 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Spatiotemporal Graphs: Leveraging the 3D Facial Surface for Remote Physiological Measurement
Jan 20, 2026Facial remote photoplethysmography (rPPG) methods estimate physiological signals by modeling subtle color changes on the 3D facial surface over time. However, existing methods fail to explicitly align their receptive fields with the 3D facial surface-the spatial support of the rPPG signal. To address this, we propose the Facial Spatiotemporal Graph (STGraph), a novel representation that encodes facial color and structure using 3D facial mesh sequences-enabling surface-aligned spatiotemporal processing. We introduce MeshPhys, a lightweight spatiotemporal graph convolutional network that operates on the STGraph to estimate physiological signals. Across four benchmark datasets, MeshPhys achieves state-of-the-art or competitive performance in both intra- and cross-dataset settings. Ablation studies show that constraining the model's receptive field to the facial surface acts as a strong structural prior, and that surface-aligned, 3D-aware node features are critical for robustly encoding facial surface color. Together, the STGraph and MeshPhys constitute a novel, principled modeling paradigm for facial rPPG, enabling robust, interpretable, and generalizable estimation. Code is available at https://samcantrill.github.io/facial-stgraph-rppg/ .
Quality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
Wound3DAssist: A Practical Framework for 3D Wound Assessment
Aug 25, 2025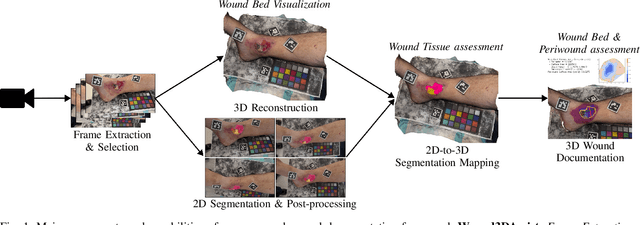
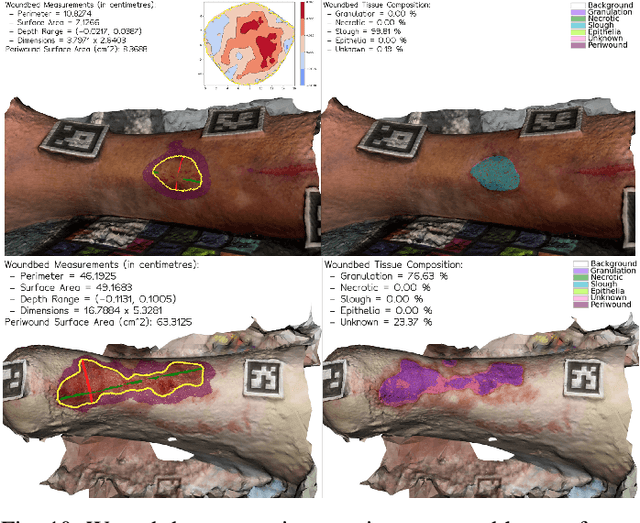
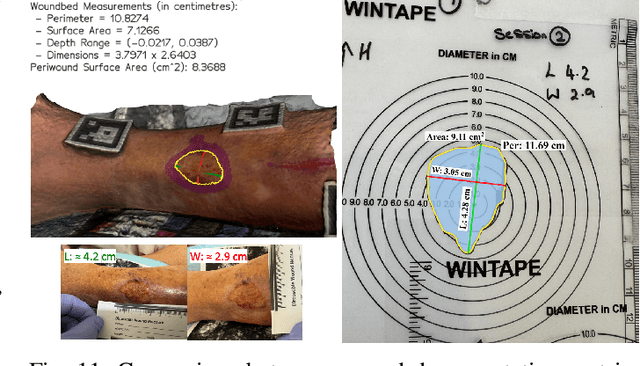
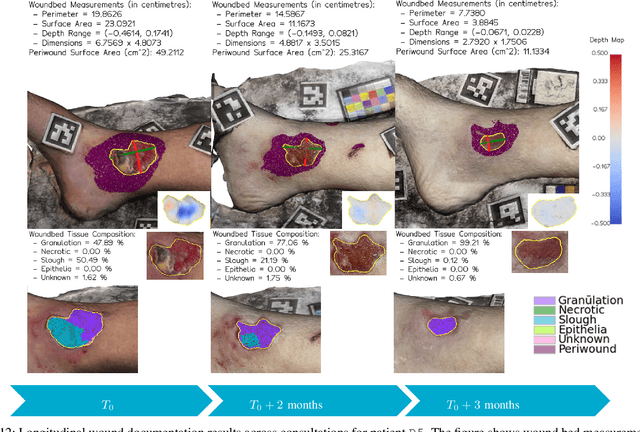
Managing chronic wounds remains a major healthcare challenge, with clinical assessment often relying on subjective and time-consuming manual documentation methods. Although 2D digital videometry frameworks aided the measurement process, these approaches struggle with perspective distortion, a limited field of view, and an inability to capture wound depth, especially in anatomically complex or curved regions. To overcome these limitations, we present Wound3DAssist, a practical framework for 3D wound assessment using monocular consumer-grade videos. Our framework generates accurate 3D models from short handheld smartphone video recordings, enabling non-contact, automatic measurements that are view-independent and robust to camera motion. We integrate 3D reconstruction, wound segmentation, tissue classification, and periwound analysis into a modular workflow. We evaluate Wound3DAssist across digital models with known geometry, silicone phantoms, and real patients. Results show that the framework supports high-quality wound bed visualization, millimeter-level accuracy, and reliable tissue composition analysis. Full assessments are completed in under 20 minutes, demonstrating feasibility for real-world clinical use.
