 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
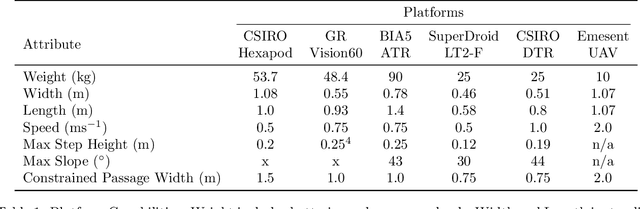
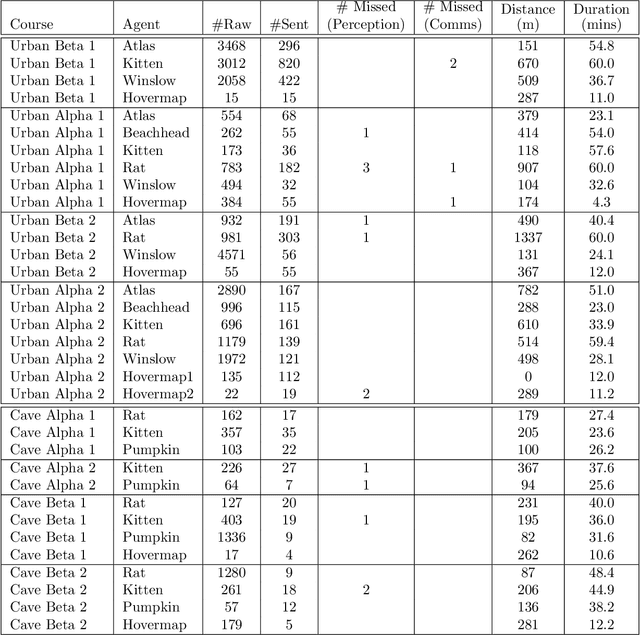
Heterogeneous robot teams with unified perception and autonomy: How Team CSIRO Data61 tied for the top score at the DARPA Subterranean Challenge
Feb 26, 2023



The DARPA Subterranean Challenge was designed for competitors to develop and deploy teams of autonomous robots to explore difficult unknown underground environments. Categorised in to human-made tunnels, underground urban infrastructure and natural caves, each of these subdomains had many challenging elements for robot perception, locomotion, navigation and autonomy. These included degraded wireless communication, poor visibility due to smoke, narrow passages and doorways, clutter, uneven ground, slippery and loose terrain, stairs, ledges, overhangs, dripping water, and dynamic obstacles that move to block paths among others. In the Final Event of this challenge held in September 2021, the course consisted of all three subdomains. The task was for the robot team to perform a scavenger hunt for a number of pre-defined artefacts within a limited time frame. Only one human supervisor was allowed to communicate with the robots once they were in the course. Points were scored when accurate detections and their locations were communicated back to the scoring server. A total of 8 teams competed in the finals held at the Mega Cavern in Louisville, KY, USA. This article describes the systems deployed by Team CSIRO Data61 that tied for the top score and won second place at the event.
