 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePair-VPR: Place-Aware Pre-training and Contrastive Pair Classification for Visual Place Recognition with Vision Transformers
Oct 09, 2024In this work we propose a novel joint training method for Visual Place Recognition (VPR), which simultaneously learns a global descriptor and a pair classifier for re-ranking. The pair classifier can predict whether a given pair of images are from the same place or not. The network only comprises Vision Transformer components for both the encoder and the pair classifier, and both components are trained using their respective class tokens. In existing VPR methods, typically the network is initialized using pre-trained weights from a generic image dataset such as ImageNet. In this work we propose an alternative pre-training strategy, by using Siamese Masked Image Modelling as a pre-training task. We propose a Place-aware image sampling procedure from a collection of large VPR datasets for pre-training our model, to learn visual features tuned specifically for VPR. By re-using the Mask Image Modelling encoder and decoder weights in the second stage of training, Pair-VPR can achieve state-of-the-art VPR performance across five benchmark datasets with a ViT-B encoder, along with further improvements in localization recall with larger encoders. The Pair-VPR website is: https://csiro-robotics.github.io/Pair-VPR.
VLAD-BuFF: Burst-aware Fast Feature Aggregation for Visual Place Recognition
Sep 28, 2024Visual Place Recognition (VPR) is a crucial component of many visual localization pipelines for embodied agents. VPR is often formulated as an image retrieval task aimed at jointly learning local features and an aggregation method. The current state-of-the-art VPR methods rely on VLAD aggregation, which can be trained to learn a weighted contribution of features through their soft assignment to cluster centers. However, this process has two key limitations. Firstly, the feature-to-cluster weighting does not account for over-represented repetitive structures within a cluster, e.g., shadows or window panes; this phenomenon is also referred to as the `burstiness' problem, classically solved by discounting repetitive features before aggregation. Secondly, feature to cluster comparisons are compute-intensive for state-of-the-art image encoders with high-dimensional local features. This paper addresses these limitations by introducing VLAD-BuFF with two novel contributions: i) a self-similarity based feature discounting mechanism to learn Burst-aware features within end-to-end VPR training, and ii) Fast Feature aggregation by reducing local feature dimensions specifically through PCA-initialized learnable pre-projection. We benchmark our method on 9 public datasets, where VLAD-BuFF sets a new state of the art. Our method is able to maintain its high recall even for 12x reduced local feature dimensions, thus enabling fast feature aggregation without compromising on recall. Through additional qualitative studies, we show how our proposed weighting method effectively downweights the non-distinctive features. Source code: https://github.com/Ahmedest61/VLAD-BuFF/.
Object Registration in Neural Fields
Apr 29, 2024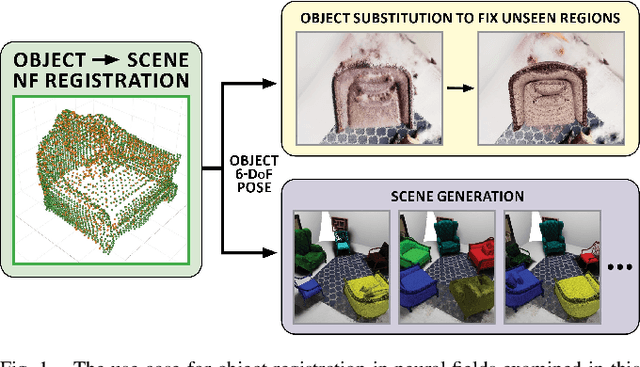


Neural fields provide a continuous scene representation of 3D geometry and appearance in a way which has great promise for robotics applications. One functionality that unlocks unique use-cases for neural fields in robotics is object 6-DoF registration. In this paper, we provide an expanded analysis of the recent Reg-NF neural field registration method and its use-cases within a robotics context. We showcase the scenario of determining the 6-DoF pose of known objects within a scene using scene and object neural field models. We show how this may be used to better represent objects within imperfectly modelled scenes and generate new scenes by substituting object neural field models into the scene.
