 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOTFLoc++: End-to-End Hierarchical LiDAR Place Recognition, Re-Ranking, and 6-DoF Metric Localisation in Forests
Nov 12, 2025



This article presents HOTFLoc++, an end-to-end framework for LiDAR place recognition, re-ranking, and 6-DoF metric localisation in forests. Leveraging an octree-based transformer, our approach extracts hierarchical local descriptors at multiple granularities to increase robustness to clutter, self-similarity, and viewpoint changes in challenging scenarios, including ground-to-ground and ground-to-aerial in forest and urban environments. We propose a learnable multi-scale geometric verification module to reduce re-ranking failures in the presence of degraded single-scale correspondences. Our coarse-to-fine registration approach achieves comparable or lower localisation errors to baselines, with runtime improvements of two orders of magnitude over RANSAC for dense point clouds. Experimental results on public datasets show the superiority of our approach compared to state-of-the-art methods, achieving an average Recall@1 of 90.7% on CS-Wild-Places: an improvement of 29.6 percentage points over baselines, while maintaining high performance on single-source benchmarks with an average Recall@1 of 91.7% and 96.0% on Wild-Places and MulRan, respectively. Our method achieves under 2 m and 5 degrees error for 97.2% of 6-DoF registration attempts, with our multi-scale re-ranking module reducing localisation errors by ~2$\times$ on average. The code will be available upon acceptance.
Transforming volcanic monitoring: A dataset and benchmark for onboard volcano activity detection
Oct 27, 2025Natural disasters, such as volcanic eruptions, pose significant challenges to daily life and incur considerable global economic losses. The emergence of next-generation small-satellites, capable of constellation-based operations, offers unparalleled opportunities for near-real-time monitoring and onboard processing of such events. However, a major bottleneck remains the lack of extensive annotated datasets capturing volcanic activity, which hinders the development of robust detection systems. This paper introduces a novel dataset explicitly designed for volcanic activity and eruption detection, encompassing diverse volcanoes worldwide. The dataset provides binary annotations to identify volcanic anomalies or non-anomalies, covering phenomena such as temperature anomalies, eruptions, and volcanic ash emissions. These annotations offer a foundational resource for developing and evaluating detection models, addressing a critical gap in volcanic monitoring research. Additionally, we present comprehensive benchmarks using state-of-the-art models to establish baselines for future studies. Furthermore, we explore the potential for deploying these models onboard next-generation satellites. Using the Intel Movidius Myriad X VPU as a testbed, we demonstrate the feasibility of volcanic activity detection directly onboard. This capability significantly reduces latency and enhances response times, paving the way for advanced early warning systems. This paves the way for innovative solutions in volcanic disaster management, encouraging further exploration and refinement of onboard monitoring technologies.
HOTFormerLoc: Hierarchical Octree Transformer for Versatile Lidar Place Recognition Across Ground and Aerial Views
Mar 11, 2025
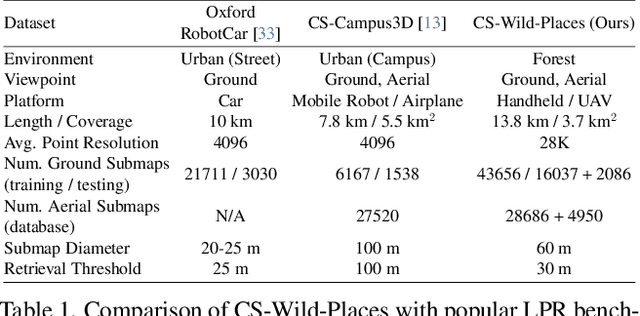

