 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Masked Image Modeling: A Self-Supervised Pretraining Strategy Using Spatial and Frequency Domain Masking for Hyperspectral Data
May 06, 2025Hyperspectral images (HSIs) capture rich spectral signatures that reveal vital material properties, offering broad applicability across various domains. However, the scarcity of labeled HSI data limits the full potential of deep learning, especially for transformer-based architectures that require large-scale training. To address this constraint, we propose Spatial-Frequency Masked Image Modeling (SFMIM), a self-supervised pretraining strategy for hyperspectral data that utilizes the large portion of unlabeled data. Our method introduces a novel dual-domain masking mechanism that operates in both spatial and frequency domains. The input HSI cube is initially divided into non-overlapping patches along the spatial dimension, with each patch comprising the entire spectrum of its corresponding spatial location. In spatial masking, we randomly mask selected patches and train the model to reconstruct the masked inputs using the visible patches. Concurrently, in frequency masking, we remove portions of the frequency components of the input spectra and predict the missing frequencies. By learning to reconstruct these masked components, the transformer-based encoder captures higher-order spectral-spatial correlations. We evaluate our approach on three publicly available HSI classification benchmarks and demonstrate that it achieves state-of-the-art performance. Notably, our model shows rapid convergence during fine-tuning, highlighting the efficiency of our pretraining strategy.
Spectral-Enhanced Transformers: Leveraging Large-Scale Pretrained Models for Hyperspectral Object Tracking
Feb 26, 2025



Hyperspectral object tracking using snapshot mosaic cameras is emerging as it provides enhanced spectral information alongside spatial data, contributing to a more comprehensive understanding of material properties. Using transformers, which have consistently outperformed convolutional neural networks (CNNs) in learning better feature representations, would be expected to be effective for Hyperspectral object tracking. However, training large transformers necessitates extensive datasets and prolonged training periods. This is particularly critical for complex tasks like object tracking, and the scarcity of large datasets in the hyperspectral domain acts as a bottleneck in achieving the full potential of powerful transformer models. This paper proposes an effective methodology that adapts large pretrained transformer-based foundation models for hyperspectral object tracking. We propose an adaptive, learnable spatial-spectral token fusion module that can be extended to any transformer-based backbone for learning inherent spatial-spectral features in hyperspectral data. Furthermore, our model incorporates a cross-modality training pipeline that facilitates effective learning across hyperspectral datasets collected with different sensor modalities. This enables the extraction of complementary knowledge from additional modalities, whether or not they are present during testing. Our proposed model also achieves superior performance with minimal training iterations.
Inductive Graph Few-shot Class Incremental Learning
Nov 11, 2024