Towards Long-term Robotics in the Wild
Apr 29, 2024



In this paper, we emphasise the critical importance of large-scale datasets for advancing field robotics capabilities, particularly in natural environments. While numerous datasets exist for urban and suburban settings, those tailored to natural environments are scarce. Our recent benchmarks WildPlaces and WildScenes address this gap by providing synchronised image, lidar, semantic and accurate 6-DoF pose information in forest-type environments. We highlight the multi-modal nature of this dataset and discuss and demonstrate its utility in various downstream tasks, such as place recognition and 2D and 3D semantic segmentation tasks.
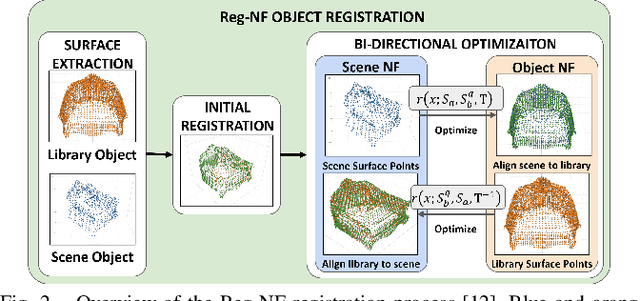
Reg-NF: Efficient Registration of Implicit Surfaces within Neural Fields
Feb 15, 2024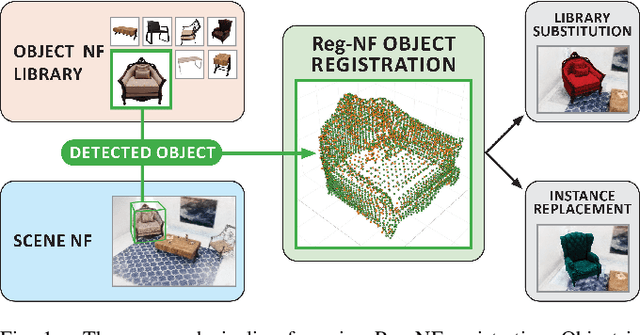
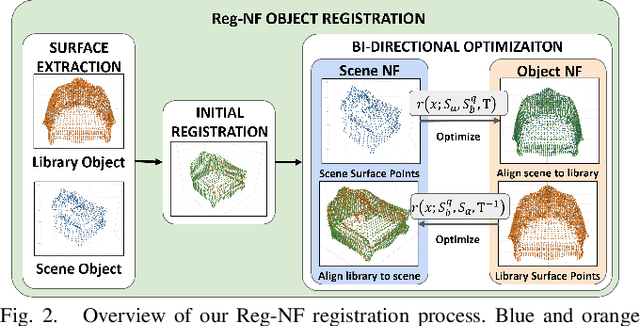

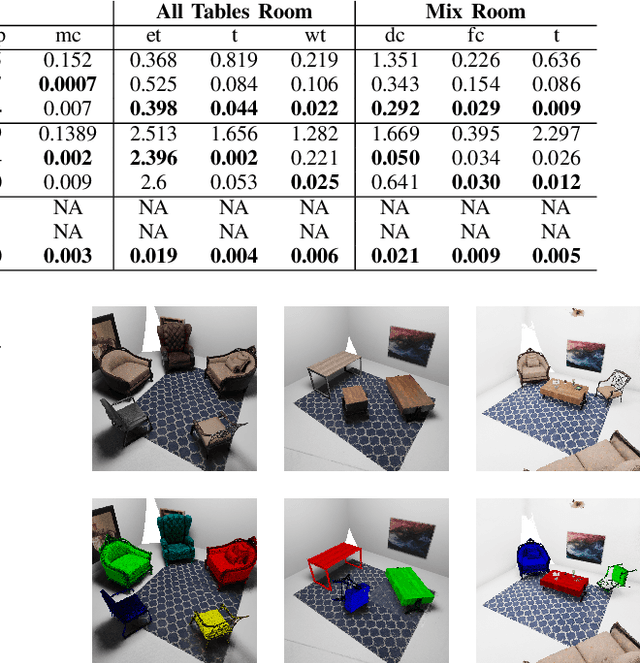
Neural fields, coordinate-based neural networks, have recently gained popularity for implicitly representing a scene. In contrast to classical methods that are based on explicit representations such as point clouds, neural fields provide a continuous scene representation able to represent 3D geometry and appearance in a way which is compact and ideal for robotics applications. However, limited prior methods have investigated registering multiple neural fields by directly utilising these continuous implicit representations. In this paper, we present Reg-NF, a neural fields-based registration that optimises for the relative 6-DoF transformation between two arbitrary neural fields, even if those two fields have different scale factors. Key components of Reg-NF include a bidirectional registration loss, multi-view surface sampling, and utilisation of volumetric signed distance functions (SDFs). We showcase our approach on a new neural field dataset for evaluating registration problems. We provide an exhaustive set of experiments and ablation studies to identify the performance of our approach, while also discussing limitations to provide future direction to the research community on open challenges in utilizing neural fields in unconstrained environments.
WildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
GeoAdapt: Self-Supervised Test-Time Adaption in LiDAR Place Recognition Using Geometric Priors
Aug 09, 2023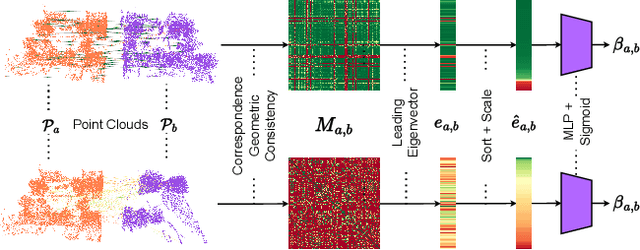
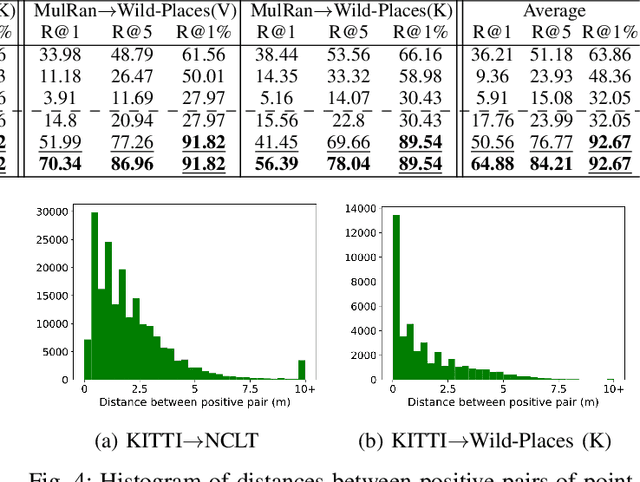
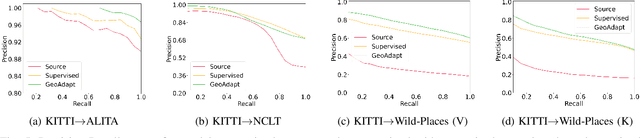
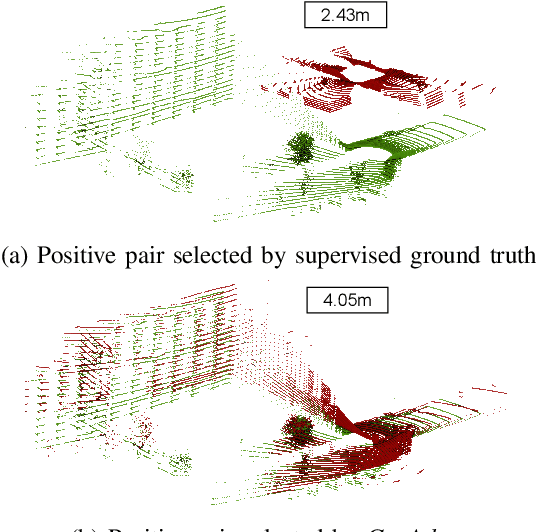
LiDAR place recognition approaches based on deep learning suffer a significant degradation in performance when there is a shift between the distribution of the training and testing datasets, with re-training often required to achieve top performance. However, obtaining accurate ground truth on new environments can be prohibitively expensive, especially in complex or GPS-deprived environments. To address this issue we propose GeoAdapt, which introduces a novel auxiliary classification head to generate pseudo-labels for re-training on unseen environments in a self-supervised manner. GeoAdapt uses geometric consistency as a prior to improve the robustness of our generated pseudo-labels against domain shift, improving the performance and reliability of our Test-Time Adaptation approach. Comprehensive experiments show that GeoAdapt significantly boosts place recognition performance across moderate to severe domain shifts, and is competitive with fully supervised test-time adaptation approaches. Our code will be available at https://github.com/csiro-robotics/GeoAdapt.
