 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOTFLoc++: End-to-End Hierarchical LiDAR Place Recognition, Re-Ranking, and 6-DoF Metric Localisation in Forests
Nov 12, 2025



This article presents HOTFLoc++, an end-to-end framework for LiDAR place recognition, re-ranking, and 6-DoF metric localisation in forests. Leveraging an octree-based transformer, our approach extracts hierarchical local descriptors at multiple granularities to increase robustness to clutter, self-similarity, and viewpoint changes in challenging scenarios, including ground-to-ground and ground-to-aerial in forest and urban environments. We propose a learnable multi-scale geometric verification module to reduce re-ranking failures in the presence of degraded single-scale correspondences. Our coarse-to-fine registration approach achieves comparable or lower localisation errors to baselines, with runtime improvements of two orders of magnitude over RANSAC for dense point clouds. Experimental results on public datasets show the superiority of our approach compared to state-of-the-art methods, achieving an average Recall@1 of 90.7% on CS-Wild-Places: an improvement of 29.6 percentage points over baselines, while maintaining high performance on single-source benchmarks with an average Recall@1 of 91.7% and 96.0% on Wild-Places and MulRan, respectively. Our method achieves under 2 m and 5 degrees error for 97.2% of 6-DoF registration attempts, with our multi-scale re-ranking module reducing localisation errors by ~2$\times$ on average. The code will be available upon acceptance.
Cross-Branch Orthogonality for Improved Generalization in Face Deepfake Detection
May 08, 2025



Remarkable advancements in generative AI technology have given rise to a spectrum of novel deepfake categories with unprecedented leaps in their realism, and deepfakes are increasingly becoming a nuisance to law enforcement authorities and the general public. In particular, we observe alarming levels of confusion, deception, and loss of faith regarding multimedia content within society caused by face deepfakes, and existing deepfake detectors are struggling to keep up with the pace of improvements in deepfake generation. This is primarily due to their reliance on specific forgery artifacts, which limits their ability to generalise and detect novel deepfake types. To combat the spread of malicious face deepfakes, this paper proposes a new strategy that leverages coarse-to-fine spatial information, semantic information, and their interactions while ensuring feature distinctiveness and reducing the redundancy of the modelled features. A novel feature orthogonality-based disentanglement strategy is introduced to ensure branch-level and cross-branch feature disentanglement, which allows us to integrate multiple feature vectors without adding complexity to the feature space or compromising generalisation. Comprehensive experiments on three public benchmarks: FaceForensics++, Celeb-DF, and the Deepfake Detection Challenge (DFDC) show that these design choices enable the proposed approach to outperform current state-of-the-art methods by 5% on the Celeb-DF dataset and 7% on the DFDC dataset in a cross-dataset evaluation setting.
HOTFormerLoc: Hierarchical Octree Transformer for Versatile Lidar Place Recognition Across Ground and Aerial Views
Mar 11, 2025
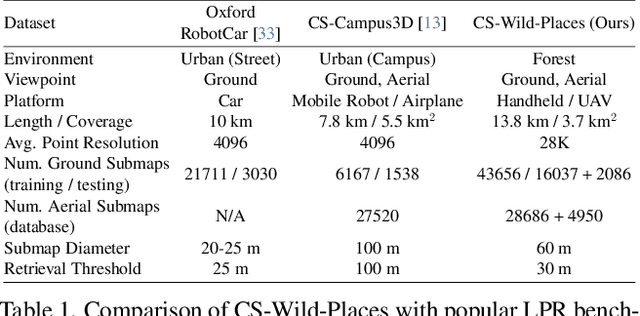