Developing Normative Gait Cycle Parameters for Clinical Analysis Using Human Pose Estimation
Nov 20, 2024



Gait analysis using computer vision is an emerging field in AI, offering clinicians an objective, multi-feature approach to analyse complex movements. Despite its promise, current applications using RGB video data alone are limited in measuring clinically relevant spatial and temporal kinematics and establishing normative parameters essential for identifying movement abnormalities within a gait cycle. This paper presents a data-driven method using RGB video data and 2D human pose estimation for developing normative kinematic gait parameters. By analysing joint angles, an established kinematic measure in biomechanics and clinical practice, we aim to enhance gait analysis capabilities and improve explainability. Our cycle-wise kinematic analysis enables clinicians to simultaneously measure and compare multiple joint angles, assessing individuals against a normative population using just monocular RGB video. This approach expands clinical capacity, supports objective decision-making, and automates the identification of specific spatial and temporal deviations and abnormalities within the gait cycle.
Computer Vision for Clinical Gait Analysis: A Gait Abnormality Video Dataset
Jul 05, 2024



Clinical gait analysis (CGA) using computer vision is an emerging field in artificial intelligence that faces barriers of accessible, real-world data, and clear task objectives. This paper lays the foundation for current developments in CGA as well as vision-based methods and datasets suitable for gait analysis. We introduce The Gait Abnormality in Video Dataset (GAVD) in response to our review of over 150 current gait-related computer vision datasets, which highlighted the need for a large and accessible gait dataset clinically annotated for CGA. GAVD stands out as the largest video gait dataset, comprising 1874 sequences of normal, abnormal and pathological gaits. Additionally, GAVD includes clinically annotated RGB data sourced from publicly available content on online platforms. It also encompasses over 400 subjects who have undergone clinical grade visual screening to represent a diverse range of abnormal gait patterns, captured in various settings, including hospital clinics and urban uncontrolled outdoor environments. We demonstrate the validity of the dataset and utility of action recognition models for CGA using pretrained models Temporal Segment Networks(TSN) and SlowFast network to achieve video abnormality detection of 94% and 92% respectively when tested on GAVD dataset. A GitHub repository https://github.com/Rahmyyy/GAVD consisting of convenient URL links, and clinically relevant annotation for CGA is provided for over 450 online videos, featuring diverse subjects performing a range of normal, pathological, and abnormal gait patterns.
