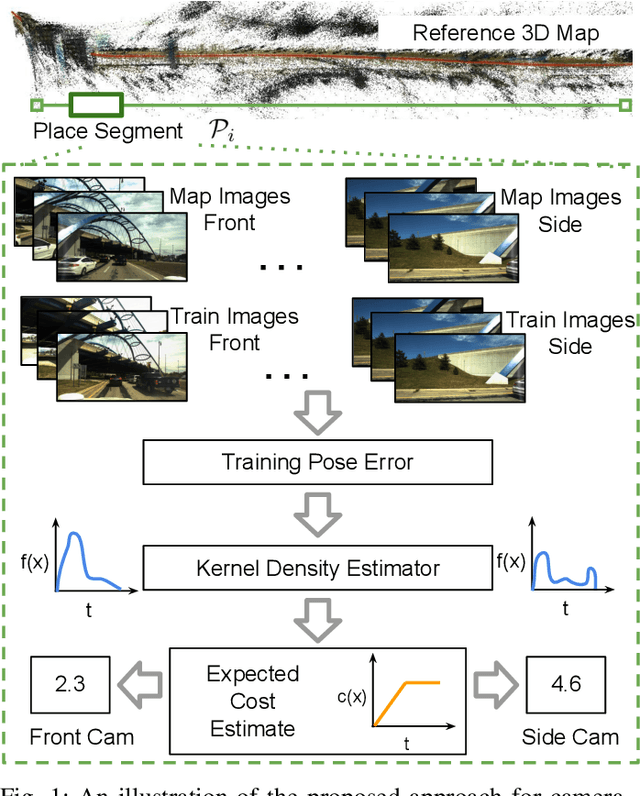
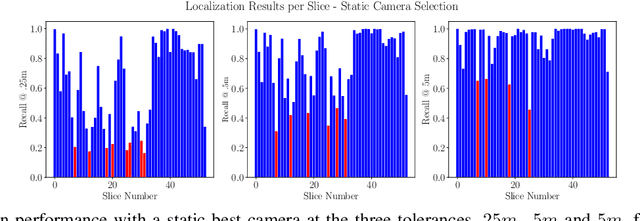
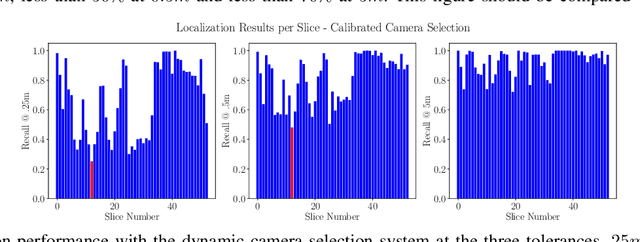
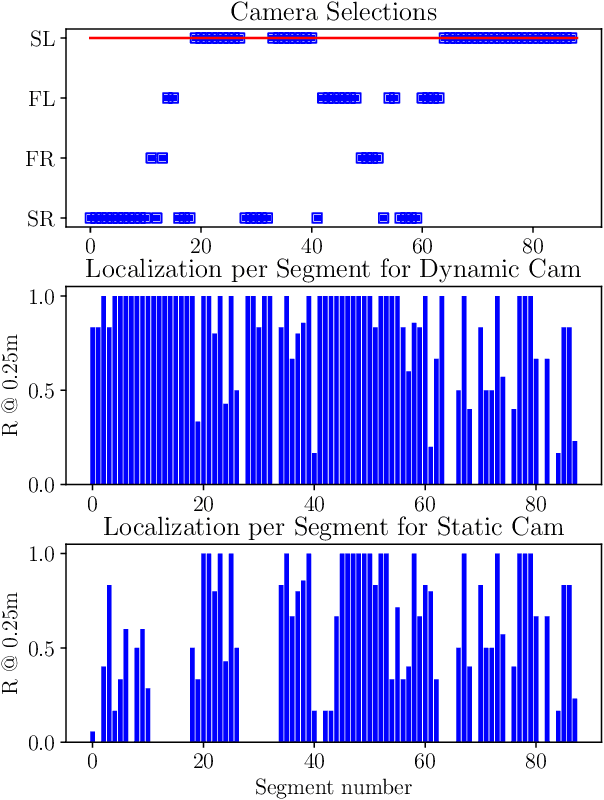
6-DoF visual localization systems utilize principled approaches rooted in 3D geometry to perform accurate camera pose estimation of images to a map. Current techniques use hierarchical pipelines and learned 2D feature extractors to improve scalability and increase performance. However, despite gains in typical recall@0.25m type metrics, these systems still have limited utility for real-world applications like autonomous vehicles because of their `worst' areas of performance - the locations where they provide insufficient recall at a certain required error tolerance. Here we investigate the utility of using `place specific configurations', where a map is segmented into a number of places, each with its own configuration for modulating the pose estimation step, in this case selecting a camera within a multi-camera system. On the Ford AV benchmark dataset, we demonstrate substantially improved worst-case localization performance compared to using off-the-shelf pipelines - minimizing the percentage of the dataset which has low recall at a certain error tolerance, as well as improved overall localization performance. Our proposed approach is particularly applicable to the crowdsharing model of autonomous vehicle deployment, where a fleet of AVs are regularly traversing a known route.