 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Residual Plot Assessment With the R Package autovi and the Shiny Application autovi.web
Jun 23, 2026Visual assessment of residual plots is a common approach for diagnosing linear models, but it relies on manual evaluation, which does not scale well and can lead to inconsistent decisions across analysts. The lineup protocol, which embeds the observed plot among null plots, can reduce subjectivity but requires even more human effort. In today's data-driven world, such tasks are well suited for automation. We present a new R package that uses a computer vision model to automate the evaluation of residual plots. An accompanying Shiny application is provided for ease of use. Given a sample of residuals, the model predicts a visual signal strength (VSS) and offers supporting information to help analysts assess model fit.
* Published in Australian & New Zealand Journal of Statistics
Can Post-Training Turn LLMs into Good Medical Coders? An Empirical Study of Generative ICD Coding
Jun 11, 2026Automated International Classification of Diseases (ICD) coding is a core medical-coding task for billing, epidemiology, and clinical decision support. Generative large language models (LLMs) are often reported as weak medical coders, but this finding mainly comes from inference-time settings such as prompting, retrieval, reranking, or tool use, leaving the role of task-specific post-training underexplored. We present a controlled empirical study of post-training for generative ICD coding, comparing discriminative baselines with LLM coders across prompting, supervised fine-tuning, and reinforcement learning under a common protocol and metric set. To our knowledge, this is the first study to evaluate RL-based post-training for generative LLM coders in ICD coding. We further introduce PHI, a diagnostic curriculum that extends GRPO to refine missed-code cases. Our results show that prompting-only evaluation substantially underestimates the potential of LLMs for ICD coding. SFT provides the main capability jump, GRPO further improves code-set prediction beyond SFT, and PHI provides targeted gains on macro-level performance. These findings suggest that the main bottleneck is not the generative formulation alone, but how the model is adapted and optimized for full-taxonomy recall. We release our code, data splits, and checkpoints at https://github.com/AlexandreWANG915/LLM4ICD.
AusSmoke meets MultiNatSmoke: a fully-labelled diverse smoke segmentation dataset
Apr 26, 2026Wildfires are an escalating global concern due to the devastating impacts on the environment, economy, and human health, with notable incidents such as the 2019-2020 Australian bushfires and the 2025 California wildfires underscoring the severity of these events. AI-enabled camera-based smoke detection has emerged as a promising approach for the rapid detection of wildfires. However, existing wildfire smoke segmentation datasets that are used for training detection and segmentation models are limited in scale, geographically constrained, and often rely on synthetic imagery, which hinders effective training and generalization. To overcome these limitations, we present AusSmoke, a new smoke segmentation dataset collected from Australia to address the data scarcity in this region. Furthermore, we introduce a MultiNational geographically diverse and substantially larger fully-labelled benchmark, called MultiNatSmoke, that consolidates publicly available international datasets with the newly collected Australian imagery, expanding the scale by an order of magnitude over previous collections. Finally, we benchmark smoke segmentation models, demonstrating improved performance and enhanced generalization across diverse geographical contexts. The project is available at \href{https://github.com/henryzhao0615/MultiNatSmoke}{Github}.
TCRL: Temporal-Coupled Adversarial Training for Robust Constrained Reinforcement Learning in Worst-Case Scenarios
Feb 13, 2026Constrained Reinforcement Learning (CRL) aims to optimize decision-making policies under constraint conditions, making it highly applicable to safety-critical domains such as autonomous driving, robotics, and power grid management. However, existing robust CRL approaches predominantly focus on single-step perturbations and temporally independent adversarial models, lacking explicit modeling of robustness against temporally coupled perturbations. To tackle these challenges, we propose TCRL, a novel temporal-coupled adversarial training framework for robust constrained reinforcement learning (TCRL) in worst-case scenarios. First, TCRL introduces a worst-case-perceived cost constraint function that estimates safety costs under temporally coupled perturbations without the need to explicitly model adversarial attackers. Second, TCRL establishes a dual-constraint defense mechanism on the reward to counter temporally coupled adversaries while maintaining reward unpredictability. Experimental results demonstrate that TCRL consistently outperforms existing methods in terms of robustness against temporally coupled perturbation attacks across a variety of CRL tasks.