What's in the Black Box? The False Negative Mechanisms Inside Object Detectors
Mar 15, 2022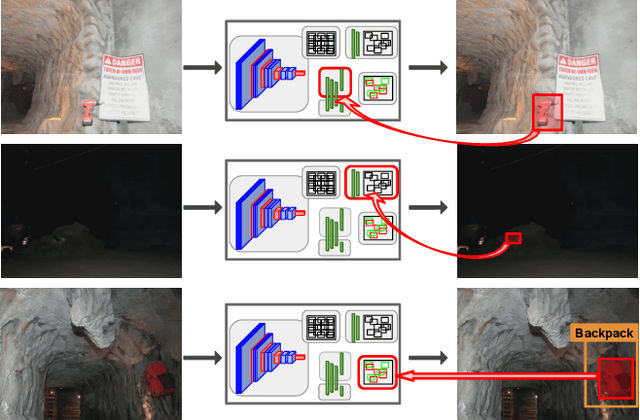
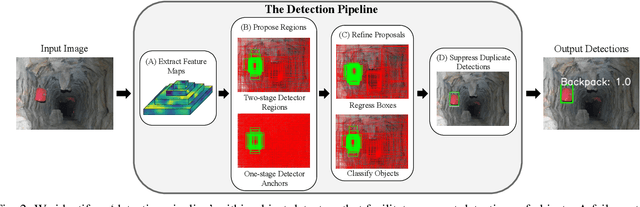
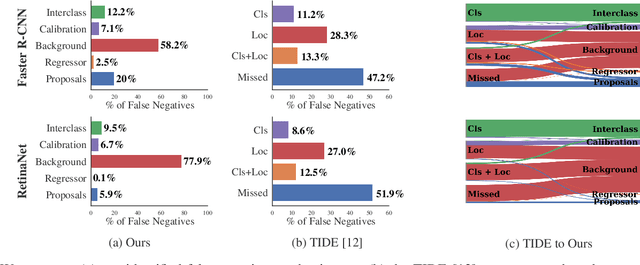

In object detection, false negatives arise when a detector fails to detect a target object. To understand why object detectors produce false negatives, we identify five 'false negative mechanisms', where each mechanism describes how a specific component inside the detector architecture failed. Focusing on two-stage and one-stage anchor-box object detector architectures, we introduce a framework for quantifying these false negative mechanisms. Using this framework, we investigate why Faster R-CNN and RetinaNet fail to detect objects in benchmark vision datasets and robotics datasets. We show that a detector's false negative mechanisms differ significantly between computer vision benchmark datasets and robotics deployment scenarios. This has implications for the translation of object detectors developed for benchmark datasets to robotics applications.
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021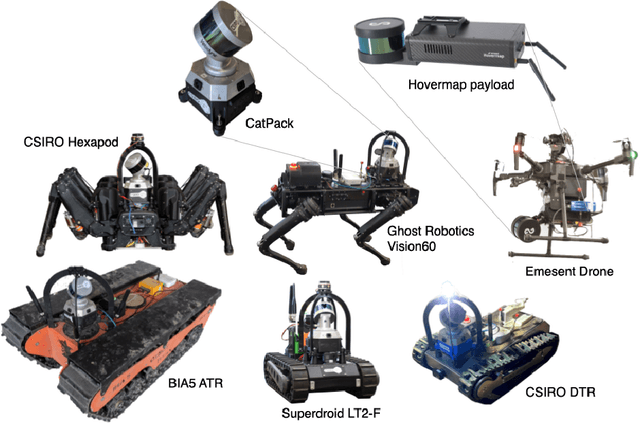
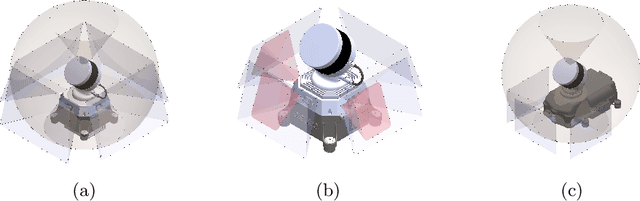
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
OVPC Mesh: 3D Free-space Representation for Local Ground Vehicle Navigation
Nov 26, 2018
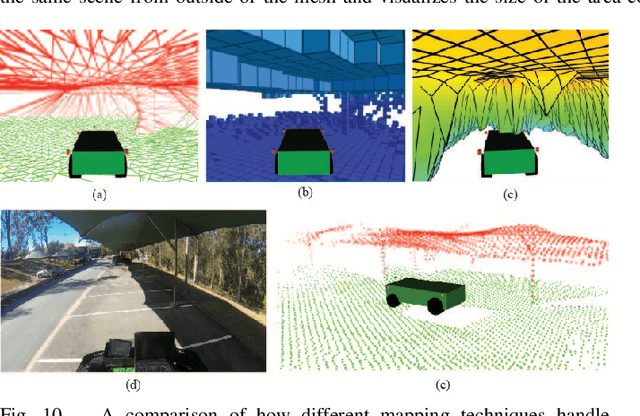
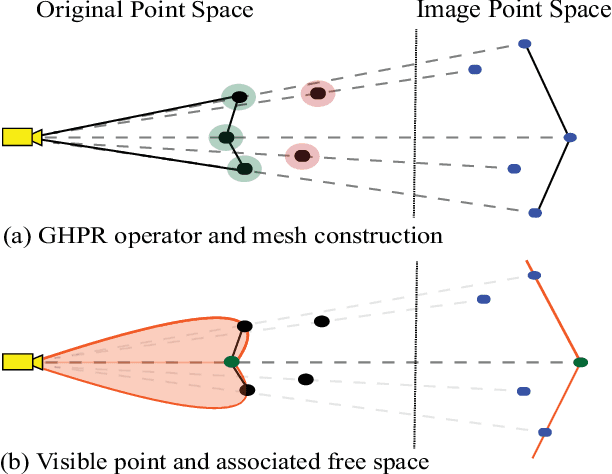

This paper presents a novel approach for local 3D environment representation for autonomous unmanned ground vehicle (UGV) navigation called On Visible Point Clouds Mesh(OVPC Mesh). Our approach represents the surrounding of the robot as a watertight 3D mesh generated from local point cloud data in order to represent the free space surrounding the robot. It is a conservative