 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Attention in a Lightweight TCN for Efficient WiFi CSI-Based Human Activity Recognition
Jun 01, 2026Human Action Recognition (HAR) using WiFi Channel State Information (CSI) has gained increasing attention due to its non-contact, low-cost, and privacy-preserving nature. However, existing learning-based approaches largely rely on deep, computationally intensive architectures to implicitly capture motion dynamics from CSI measurements, thereby increasing model complexity and reducing efficiency. Instead, we argue that incorporating appropriate inductive biases tailored to the physical characteristics of CSI signals enables more efficient and effective learning. In this work, we propose a compact temporal convolutional network (TCN)-based framework that explicitly incorporates motion-aware inductive biases into feature learning. Specifically, we introduce a Doppler-energy-guided temporal attention mechanism in feature space to emphasize motion-salient time segments, and a variance-driven channel attention module to weight informative subcarriers based on temporal motion statistics adaptively. By integrating these domain-specific priors, the proposed model effectively captures motion dynamics without increasing architectural depth. Extensive experiments on multiple benchmark datasets demonstrate that our approach achieves superior performance compared to deeper baselines, while significantly reducing parameter count and computational cost.
DeepForgeSeal: Latent Space-Driven Semi-Fragile Watermarking for Deepfake Detection Using Multi-Agent Adversarial Reinforcement Learning
Nov 07, 2025Rapid advances in generative AI have led to increasingly realistic deepfakes, posing growing challenges for law enforcement and public trust. Existing passive deepfake detectors struggle to keep pace, largely due to their dependence on specific forgery artifacts, which limits their ability to generalize to new deepfake types. Proactive deepfake detection using watermarks has emerged to address the challenge of identifying high-quality synthetic media. However, these methods often struggle to balance robustness against benign distortions with sensitivity to malicious tampering. This paper introduces a novel deep learning framework that harnesses high-dimensional latent space representations and the Multi-Agent Adversarial Reinforcement Learning (MAARL) paradigm to develop a robust and adaptive watermarking approach. Specifically, we develop a learnable watermark embedder that operates in the latent space, capturing high-level image semantics, while offering precise control over message encoding and extraction. The MAARL paradigm empowers the learnable watermarking agent to pursue an optimal balance between robustness and fragility by interacting with a dynamic curriculum of benign and malicious image manipulations simulated by an adversarial attacker agent. Comprehensive evaluations on the CelebA and CelebA-HQ benchmarks reveal that our method consistently outperforms state-of-the-art approaches, achieving improvements of over 4.5% on CelebA and more than 5.3% on CelebA-HQ under challenging manipulation scenarios.
Transforming volcanic monitoring: A dataset and benchmark for onboard volcano activity detection
Oct 27, 2025Natural disasters, such as volcanic eruptions, pose significant challenges to daily life and incur considerable global economic losses. The emergence of next-generation small-satellites, capable of constellation-based operations, offers unparalleled opportunities for near-real-time monitoring and onboard processing of such events. However, a major bottleneck remains the lack of extensive annotated datasets capturing volcanic activity, which hinders the development of robust detection systems. This paper introduces a novel dataset explicitly designed for volcanic activity and eruption detection, encompassing diverse volcanoes worldwide. The dataset provides binary annotations to identify volcanic anomalies or non-anomalies, covering phenomena such as temperature anomalies, eruptions, and volcanic ash emissions. These annotations offer a foundational resource for developing and evaluating detection models, addressing a critical gap in volcanic monitoring research. Additionally, we present comprehensive benchmarks using state-of-the-art models to establish baselines for future studies. Furthermore, we explore the potential for deploying these models onboard next-generation satellites. Using the Intel Movidius Myriad X VPU as a testbed, we demonstrate the feasibility of volcanic activity detection directly onboard. This capability significantly reduces latency and enhances response times, paving the way for advanced early warning systems. This paves the way for innovative solutions in volcanic disaster management, encouraging further exploration and refinement of onboard monitoring technologies.
Cross-Branch Orthogonality for Improved Generalization in Face Deepfake Detection
May 08, 2025