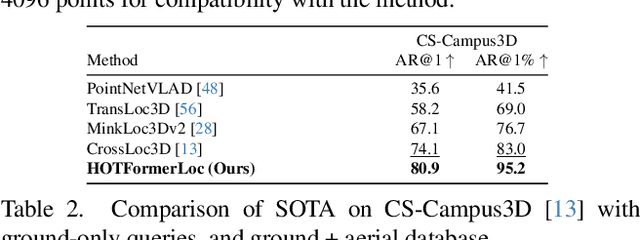
We present HOTFormerLoc, a novel and versatile Hierarchical Octree-based Transformer, for large-scale 3D place recognition in both ground-to-ground and ground-to-aerial scenarios across urban and forest environments. We propose an octree-based multi-scale attention mechanism that captures spatial and semantic features across granularities. To address the variable density of point distributions from spinning lidar, we present cylindrical octree attention windows to reflect the underlying distribution during attention. We introduce relay tokens to enable efficient global-local interactions and multi-scale representation learning at reduced computational cost. Our pyramid attentional pooling then synthesises a robust global descriptor for end-to-end place recognition in challenging environments. In addition, we introduce CS-Wild-Places, a novel 3D cross-source dataset featuring point cloud data from aerial and ground lidar scans captured in dense forests. Point clouds in CS-Wild-Places contain representational gaps and distinctive attributes such as varying point densities and noise patterns, making it a challenging benchmark for cross-view localisation in the wild. HOTFormerLoc achieves a top-1 average recall improvement of 5.5% - 11.5% on the CS-Wild-Places benchmark. Furthermore, it consistently outperforms SOTA 3D place recognition methods, with an average performance gain of 5.8% on well-established urban and forest datasets. The code and CS-Wild-Places benchmark is available at https://csiro-robotics.github.io/HOTFormerLoc .
Multimodal Fusion Learning with Dual Attention for Medical Imaging
Dec 02, 2024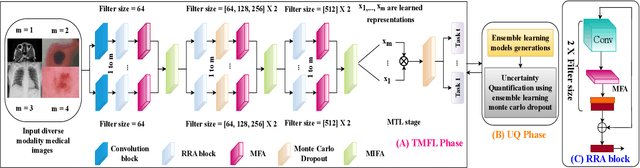

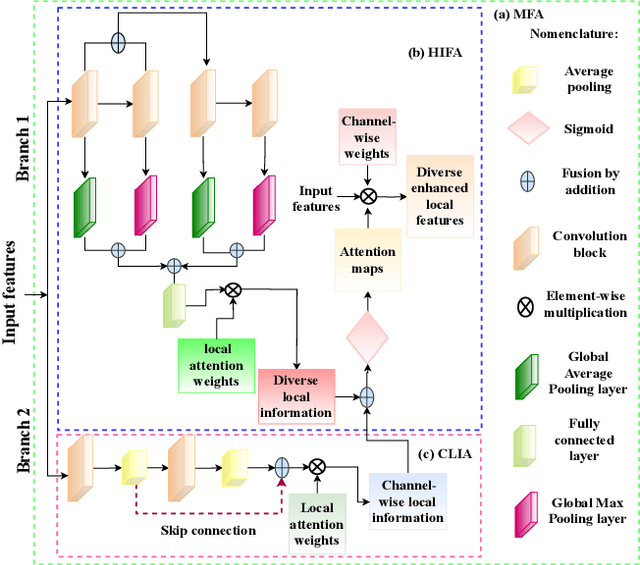

Multimodal fusion learning has shown significant promise in classifying various diseases such as skin cancer and brain tumors. However, existing methods face three key limitations. First, they often lack generalizability to other diagnosis tasks due to their focus on a particular disease. Second, they do not fully leverage multiple health records from diverse modalities to learn robust complementary information. And finally, they typically rely on a single attention mechanism, missing the benefits of multiple attention strategies within and across various modalities. To address these issues, this paper proposes a dual robust information fusion attention mechanism (DRIFA) that leverages two attention modules, i.e. multi-branch fusion attention module and the multimodal information fusion attention module. DRIFA can be integrated with any deep neural network, forming a multimodal fusion learning framework denoted as DRIFA-Net. We show that the multi-branch fusion attention of DRIFA learns enhanced representations for each modality, such as dermoscopy, pap smear, MRI, and CT-scan, whereas multimodal information fusion attention module learns more refined multimodal shared representations, improving the network's generalization across multiple tasks and enhancing overall performance. Additionally, to estimate the uncertainty of DRIFA-Net predictions, we have employed an ensemble Monte Carlo dropout strategy. Extensive experiments on five publicly available datasets with diverse modalities demonstrate that our approach consistently outperforms state-of-the-art methods. The code is available at https://github.com/misti1203/DRIFA-Net.
* 10 pages
Online 6DoF Pose Estimation in Forests using Cross-View Factor Graph Optimisation and Deep Learned Re-localisation
Sep 25, 2024