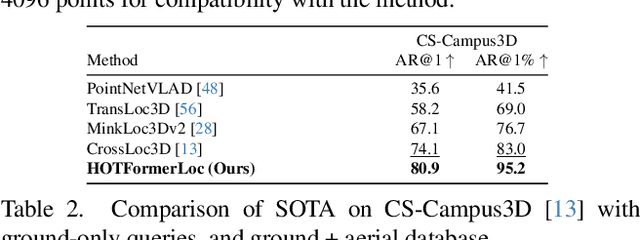
We present HOTFormerLoc, a novel and versatile Hierarchical Octree-based Transformer, for large-scale 3D place recognition in both ground-to-ground and ground-to-aerial scenarios across urban and forest environments. We propose an octree-based multi-scale attention mechanism that captures spatial and semantic features across granularities. To address the variable density of point distributions from spinning lidar, we present cylindrical octree attention windows to reflect the underlying distribution during attention. We introduce relay tokens to enable efficient global-local interactions and multi-scale representation learning at reduced computational cost. Our pyramid attentional pooling then synthesises a robust global descriptor for end-to-end place recognition in challenging environments. In addition, we introduce CS-Wild-Places, a novel 3D cross-source dataset featuring point cloud data from aerial and ground lidar scans captured in dense forests. Point clouds in CS-Wild-Places contain representational gaps and distinctive attributes such as varying point densities and noise patterns, making it a challenging benchmark for cross-view localisation in the wild. HOTFormerLoc achieves a top-1 average recall improvement of 5.5% - 11.5% on the CS-Wild-Places benchmark. Furthermore, it consistently outperforms SOTA 3D place recognition methods, with an average performance gain of 5.8% on well-established urban and forest datasets. The code and CS-Wild-Places benchmark is available at https://csiro-robotics.github.io/HOTFormerLoc .
PDV: Prompt Directional Vectors for Zero-shot Composed Image Retrieval
Feb 11, 2025Zero-shot composed image retrieval (ZS-CIR) enables image search using a reference image and text prompt without requiring specialized text-image composition networks trained on large-scale paired data. However, current ZS-CIR approaches face three critical limitations in their reliance on composed text embeddings: static query embedding representations, insufficient utilization of image embeddings, and suboptimal performance when fusing text and image embeddings. To address these challenges, we introduce the Prompt Directional Vector (PDV), a simple yet effective training-free enhancement that captures semantic modifications induced by user prompts. PDV enables three key improvements: (1) dynamic composed text embeddings where prompt adjustments are controllable via a scaling factor, (2) composed image embeddings through semantic transfer from text prompts to image features, and (3) weighted fusion of composed text and image embeddings that enhances retrieval by balancing visual and semantic similarity. Our approach serves as a plug-and-play enhancement for existing ZS-CIR methods with minimal computational overhead. Extensive experiments across multiple benchmarks demonstrate that PDV consistently improves retrieval performance when integrated with state-of-the-art ZS-CIR approaches, particularly for methods that generate accurate compositional embeddings. The code will be publicly available.
Radar Signal Recognition through Self-Supervised Learning and Domain Adaptation
Jan 07, 2025



Automatic radar signal recognition (RSR) plays a pivotal role in electronic warfare (EW), as accurately classifying radar signals is critical for informing decision-making processes. Recent advances in deep learning have shown significant potential in improving RSR performance in domains with ample annotated data. However, these methods fall short in EW scenarios where annotated RF data are scarce or impractical to obtain. To address these challenges, we introduce a self-supervised learning (SSL) method which utilises masked signal modelling and RF domain adaption to enhance RSR performance in environments with limited RF samples and labels. Specifically, we investigate pre-training masked autoencoders (MAE) on baseband in-phase and quadrature (I/Q) signals from various RF domains and subsequently transfer the learned representation to the radar domain, where annotated data are limited. Empirical results show that our lightweight self-supervised ResNet model with domain adaptation achieves up to a 17.5\% improvement in 1-shot classification accuracy when pre-trained on in-domain signals (i.e., radar signals) and up to a 16.31\% improvement when pre-trained on out-of-domain signals (i.e., comm signals), compared to its baseline without SSL. We also provide reference results for several MAE designs and pre-training strategies, establishing a new benchmark for few-shot radar signal classification.
Online 6DoF Pose Estimation in Forests using Cross-View Factor Graph Optimisation and Deep Learned Re-localisation
Sep 25, 2024



This paper presents a novel approach for robust global localisation and 6DoF pose estimation of ground robots in forest environments by leveraging cross-view factor graph optimisation and deep-learned re-localisation. The proposed method addresses the challenges of aligning aerial and ground data for pose estimation, which is crucial for accurate point-to-point navigation in GPS-denied environments. By integrating information from both perspectives into a factor graph framework, our approach effectively estimates the robot's global position and orientation. We validate the performance of our method through extensive experiments in diverse forest scenarios, demonstrating its superiority over existing baselines in terms of accuracy and robustness in these challenging environments. Experimental results show that our proposed localisation system can achieve drift-free localisation with bounded positioning errors, ensuring reliable and safe robot navigation under canopies.
Part-based Quantitative Analysis for Heatmaps
May 22, 2024