SmokeBench: Evaluating Multimodal Large Language Models for Wildfire Smoke Detection
Dec 12, 2025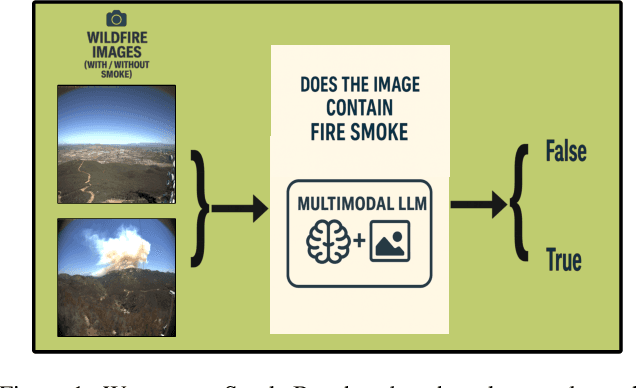
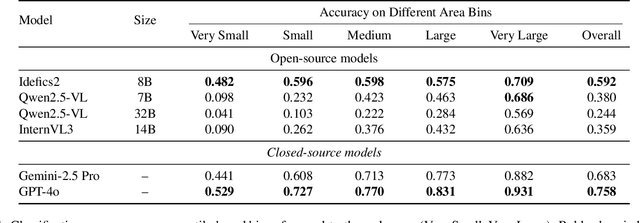

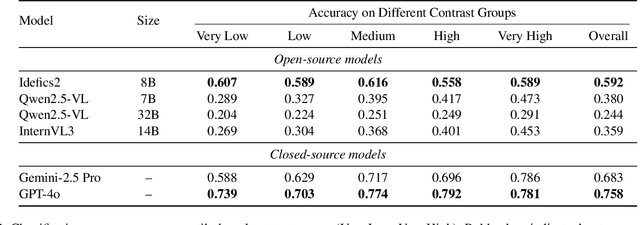
Wildfire smoke is transparent, amorphous, and often visually confounded with clouds, making early-stage detection particularly challenging. In this work, we introduce a benchmark, called SmokeBench, to evaluate the ability of multimodal large language models (MLLMs) to recognize and localize wildfire smoke in images. The benchmark consists of four tasks: (1) smoke classification, (2) tile-based smoke localization, (3) grid-based smoke localization, and (4) smoke detection. We evaluate several MLLMs, including Idefics2, Qwen2.5-VL, InternVL3, Unified-IO 2, Grounding DINO, GPT-4o, and Gemini-2.5 Pro. Our results show that while some models can classify the presence of smoke when it covers a large area, all models struggle with accurate localization, especially in the early stages. Further analysis reveals that smoke volume is strongly correlated with model performance, whereas contrast plays a comparatively minor role. These findings highlight critical limitations of current MLLMs for safety-critical wildfire monitoring and underscore the need for methods that improve early-stage smoke localization.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