Node classification with Graph Neural Networks (GNN) under a fixed set of labels is well known in contrast to Graph Few-Shot Class Incremental Learning (GFSCIL), which involves learning a GNN classifier as graph nodes and classes growing over time sporadically. We introduce inductive GFSCIL that continually learns novel classes with newly emerging nodes while maintaining performance on old classes without accessing previous data. This addresses the practical concern of transductive GFSCIL, which requires storing the entire graph with historical data. Compared to the transductive GFSCIL, the inductive setting exacerbates catastrophic forgetting due to inaccessible previous data during incremental training, in addition to overfitting issue caused by label sparsity. Thus, we propose a novel method, called Topology-based class Augmentation and Prototype calibration (TAP). To be specific, it first creates a triple-branch multi-topology class augmentation method to enhance model generalization ability. As each incremental session receives a disjoint subgraph with nodes of novel classes, the multi-topology class augmentation method helps replicate such a setting in the base session to boost backbone versatility. In incremental learning, given the limited number of novel class samples, we propose an iterative prototype calibration to improve the separation of class prototypes. Furthermore, as backbone fine-tuning poses the feature distribution drift, prototypes of old classes start failing over time, we propose the prototype shift method for old classes to compensate for the drift. We showcase the proposed method on four datasets.
Spatioformer: A Geo-encoded Transformer for Large-Scale Plant Species Richness Prediction
Oct 25, 2024Earth observation data have shown promise in predicting species richness of vascular plants ($\alpha$-diversity), but extending this approach to large spatial scales is challenging because geographically distant regions may exhibit different compositions of plant species ($\beta$-diversity), resulting in a location-dependent relationship between richness and spectral measurements. In order to handle such geolocation dependency, we propose Spatioformer, where a novel geolocation encoder is coupled with the transformer model to encode geolocation context into remote sensing imagery. The Spatioformer model compares favourably to state-of-the-art models in richness predictions on a large-scale ground-truth richness dataset (HAVPlot) that consists of 68,170 in-situ richness samples covering diverse landscapes across Australia. The results demonstrate that geolocational information is advantageous in predicting species richness from satellite observations over large spatial scales. With Spatioformer, plant species richness maps over Australia are compiled from Landsat archive for the years from 2015 to 2023. The richness maps produced in this study reveal the spatiotemporal dynamics of plant species richness in Australia, providing supporting evidence to inform effective planning and policy development for plant diversity conservation. Regions of high richness prediction uncertainties are identified, highlighting the need for future in-situ surveys to be conducted in these areas to enhance the prediction accuracy.
Pair-VPR: Place-Aware Pre-training and Contrastive Pair Classification for Visual Place Recognition with Vision Transformers
Oct 09, 2024In this work we propose a novel joint training method for Visual Place Recognition (VPR), which simultaneously learns a global descriptor and a pair classifier for re-ranking. The pair classifier can predict whether a given pair of images are from the same place or not. The network only comprises Vision Transformer components for both the encoder and the pair classifier, and both components are trained using their respective class tokens. In existing VPR methods, typically the network is initialized using pre-trained weights from a generic image dataset such as ImageNet. In this work we propose an alternative pre-training strategy, by using Siamese Masked Image Modelling as a pre-training task. We propose a Place-aware image sampling procedure from a collection of large VPR datasets for pre-training our model, to learn visual features tuned specifically for VPR. By re-using the Mask Image Modelling encoder and decoder weights in the second stage of training, Pair-VPR can achieve state-of-the-art VPR performance across five benchmark datasets with a ViT-B encoder, along with further improvements in localization recall with larger encoders. The Pair-VPR website is: https://csiro-robotics.github.io/Pair-VPR.
PseudoNeg-MAE: Self-Supervised Point Cloud Learning using Conditional Pseudo-Negative Embeddings
Sep 24, 2024We propose PseudoNeg-MAE, a novel self-supervised learning framework that enhances global feature representation of point cloud mask autoencoder by making them both discriminative and sensitive to transformations. Traditional contrastive learning methods focus on achieving invariance, which can lead to the loss of valuable transformation-related information. In contrast, PseudoNeg-MAE explicitly models the relationship between original and transformed data points using a parametric network COPE, which learns the localized displacements caused by transformations within the latent space. However, jointly training COPE with the MAE leads to undesirable trivial solutions where COPE outputs collapse to an identity. To address this, we introduce a novel loss function incorporating pseudo-negatives, which effectively penalizes these trivial invariant solutions and promotes transformation sensitivity in the embeddings. We validate PseudoNeg-MAE on shape classification and relative pose estimation tasks, where PseudoNeg-MAE achieves state-of-the-art performance on the ModelNet40 and ScanObjectNN datasets under challenging evaluation protocols and demonstrates superior accuracy in estimating relative poses. These results show the effectiveness of PseudoNeg-MAE in learning discriminative and transformation-sensitive representations.
Learning Compact Channel Correlation Representation for LiDAR Place Recognition
Sep 24, 2024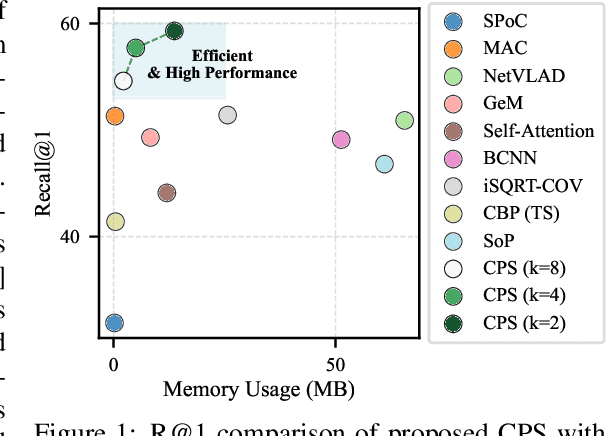