Heatmaps have been instrumental in helping understand deep network decisions, and are a common approach for Explainable AI (XAI). While significant progress has been made in enhancing the informativeness and accessibility of heatmaps, heatmap analysis is typically very subjective and limited to domain experts. As such, developing automatic, scalable, and numerical analysis methods to make heatmap-based XAI more objective, end-user friendly, and cost-effective is vital. In addition, there is a need for comprehensive evaluation metrics to assess heatmap quality at a granular level.
Automatic Radar Signal Detection and FFT Estimation using Deep Learning
Feb 29, 2024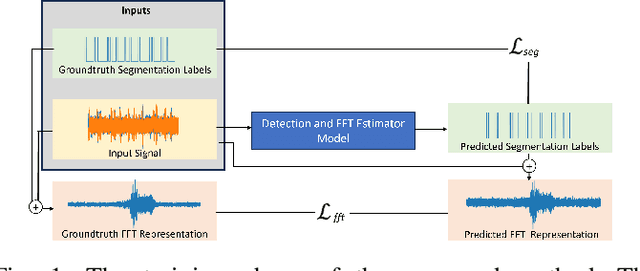

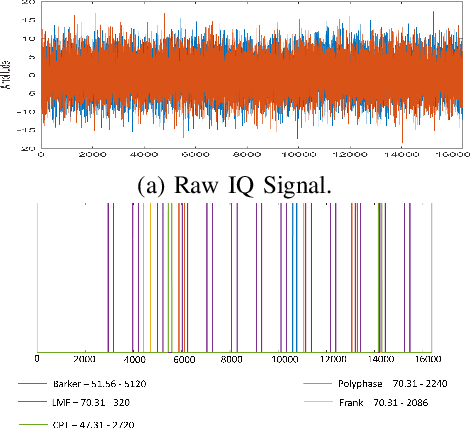
This paper addresses a critical preliminary step in radar signal processing: detecting the presence of a radar signal and robustly estimating its bandwidth. Existing methods which are largely statistical feature-based approaches face challenges in electronic warfare (EW) settings where prior information about signals is lacking. While alternate deep learning based methods focus on more challenging environments, they primarily formulate this as a binary classification problem. In this research, we propose a novel methodology that not only detects the presence of a signal, but also localises it in the time domain and estimates its operating frequency band at that point in time. To achieve robust estimation, we introduce a compound loss function that leverages complementary information from both time-domain and frequency-domain representations. By integrating these approaches, we aim to improve the efficiency and accuracy of radar signal detection and parameter estimation, reducing both unnecessary resource consumption and human effort in downstream tasks.
Deep Learning Approaches for Seizure Video Analysis: A Review
Dec 18, 2023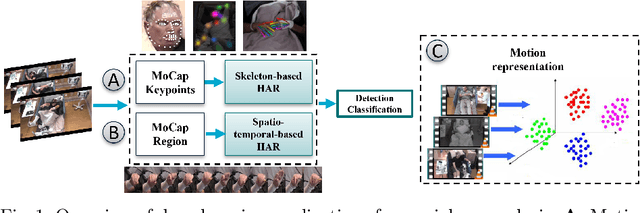
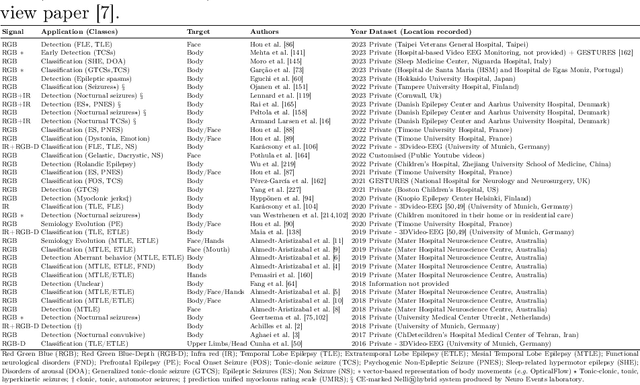