NoiseSDF2NoiseSDF: Learning Clean Neural Fields from Noisy Supervision
Jul 18, 2025Reconstructing accurate implicit surface representations from point clouds remains a challenging task, particularly when data is captured using low-quality scanning devices. These point clouds often contain substantial noise, leading to inaccurate surface reconstructions. Inspired by the Noise2Noise paradigm for 2D images, we introduce NoiseSDF2NoiseSDF, a novel method designed to extend this concept to 3D neural fields. Our approach enables learning clean neural SDFs directly from noisy point clouds through noisy supervision by minimizing the MSE loss between noisy SDF representations, allowing the network to implicitly denoise and refine surface estimations. We evaluate the effectiveness of NoiseSDF2NoiseSDF on benchmarks, including the ShapeNet, ABC, Famous, and Real datasets. Experimental results demonstrate that our framework significantly improves surface reconstruction quality from noisy inputs.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025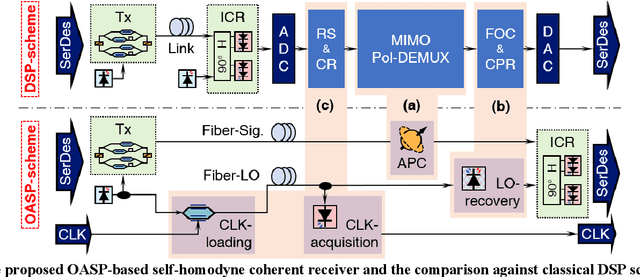
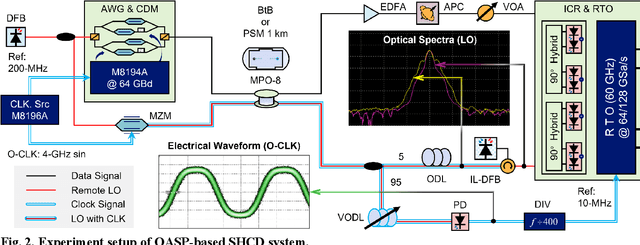
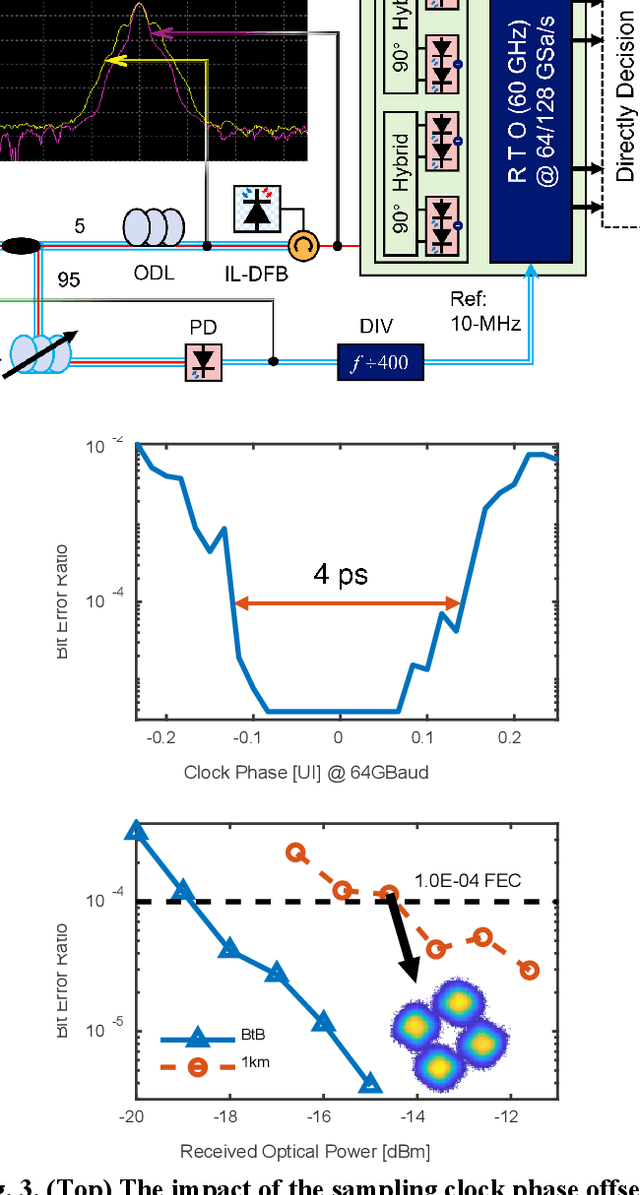
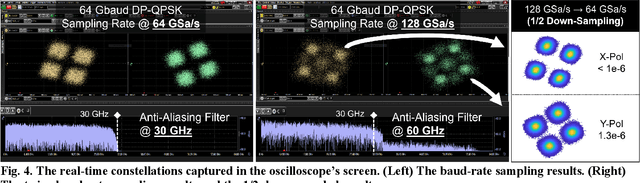
To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.
