 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Masked Image Modeling: A Self-Supervised Pretraining Strategy Using Spatial and Frequency Domain Masking for Hyperspectral Data
May 06, 2025Hyperspectral images (HSIs) capture rich spectral signatures that reveal vital material properties, offering broad applicability across various domains. However, the scarcity of labeled HSI data limits the full potential of deep learning, especially for transformer-based architectures that require large-scale training. To address this constraint, we propose Spatial-Frequency Masked Image Modeling (SFMIM), a self-supervised pretraining strategy for hyperspectral data that utilizes the large portion of unlabeled data. Our method introduces a novel dual-domain masking mechanism that operates in both spatial and frequency domains. The input HSI cube is initially divided into non-overlapping patches along the spatial dimension, with each patch comprising the entire spectrum of its corresponding spatial location. In spatial masking, we randomly mask selected patches and train the model to reconstruct the masked inputs using the visible patches. Concurrently, in frequency masking, we remove portions of the frequency components of the input spectra and predict the missing frequencies. By learning to reconstruct these masked components, the transformer-based encoder captures higher-order spectral-spatial correlations. We evaluate our approach on three publicly available HSI classification benchmarks and demonstrate that it achieves state-of-the-art performance. Notably, our model shows rapid convergence during fine-tuning, highlighting the efficiency of our pretraining strategy.
Spectral-Enhanced Transformers: Leveraging Large-Scale Pretrained Models for Hyperspectral Object Tracking
Feb 26, 2025



Hyperspectral object tracking using snapshot mosaic cameras is emerging as it provides enhanced spectral information alongside spatial data, contributing to a more comprehensive understanding of material properties. Using transformers, which have consistently outperformed convolutional neural networks (CNNs) in learning better feature representations, would be expected to be effective for Hyperspectral object tracking. However, training large transformers necessitates extensive datasets and prolonged training periods. This is particularly critical for complex tasks like object tracking, and the scarcity of large datasets in the hyperspectral domain acts as a bottleneck in achieving the full potential of powerful transformer models. This paper proposes an effective methodology that adapts large pretrained transformer-based foundation models for hyperspectral object tracking. We propose an adaptive, learnable spatial-spectral token fusion module that can be extended to any transformer-based backbone for learning inherent spatial-spectral features in hyperspectral data. Furthermore, our model incorporates a cross-modality training pipeline that facilitates effective learning across hyperspectral datasets collected with different sensor modalities. This enables the extraction of complementary knowledge from additional modalities, whether or not they are present during testing. Our proposed model also achieves superior performance with minimal training iterations.
WildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Pre-training with Random Orthogonal Projection Image Modeling
Oct 28, 2023

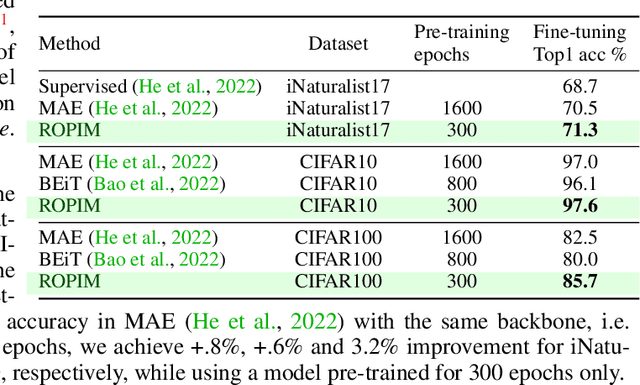

Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
FactoFormer: Factorized Hyperspectral Transformers with Self-Supervised Pre-Training
Sep 18, 2023Hyperspectral images (HSIs) contain rich spectral and spatial information. Motivated by the success of transformers in the field of natural language processing and computer vision where they have shown the ability to learn long range dependencies within input data, recent research has focused on using transformers for HSIs. However, current state-of-the-art hyperspectral transformers only tokenize the input HSI sample along the spectral dimension, resulting in the under-utilization of spatial information. Moreover, transformers are known to be data-hungry and their performance relies heavily on large-scale pre-training, which is challenging due to limited annotated hyperspectral data. Therefore, the full potential of HSI transformers has not been fully realized. To overcome these limitations, we propose a novel factorized spectral-spatial transformer that incorporates factorized self-supervised pre-training procedures, leading to significant improvements in performance. The factorization of the inputs allows the spectral and spatial transformers to better capture the interactions within the hyperspectral data cubes. Inspired by masked image modeling pre-training, we also devise efficient masking strategies for pre-training each of the spectral and spatial transformers. We conduct experiments on three publicly available datasets for HSI classification task and demonstrate that our model achieves state-of-the-art performance in all three datasets. The code for our model will be made available at https://github.com/csiro-robotics/factoformer.