Orientation-conditioned Facial Texture Mapping for Video-based Facial Remote Photoplethysmography Estimation
Apr 16, 2024


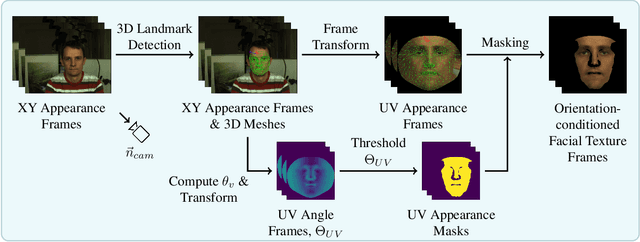
Camera-based remote photoplethysmography (rPPG) enables contactless measurement of important physiological signals such as pulse rate (PR). However, dynamic and unconstrained subject motion introduces significant variability into the facial appearance in video, confounding the ability of video-based methods to accurately extract the rPPG signal. In this study, we leverage the 3D facial surface to construct a novel orientation-conditioned facial texture video representation which improves the motion robustness of existing video-based facial rPPG estimation methods. Our proposed method achieves a significant 18.2% performance improvement in cross-dataset testing on MMPD over our baseline using the PhysNet model trained on PURE, highlighting the efficacy and generalization benefits of our designed video representation. We demonstrate significant performance improvements of up to 29.6% in all tested motion scenarios in cross-dataset testing on MMPD, even in the presence of dynamic and unconstrained subject motion, emphasizing the benefits of disentangling motion through modeling the 3D facial surface for motion robust facial rPPG estimation. We validate the efficacy of our design decisions and the impact of different video processing steps through an ablation study. Our findings illustrate the potential strengths of exploiting the 3D facial surface as a general strategy for addressing dynamic and unconstrained subject motion in videos. The code is available at https://samcantrill.github.io/orientation-uv-rppg/.
Deep Learning Approaches for Seizure Video Analysis: A Review
Dec 18, 2023
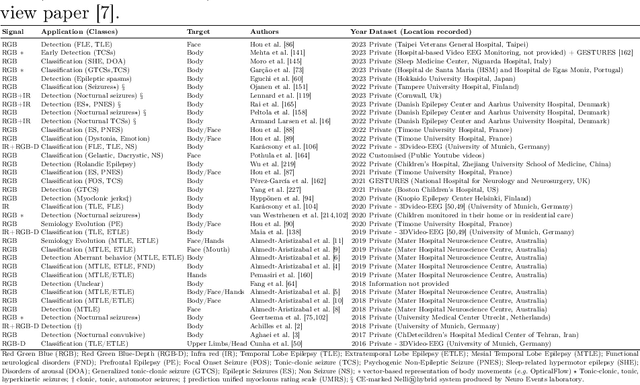

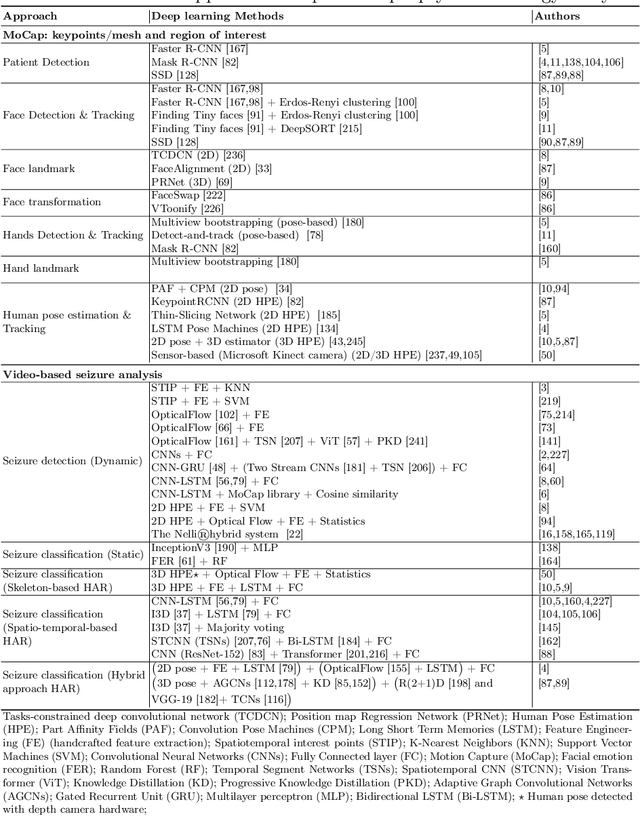
Seizure events may manifest as transient disruptions in movement and behavior, and the analysis of these clinical signs, referred to as semiology, is subject to observer variations when specialists evaluate video-recorded events in the clinical setting. To enhance the accuracy and consistency of evaluations, computer-aided video analysis of seizures has emerged as a natural