Knowing Where to Focus: Attention-Guided Alignment for Text-based Person Search
Dec 19, 2024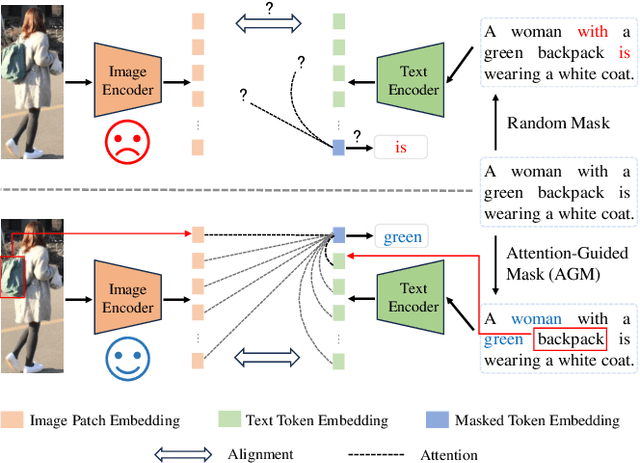
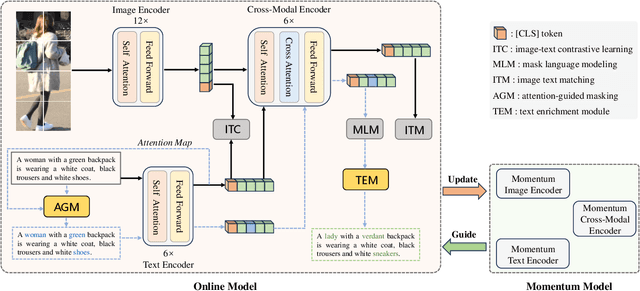


In the realm of Text-Based Person Search (TBPS), mainstream methods aim to explore more efficient interaction frameworks between text descriptions and visual data. However, recent approaches encounter two principal challenges. Firstly, the widely used random-based Masked Language Modeling (MLM) considers all the words in the text equally during training. However, massive semantically vacuous words ('with', 'the', etc.) be masked fail to contribute efficient interaction in the cross-modal MLM and hampers the representation alignment. Secondly, manual descriptions in TBPS datasets are tedious and inevitably contain several inaccuracies. To address these issues, we introduce an Attention-Guided Alignment (AGA) framework featuring two innovative components: Attention-Guided Mask (AGM) Modeling and Text Enrichment Module (TEM). AGM dynamically masks semantically meaningful words by aggregating the attention weight derived from the text encoding process, thereby cross-modal MLM can capture information related to the masked word from text context and images and align their representations. Meanwhile, TEM alleviates low-quality representations caused by repetitive and erroneous text descriptions by replacing those semantically meaningful words with MLM's prediction. It not only enriches text descriptions but also prevents overfitting. Extensive experiments across three challenging benchmarks demonstrate the effectiveness of our AGA, achieving new state-of-the-art results with Rank-1 accuracy reaching 78.36%, 67.31%, and 67.4% on CUHK-PEDES, ICFG-PEDES, and RSTPReid, respectively.
Automated Assessment of Residual Plots with Computer Vision Models
Nov 01, 2024



Plotting the residuals is a recommended procedure to diagnose deviations from linear model assumptions, such as non-linearity, heteroscedasticity, and non-normality. The presence of structure in residual plots can be tested using the lineup protocol to do visual inference. There are a variety of conventional residual tests, but the lineup protocol, used as a statistical test, performs better for diagnostic purposes because it is less sensitive and applies more broadly to different types of departures. However, the lineup protocol relies on human judgment which limits its scalability. This work presents a solution by providing a computer vision model to automate the assessment of residual plots. It is trained to predict a distance measure that quantifies the disparity between the residual distribution of a fitted classical normal linear regression model and the reference distribution, based on Kullback-Leibler divergence. From extensive simulation studies, the computer vision model exhibits lower sensitivity than conventional tests but higher sensitivity than human visual tests. It is slightly less effective on non-linearity patterns. Several examples from classical papers and contemporary data illustrate the new procedures, highlighting its usefulness in automating the diagnostic process and supplementing existing methods.