This paper presents a novel approach for robust global localisation and 6DoF pose estimation of ground robots in forest environments by leveraging cross-view factor graph optimisation and deep-learned re-localisation. The proposed method addresses the challenges of aligning aerial and ground data for pose estimation, which is crucial for accurate point-to-point navigation in GPS-denied environments. By integrating information from both perspectives into a factor graph framework, our approach effectively estimates the robot's global position and orientation. We validate the performance of our method through extensive experiments in diverse forest scenarios, demonstrating its superiority over existing baselines in terms of accuracy and robustness in these challenging environments. Experimental results show that our proposed localisation system can achieve drift-free localisation with bounded positioning errors, ensuring reliable and safe robot navigation under canopies.
Pre-training with Random Orthogonal Projection Image Modeling
Oct 28, 2023

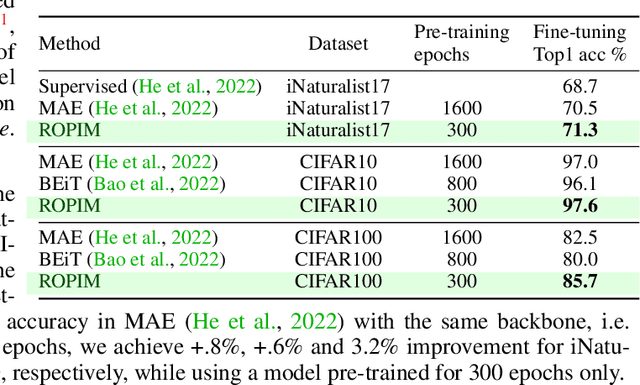

Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
FactoFormer: Factorized Hyperspectral Transformers with Self-Supervised Pre-Training
Sep 18, 2023Hyperspectral images (HSIs) contain rich spectral and spatial information. Motivated by the success of transformers in the field of natural language processing and computer vision where they have shown the ability to learn long range dependencies within input data, recent research has focused on using transformers for HSIs. However, current state-of-the-art hyperspectral transformers only tokenize the input HSI sample along the spectral dimension, resulting in the under-utilization of spatial information. Moreover, transformers are known to be data-hungry and their performance relies heavily on large-scale pre-training, which is challenging due to limited annotated hyperspectral data. Therefore, the full potential of HSI transformers has not been fully realized. To overcome these limitations, we propose a novel factorized spectral-spatial transformer that incorporates factorized self-supervised pre-training procedures, leading to significant improvements in performance. The factorization of the inputs allows the spectral and spatial transformers to better capture the interactions within the hyperspectral data cubes. Inspired by masked image modeling pre-training, we also devise efficient masking strategies for pre-training each of the spectral and spatial transformers. We conduct experiments on three publicly available datasets for HSI classification task and demonstrate that our model achieves state-of-the-art performance in all three datasets. The code for our model will be made available at https://github.com/csiro-robotics/factoformer.
Deep Robust Multi-Robot Re-localisation in Natural Environments
Jul 26, 2023The success of re-localisation has crucial implications for the practical deployment of robots operating within a prior map or relative to one another in real-world scenarios. Using single-modality, place recognition and localisation can be compromised in challenging environments such as forests. To address this, we propose a strategy to prevent lidar-based re-localisation failure using lidar-image cross-modality. Our solution relies on self-supervised 2D-3D feature matching to predict alignment and misalignment. Leveraging a deep network for lidar feature extraction and relative pose estimation between point clouds, we train a model to evaluate the estimated transformation. A model predicting the presence of misalignment is learned by analysing image-lidar similarity in the embedding space and the geometric constraints available within the region seen in both modalities in Euclidean space. Experimental results using real datasets (offline and online modes) demonstrate the effectiveness of the proposed pipeline for robust re-localisation in unstructured, natural environments.