Locking On: Leveraging Dynamic Vehicle-Imposed Motion Constraints to Improve Visual Localization
Jun 30, 2023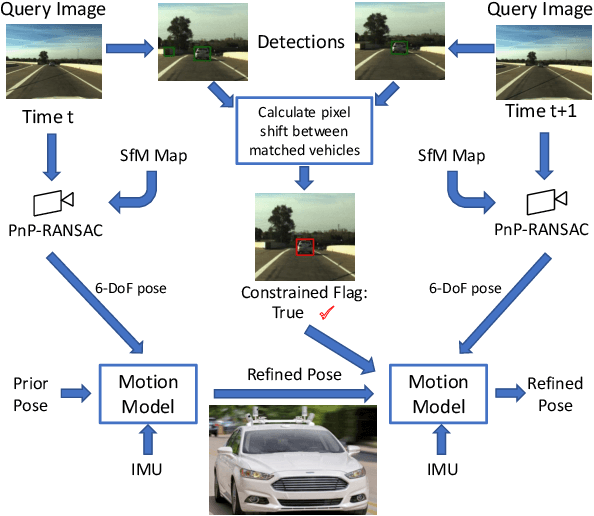
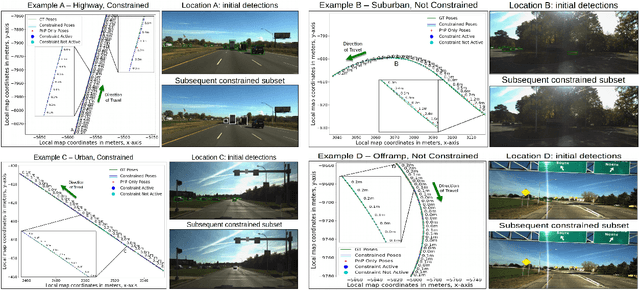

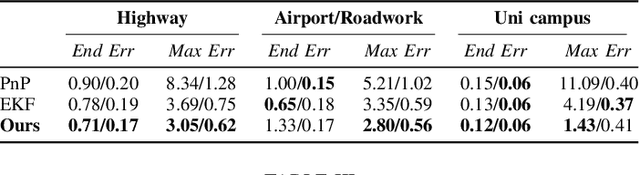
Most 6-DoF localization and SLAM systems use static landmarks but ignore dynamic objects because they cannot be usefully incorporated into a typical pipeline. Where dynamic objects have been incorporated, typical approaches have attempted relatively sophisticated identification and localization of these objects, limiting their robustness or general utility. In this research, we propose a middle ground, demonstrated in the context of autonomous vehicles, using dynamic vehicles to provide limited pose constraint information in a 6-DoF frame-by-frame PnP-RANSAC localization pipeline. We refine initial pose estimates with a motion model and propose a method for calculating the predicted quality of future pose estimates, triggered based on whether or not the autonomous vehicle's motion is constrained by the relative frame-to-frame location of dynamic vehicles in the environment. Our approach detects and identifies suitable dynamic vehicles to define these pose constraints to modify a pose filter, resulting in improved recall across a range of localization tolerances from $0.25m$ to $5m$, compared to a state-of-the-art baseline single image PnP method and its vanilla pose filtering. Our constraint detection system is active for approximately $35\%$ of the time on the Ford AV dataset and localization is particularly improved when the constraint detection is active.