Remarkable advancements in generative AI technology have given rise to a spectrum of novel deepfake categories with unprecedented leaps in their realism, and deepfakes are increasingly becoming a nuisance to law enforcement authorities and the general public. In particular, we observe alarming levels of confusion, deception, and loss of faith regarding multimedia content within society caused by face deepfakes, and existing deepfake detectors are struggling to keep up with the pace of improvements in deepfake generation. This is primarily due to their reliance on specific forgery artifacts, which limits their ability to generalise and detect novel deepfake types. To combat the spread of malicious face deepfakes, this paper proposes a new strategy that leverages coarse-to-fine spatial information, semantic information, and their interactions while ensuring feature distinctiveness and reducing the redundancy of the modelled features. A novel feature orthogonality-based disentanglement strategy is introduced to ensure branch-level and cross-branch feature disentanglement, which allows us to integrate multiple feature vectors without adding complexity to the feature space or compromising generalisation. Comprehensive experiments on three public benchmarks: FaceForensics++, Celeb-DF, and the Deepfake Detection Challenge (DFDC) show that these design choices enable the proposed approach to outperform current state-of-the-art methods by 5% on the Celeb-DF dataset and 7% on the DFDC dataset in a cross-dataset evaluation setting.
Dual-Domain Masked Image Modeling: A Self-Supervised Pretraining Strategy Using Spatial and Frequency Domain Masking for Hyperspectral Data
May 06, 2025

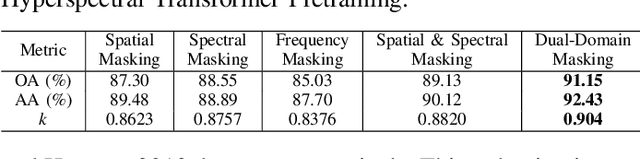
Hyperspectral images (HSIs) capture rich spectral signatures that reveal vital material properties, offering broad applicability across various domains. However, the scarcity of labeled HSI data limits the full potential of deep learning, especially for transformer-based architectures that require large-scale training. To address this constraint, we propose Spatial-Frequency Masked Image Modeling (SFMIM), a self-supervised pretraining strategy for hyperspectral data that utilizes the large portion of unlabeled data. Our method introduces a novel dual-domain masking mechanism that operates in both spatial and frequency domains. The input HSI cube is initially divided into non-overlapping patches along the spatial dimension, with each patch comprising the entire spectrum of its corresponding spatial location. In spatial masking, we randomly mask selected patches and train the model to reconstruct the masked inputs using the visible patches. Concurrently, in frequency masking, we remove portions of the frequency components of the input spectra and predict the missing frequencies. By learning to reconstruct these masked components, the transformer-based encoder captures higher-order spectral-spatial correlations. We evaluate our approach on three publicly available HSI classification benchmarks and demonstrate that it achieves state-of-the-art performance. Notably, our model shows rapid convergence during fine-tuning, highlighting the efficiency of our pretraining strategy.
Spectral-Enhanced Transformers: Leveraging Large-Scale Pretrained Models for Hyperspectral Object Tracking
Feb 26, 2025



Hyperspectral object tracking using snapshot mosaic cameras is emerging as it provides enhanced spectral information alongside spatial data, contributing to a more comprehensive understanding of material properties. Using transformers, which have consistently outperformed convolutional neural networks (CNNs) in learning better feature representations, would be expected to be effective for Hyperspectral object tracking. However, training large transformers necessitates extensive datasets and prolonged training periods. This is particularly critical for complex tasks like object tracking, and the scarcity of large datasets in the hyperspectral domain acts as a bottleneck in achieving the full potential of powerful transformer models. This paper proposes an effective methodology that adapts large pretrained transformer-based foundation models for hyperspectral object tracking. We propose an adaptive, learnable spatial-spectral token fusion module that can be extended to any transformer-based backbone for learning inherent spatial-spectral features in hyperspectral data. Furthermore, our model incorporates a cross-modality training pipeline that facilitates effective learning across hyperspectral datasets collected with different sensor modalities. This enables the extraction of complementary knowledge from additional modalities, whether or not they are present during testing. Our proposed model also achieves superior performance with minimal training iterations.
Damage Assessment after Natural Disasters with UAVs: Semantic Feature Extraction using Deep Learning
Dec 14, 2024