avenue. In the field of medical applications, deep learning and computer vision approaches have driven substantial advancements. Historically, these approaches have been used for disease detection, classification, and prediction using diagnostic data; however, there has been limited exploration of their application in evaluating video-based motion detection in the clinical epileptology setting. While vision-based technologies do not aim to replace clinical expertise, they can significantly contribute to medical decision-making and patient care by providing quantitative evidence and decision support. Behavior monitoring tools offer several advantages such as providing objective information, detecting challenging-to-observe events, reducing documentation efforts, and extending assessment capabilities to areas with limited expertise. In this paper, we detail the foundation technologies used in vision-based systems in the analysis of seizure videos, highlighting their success in semiology detection and analysis, focusing on work published in the last 7 years. We systematically present these methods and indicate how the adoption of deep learning for the analysis of video recordings of seizures could be approached. Additionally, we illustrate how existing technologies can be interconnected through an integrated system for video-based semiology analysis. Finally, we discuss challenges and research directions for future studies.
Syn3DWound: A Synthetic Dataset for 3D Wound Bed Analysis
Nov 27, 2023


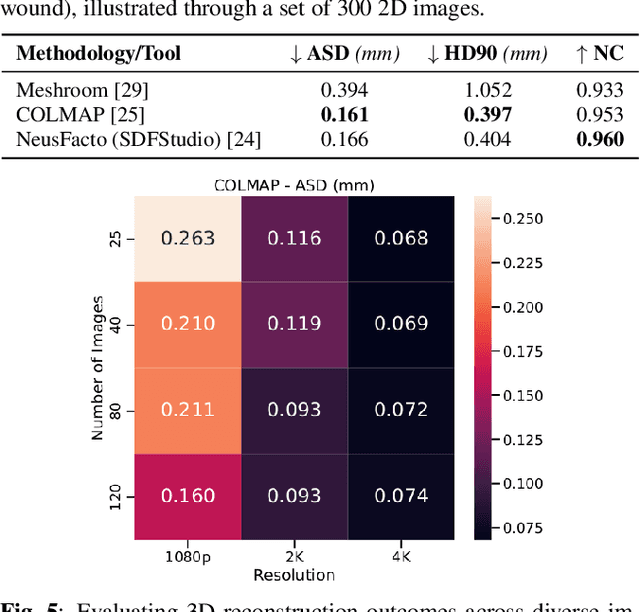
Wound management poses a significant challenge, particularly for bedridden patients and the elderly. Accurate diagnostic and healing monitoring can significantly benefit from modern image analysis, providing accurate and precise measurements of wounds. Despite several existing techniques, the shortage of expansive and diverse training datasets remains a significant obstacle to constructing machine learning-based frameworks. This paper introduces Syn3DWound, an open-source dataset of high-fidelity simulated wounds with 2D and 3D annotations. We propose baseline methods and a benchmarking framework for automated 3D morphometry analysis and 2D/3D wound segmentation.