DisPlacing Objects: Improving Dynamic Vehicle Detection via Visual Place Recognition under Adverse Conditions
Jun 30, 2023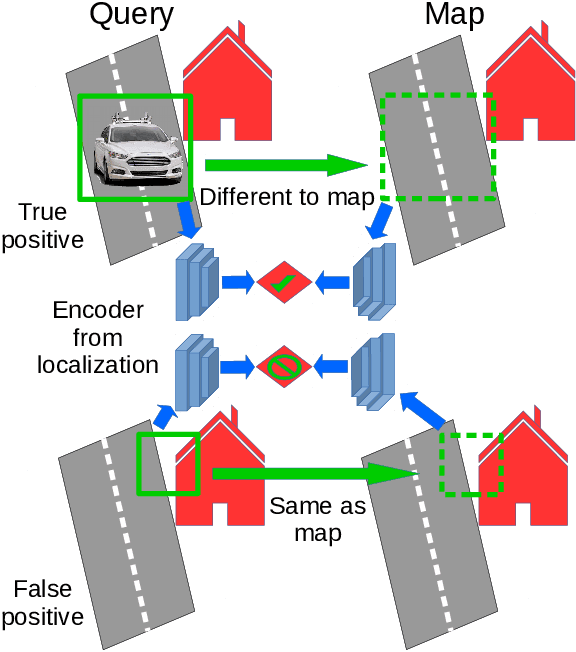
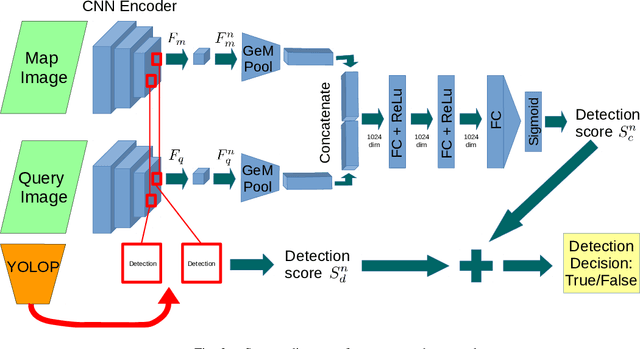
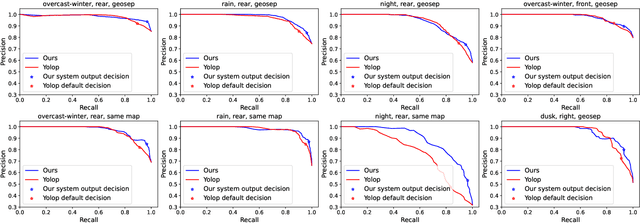

Can knowing where you are assist in perceiving objects in your surroundings, especially under adverse weather and lighting conditions? In this work we investigate whether a prior map can be leveraged to aid in the detection of dynamic objects in a scene without the need for a 3D map or pixel-level map-query correspondences. We contribute an algorithm which refines an initial set of candidate object detections and produces a refined subset of highly accurate detections using a prior map. We begin by using visual place recognition (VPR) to retrieve a reference map image for a given query image, then use a binary classification neural network that compares the query and mapping image regions to validate the query detection. Once our classification network is trained, on approximately 1000 query-map image pairs, it is able to improve the performance of vehicle detection when combined with an existing off-the-shelf vehicle detector. We demonstrate our approach using standard datasets across two cities (Oxford and Zurich) under different settings of train-test separation of map-query traverse pairs. We further emphasize the performance gains of our approach against alternative design choices and show that VPR suffices for the task, eliminating the need for precise ground truth localization.