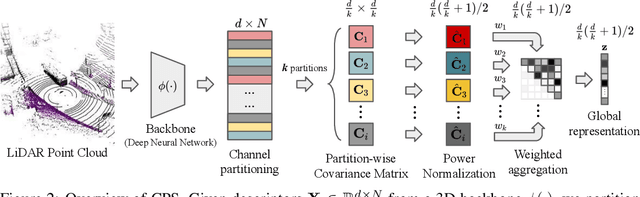
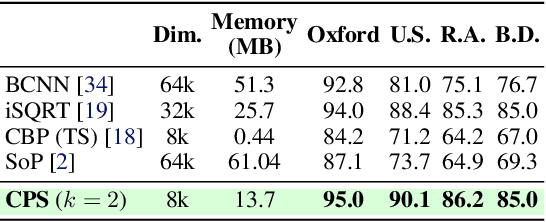
This paper presents a novel approach to learn compact channel correlation representation for LiDAR place recognition, called C3R, aimed at reducing the computational burden and dimensionality associated with traditional covariance pooling methods for place recognition tasks. Our method partitions the feature matrix into smaller groups, computes group-wise covariance matrices, and aggregates them via a learnable aggregation strategy. Matrix power normalization is applied to ensure stability. Theoretical analyses are also given to demonstrate the effectiveness of the proposed method, including its ability to preserve permutation invariance and maintain high mutual information between the original features and the aggregated representation. We conduct extensive experiments on four large-scale, public LiDAR place recognition datasets including Oxford RobotCar, In-house, MulRan, and WildPlaces datasets to validate our approach's superiority in accuracy, and robustness. Furthermore, we provide the quantitative results of our approach for a deeper understanding. The code will be released upon acceptance.
SOLVR: Submap Oriented LiDAR-Visual Re-Localisation
Sep 16, 2024This paper proposes SOLVR, a unified pipeline for learning based LiDAR-Visual re-localisation which performs place recognition and 6-DoF registration across sensor modalities. We propose a strategy to align the input sensor modalities by leveraging stereo image streams to produce metric depth predictions with pose information, followed by fusing multiple scene views from a local window using a probabilistic occupancy framework to expand the limited field-of-view of the camera. Additionally, SOLVR adopts a flexible definition of what constitutes positive examples for different training losses, allowing us to simultaneously optimise place recognition and registration performance. Furthermore, we replace RANSAC with a registration function that weights a simple least-squares fitting with the estimated inlier likelihood of sparse keypoint correspondences, improving performance in scenarios with a low inlier ratio between the query and retrieved place. Our experiments on the KITTI and KITTI360 datasets show that SOLVR achieves state-of-the-art performance for LiDAR-Visual place recognition and registration, particularly improving registration accuracy over larger distances between the query and retrieved place.
Object Registration in Neural Fields
Apr 29, 2024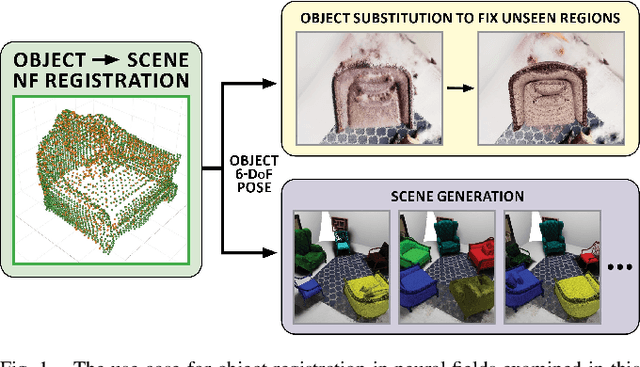

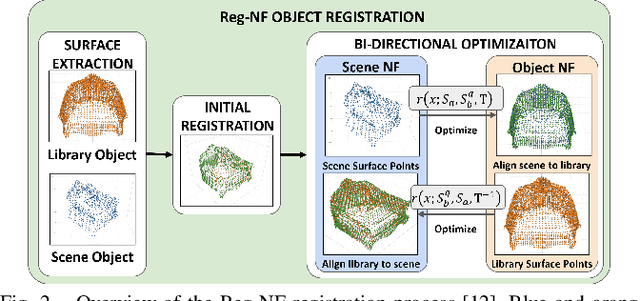

Neural fields provide a continuous scene representation of 3D geometry and appearance in a way which has great promise for robotics applications. One functionality that unlocks unique use-cases for neural fields in robotics is object 6-DoF registration. In this paper, we provide an expanded analysis of the recent Reg-NF neural field registration method and its use-cases within a robotics context. We showcase the scenario of determining the 6-DoF pose of known objects within a scene using scene and object neural field models. We show how this may be used to better represent objects within imperfectly modelled scenes and generate new scenes by substituting object neural field models into the scene.
Towards Long-term Robotics in the Wild
Apr 29, 2024



In this paper, we emphasise the critical importance of large-scale datasets for advancing field robotics capabilities, particularly in natural environments. While numerous datasets exist for urban and suburban settings, those tailored to natural environments are scarce. Our recent benchmarks WildPlaces and WildScenes address this gap by providing synchronised image, lidar, semantic and accurate 6-DoF pose information in forest-type environments. We highlight the multi-modal nature of this dataset and discuss and demonstrate its utility in various downstream tasks, such as place recognition and 2D and 3D semantic segmentation tasks.