Unmanned aerial vehicle-assisted disaster recovery missions have been promoted recently due to their reliability and flexibility. Machine learning algorithms running onboard significantly enhance the utility of UAVs by enabling real-time data processing and efficient decision-making, despite being in a resource-constrained environment. However, the limited bandwidth and intermittent connectivity make transmitting the outputs to ground stations challenging. This paper proposes a novel semantic extractor that can be adopted into any machine learning downstream task for identifying the critical data required for decision-making. The semantic extractor can be executed onboard which results in a reduction of data that needs to be transmitted to ground stations. We test the proposed architecture together with the semantic extractor on two publicly available datasets, FloodNet and RescueNet, for two downstream tasks: visual question answering and disaster damage level classification. Our experimental results demonstrate the proposed method maintains high accuracy across different downstream tasks while significantly reducing the volume of transmitted data, highlighting the effectiveness of our semantic extractor in capturing task-specific salient information.
Physics Augmented Tuple Transformer for Autism Severity Level Detection
Sep 27, 2024



Early diagnosis of Autism Spectrum Disorder (ASD) is an effective and favorable step towards enhancing the health and well-being of children with ASD. Manual ASD diagnosis testing is labor-intensive, complex, and prone to human error due to several factors contaminating the results. This paper proposes a novel framework that exploits the laws of physics for ASD severity recognition. The proposed physics-informed neural network architecture encodes the behaviour of the subject extracted by observing a part of the skeleton-based motion trajectory in a higher dimensional latent space. Two decoders, namely physics-based and non-physics-based decoder, use this latent embedding and predict the future motion patterns. The physics branch leverages the laws of physics that apply to a skeleton sequence in the prediction process while the non-physics-based branch is optimised to minimise the difference between the predicted and actual motion of the subject. A classifier also leverages the same latent space embeddings to recognise the ASD severity. This dual generative objective explicitly forces the network to compare the actual behaviour of the subject with the general normal behaviour of children that are governed by the laws of physics, aiding the ASD recognition task. The proposed method attains state-of-the-art performance on multiple ASD diagnosis benchmarks. To illustrate the utility of the proposed framework beyond the task ASD diagnosis, we conduct a third experiment using a publicly available benchmark for the task of fall prediction and demonstrate the superiority of our model.
PseudoNeg-MAE: Self-Supervised Point Cloud Learning using Conditional Pseudo-Negative Embeddings
Sep 24, 2024We propose PseudoNeg-MAE, a novel self-supervised learning framework that enhances global feature representation of point cloud mask autoencoder by making them both discriminative and sensitive to transformations. Traditional contrastive learning methods focus on achieving invariance, which can lead to the loss of valuable transformation-related information. In contrast, PseudoNeg-MAE explicitly models the relationship between original and transformed data points using a parametric network COPE, which learns the localized displacements caused by transformations within the latent space. However, jointly training COPE with the MAE leads to undesirable trivial solutions where COPE outputs collapse to an identity. To address this, we introduce a novel loss function incorporating pseudo-negatives, which effectively penalizes these trivial invariant solutions and promotes transformation sensitivity in the embeddings. We validate PseudoNeg-MAE on shape classification and relative pose estimation tasks, where PseudoNeg-MAE achieves state-of-the-art performance on the ModelNet40 and ScanObjectNN datasets under challenging evaluation protocols and demonstrates superior accuracy in estimating relative poses. These results show the effectiveness of PseudoNeg-MAE in learning discriminative and transformation-sensitive representations.
FactoFormer: Factorized Hyperspectral Transformers with Self-Supervised Pre-Training
Sep 18, 2023Hyperspectral images (HSIs) contain rich spectral and spatial information. Motivated by the success of transformers in the field of natural language processing and computer vision where they have shown the ability to learn long range dependencies within input data, recent research has focused on using transformers for HSIs. However, current state-of-the-art hyperspectral transformers only tokenize the input HSI sample along the spectral dimension, resulting in the under-utilization of spatial information. Moreover, transformers are known to be data-hungry and their performance relies heavily on large-scale pre-training, which is challenging due to limited annotated hyperspectral data. Therefore, the full potential of HSI transformers has not been fully realized. To overcome these limitations, we propose a novel factorized spectral-spatial transformer that incorporates factorized self-supervised pre-training procedures, leading to significant improvements in performance. The factorization of the inputs allows the spectral and spatial transformers to better capture the interactions within the hyperspectral data cubes. Inspired by masked image modeling pre-training, we also devise efficient masking strategies for pre-training each of the spectral and spatial transformers. We conduct experiments on three publicly available datasets for HSI classification task and demonstrate that our model achieves state-of-the-art performance in all three datasets. The code for our model will be made available at https://github.com/csiro-robotics/factoformer.