Boosting Performance of a Baseline Visual Place Recognition Technique by Predicting the Maximally Complementary Technique
Oct 14, 2022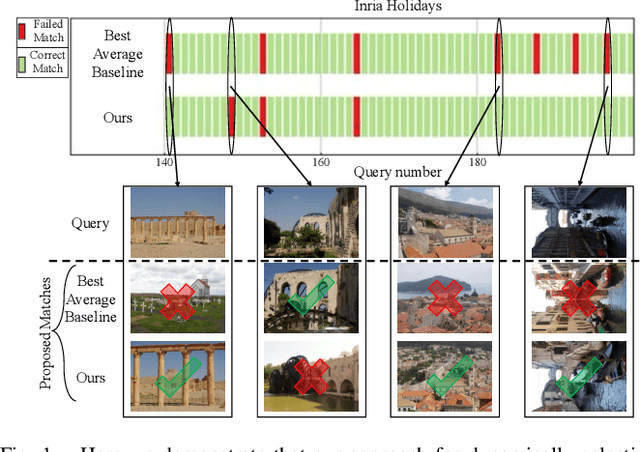
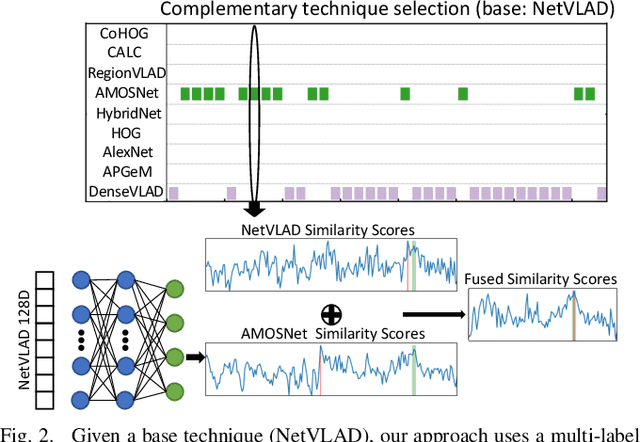
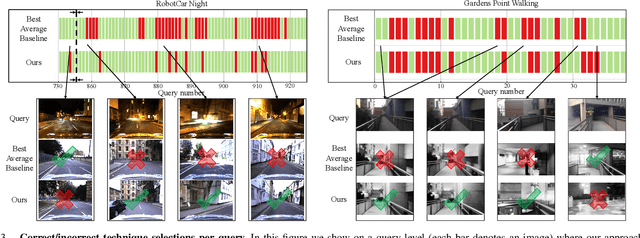
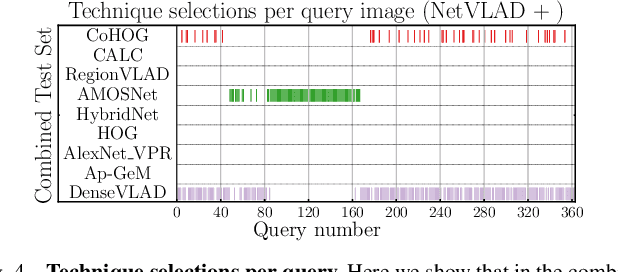
One recent promising approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques using methods such as SRAL and multi-process fusion. These approaches come with a substantial practical limitation: they require all potential VPR methods to be brute-force run before they are selectively fused. The obvious solution to this limitation is to predict the viable subset of methods ahead of time, but this is challenging because it requires a predictive signal within the imagery itself that is indicative of high performance methods. Here we propose an alternative approach that instead starts with a known single base VPR technique, and learns to predict the most complementary additional VPR technique to fuse with it, that results in the largest improvement in performance. The key innovation here is to use a dimensionally reduced difference vector between the query image and the top-retrieved reference image using this baseline technique as the predictive signal of the most complementary additional technique, both during training and inference. We demonstrate that our approach can train a single network to select performant, complementary technique pairs across datasets which span multiple modes of transportation (train, car, walking) as well as to generalise to unseen datasets, outperforming multiple baseline strategies for manually selecting the best technique pairs based on the same training data.