estimation of the free space and provides a desirable trade-off between representation precision and computational efficiency, without having to discretize the environment into a fixed grid size. Our experiments analyze the usability of the approach for UGV navigation in rough terrain, both in simulation and in a fully integrated real-world system. Additionally, we compare our approach to well-known state-of-the-art solutions, such as Octomap and Elevation Mapping and show that OVPC Mesh can provide reliable 3D information for trajectory planning while fulfilling real-time constraints.
Non-rigid Reconstruction with a Single Moving RGB-D Camera
May 30, 2018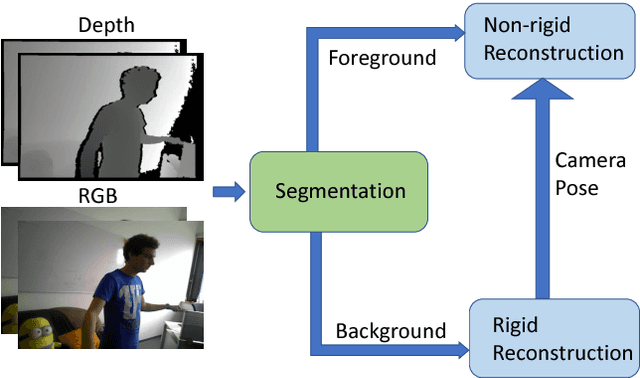


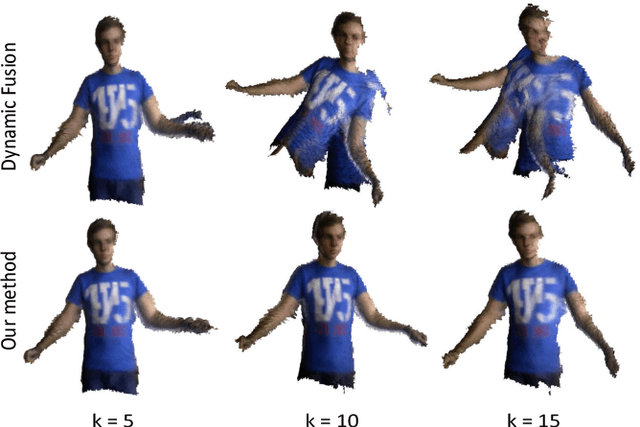
We present a novel non-rigid reconstruction method using a moving RGB-D camera. Current approaches use only non-rigid part of the scene and completely ignore the rigid background. Non-rigid parts often lack sufficient geometric and photometric information for tracking large frame-to-frame motion. Our approach uses camera pose estimated from the rigid background for foreground tracking. This enables robust foreground tracking in situations where large frame-to-frame motion occurs. Moreover, we are proposing a multi-scale deformation graph which improves non-rigid tracking without compromising the quality of the reconstruction. We are also contributing a synthetic dataset which is made publically available for evaluating non-rigid reconstruction methods. The dataset provides frame-by-frame ground truth geometry of the scene, the camera trajectory, and masks for background foreground. Experimental results show that our approach is more robust in handling larger frame-to-frame motions and provides better reconstruction compared to state-of-the-art approaches.