A Hyperspectral and RGB Dataset for Building Facade Segmentation
Dec 06, 2022
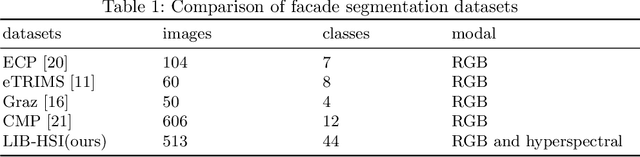
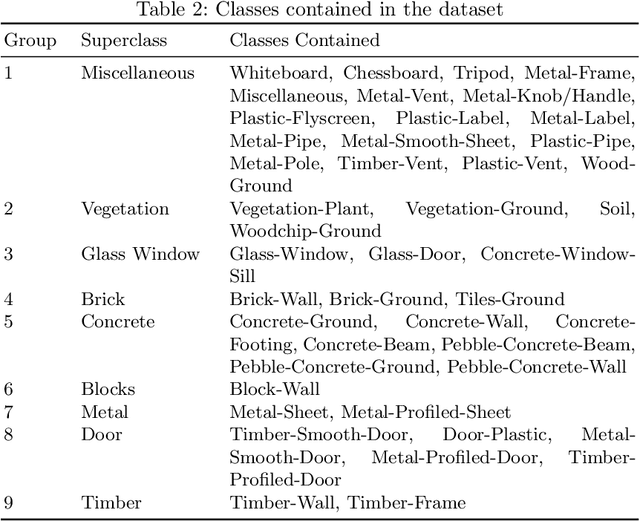

Hyperspectral Imaging (HSI) provides detailed spectral information and has been utilised in many real-world applications. This work introduces an HSI dataset of building facades in a light industry environment with the aim of classifying different building materials in a scene. The dataset is called the Light Industrial Building HSI (LIB-HSI) dataset. This dataset consists of nine categories and 44 classes. In this study, we investigated deep learning based semantic segmentation algorithms on RGB and hyperspectral images to classify various building materials, such as timber, brick and concrete.
Automated Coronary Arteries Labeling Via Geometric Deep Learning
Dec 01, 2022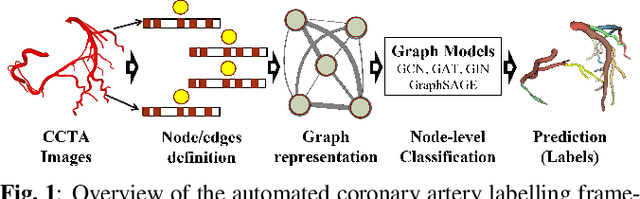

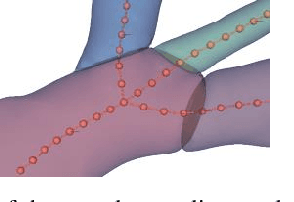

Automatic labelling of anatomical structures, such as coronary arteries, is critical for diagnosis, yet existing (non-deep learning) methods are limited by a reliance on prior topological knowledge of the expected tree-like structures. As the structure such vascular systems is often difficult to conceptualize, graph-based representations have become popular due to their ability to capture the geometric and topological properties of the morphology in an orientation-independent and abstract manner. However, graph-based learning for automated labeling of tree-like anatomical structures has received limited attention in the literature. The majority of prior studies have limitations in the entity graph construction, are dependent on topological structures, and have limited accuracy due to the anatomical variability between subjects. In this paper, we propose an intuitive graph representation method, well suited to use with 3D coordinate data obtained from angiography scans. We subsequently seek to analyze subject-specific graphs using geometric deep learning. The proposed models leverage expert annotated labels from 141 patients to learn representations of each coronary segment, while capturing the effects of anatomical variability within the training data. We investigate different variants of so-called message passing neural networks. Through extensive evaluations, our pipeline achieves a promising weighted F1-score of 0.805 for labeling coronary artery (13 classes) for a five-fold cross-validation. Considering the ability of graph models in dealing with irregular data, and their scalability for data segmentation, this work highlights the potential of such methods to provide quantitative evidence to support the decisions of medical experts.