 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Bed Human Pose Estimation from Unseen and Privacy-Preserving Image Domains
Paper and Code
Nov 30, 2021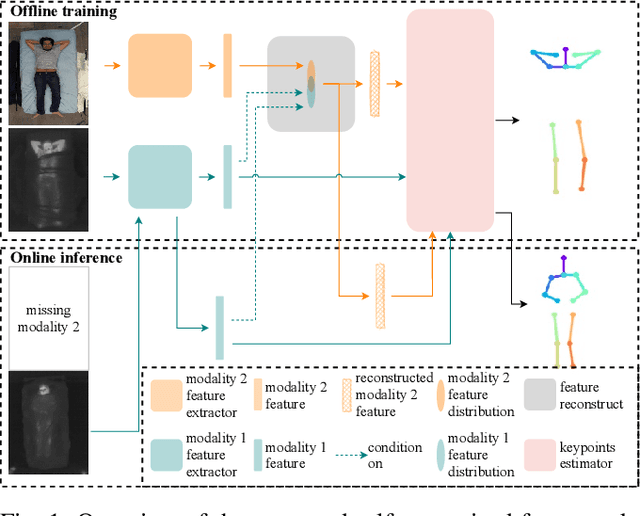
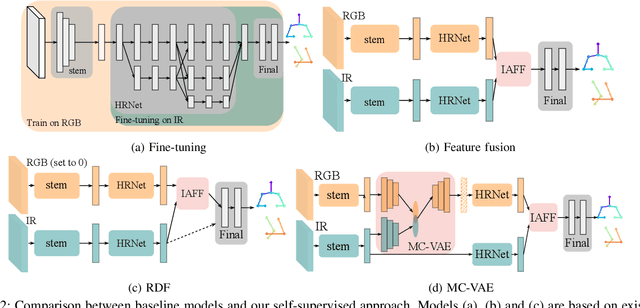
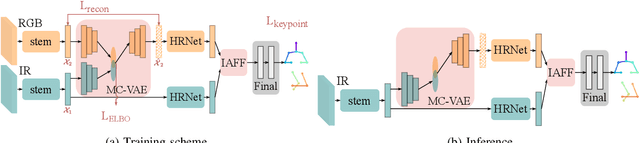

Medical applications have benefited from the rapid advancement in computer vision. For patient monitoring in particular, in-bed human posture estimation provides important health-related metrics with potential value in medical condition assessments. Despite great progress in this domain, it remains a challenging task due to substantial ambiguity during occlusions, and the lack of large corpora of manually labeled data for model training, particularly with domains such as thermal infrared imaging which are privacy-preserving, and thus of great interest. Motivated by the effectiveness of self-supervised methods in learning features directly from data, we propose a multi-modal conditional variational autoencoder (MC-VAE) capable of reconstructing features from missing modalities seen during training. This approach is used with HRNet to enable single modality inference for in-bed pose estimation. Through extensive evaluations, we demonstrate that body positions can be effectively recognized from the available modality, achieving on par results with baseline models that are highly dependent on having access to multiple modes at inference time. The proposed framework supports future research towards self-supervised learning that generates a robust model from a single source, and expects it to generalize over many unknown distributions in clinical environments.