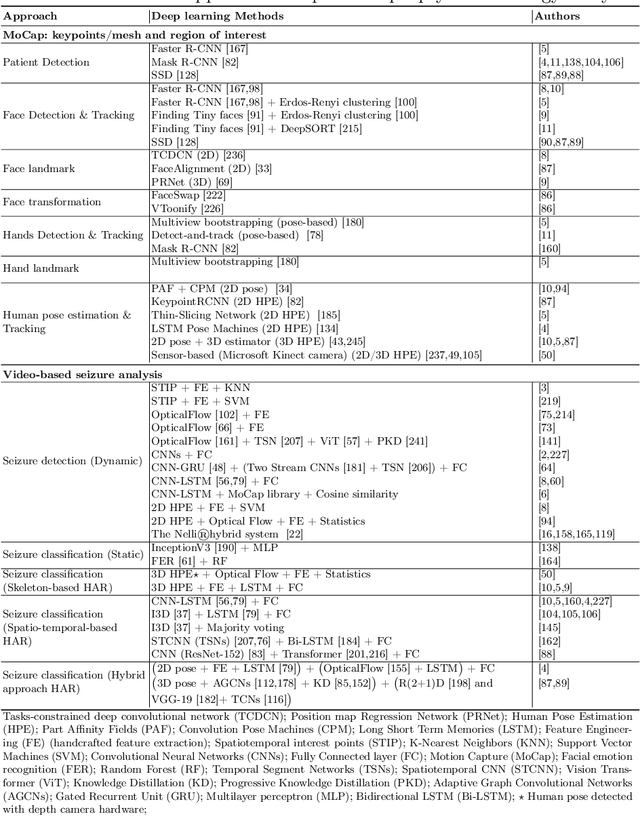
Seizure events may manifest as transient disruptions in movement and behavior, and the analysis of these clinical signs, referred to as semiology, is subject to observer variations when specialists evaluate video-recorded events in the clinical setting. To enhance the accuracy and consistency of evaluations, computer-aided video analysis of seizures has emerged as a natural avenue. In the field of medical applications, deep learning and computer vision approaches have driven substantial advancements. Historically, these approaches have been used for disease detection, classification, and prediction using diagnostic data; however, there has been limited exploration of their application in evaluating video-based motion detection in the clinical epileptology setting. While vision-based technologies do not aim to replace clinical expertise, they can significantly contribute to medical decision-making and patient care by providing quantitative evidence and decision support. Behavior monitoring tools offer several advantages such as providing objective information, detecting challenging-to-observe events, reducing documentation efforts, and extending assessment capabilities to areas with limited expertise. In this paper, we detail the foundation technologies used in vision-based systems in the analysis of seizure videos, highlighting their success in semiology detection and analysis, focusing on work published in the last 7 years. We systematically present these methods and indicate how the adoption of deep learning for the analysis of video recordings of seizures could be approached. Additionally, we illustrate how existing technologies can be interconnected through an integrated system for video-based semiology analysis. Finally, we discuss challenges and research directions for future studies.
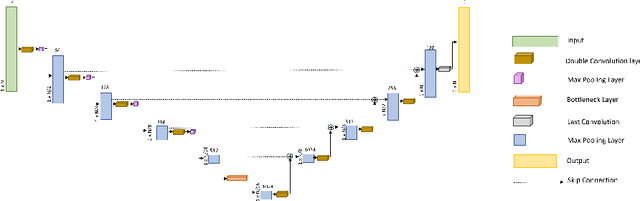
Multi-stage Learning for Radar Pulse Activity Segmentation
Dec 15, 2023



Radio signal recognition is a crucial function in electronic warfare. Precise identification and localisation of radar pulse activities are required by electronic warfare systems to produce effective countermeasures. Despite the importance of these tasks, deep learning-based radar pulse activity recognition methods have remained largely underexplored. While deep learning for radar modulation recognition has been explored previously, classification tasks are generally limited to short and non-interleaved IQ signals, limiting their applicability to military applications. To address this gap, we introduce an end-to-end multi-stage learning approach to detect and localise pulse activities of interleaved radar signals across an extended time horizon. We propose a simple, yet highly effective multi-stage architecture for incrementally predicting fine-grained segmentation masks that localise radar pulse activities across multiple channels. We demonstrate the performance of our approach against several reference models on a novel radar dataset, while also providing a first-of-its-kind benchmark for radar pulse activity segmentation.