 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDI-Paste: Synthetic Dynamic Instance Copy-Paste for Video Instance Segmentation
Oct 16, 2024



Data augmentation methods such as Copy-Paste have been studied as effective ways to expand training datasets while incurring minimal costs. While such methods have been extensively implemented for image level tasks, we found no scalable implementation of Copy-Paste built specifically for video tasks. In this paper, we leverage the recent growth in video fidelity of generative models to explore effective ways of incorporating synthetically generated objects into existing video datasets to artificially expand object instance pools. We first procure synthetic video sequences featuring objects that morph dynamically with time. Our carefully devised pipeline automatically segments then copy-pastes these dynamic instances across the frames of any target background video sequence. We name our video data augmentation pipeline Synthetic Dynamic Instance Copy-Paste, and test it on the complex task of Video Instance Segmentation which combines detection, segmentation and tracking of object instances across a video sequence. Extensive experiments on the popular Youtube-VIS 2021 dataset using two separate popular networks as baselines achieve strong gains of +2.9 AP (6.5%) and +2.1 AP (4.9%). We make our code and models publicly available.
Multiview Scene Graph
Oct 15, 2024



A proper scene representation is central to the pursuit of spatial intelligence where agents can robustly reconstruct and efficiently understand 3D scenes. A scene representation is either metric, such as landmark maps in 3D reconstruction, 3D bounding boxes in object detection, or voxel grids in occupancy prediction, or topological, such as pose graphs with loop closures in SLAM or visibility graphs in SfM. In this work, we propose to build Multiview Scene Graphs (MSG) from unposed images, representing a scene topologically with interconnected place and object nodes. The task of building MSG is challenging for existing representation learning methods since it needs to jointly address both visual place recognition, object detection, and object association from images with limited fields of view and potentially large viewpoint changes. To evaluate any method tackling this task, we developed an MSG dataset and annotation based on a public 3D dataset. We also propose an evaluation metric based on the intersection-over-union score of MSG edges. Moreover, we develop a novel baseline method built on mainstream pretrained vision models, combining visual place recognition and object association into one Transformer decoder architecture. Experiments demonstrate our method has superior performance compared to existing relevant baselines.
Visual Geo-localization with Self-supervised Representation Learning
Jul 31, 2023



Visual Geo-localization (VG) has emerged as a significant research area, aiming to identify geolocation based on visual features. Most VG approaches use learnable feature extractors for representation learning. Recently, Self-Supervised Learning (SSL) methods have also demonstrated comparable performance to supervised methods by using numerous unlabeled images for representation learning. In this work, we present a novel unified VG-SSL framework with the goal to enhance performance and training efficiency on a large VG dataset by SSL methods. Our work incorporates multiple SSL methods tailored for VG: SimCLR, MoCov2, BYOL, SimSiam, Barlow Twins, and VICReg. We systematically analyze the performance of different training strategies and study the optimal parameter settings for the adaptation of SSL methods for the VG task. The results demonstrate that our method, without the significant computation and memory usage associated with Hard Negative Mining (HNM), can match or even surpass the VG performance of the baseline that employs HNM. The code is available at https://github.com/arplaboratory/VG_SSL.
Beyond Local Search: Tracking Objects Everywhere with Instance-Specific Proposals
May 06, 2016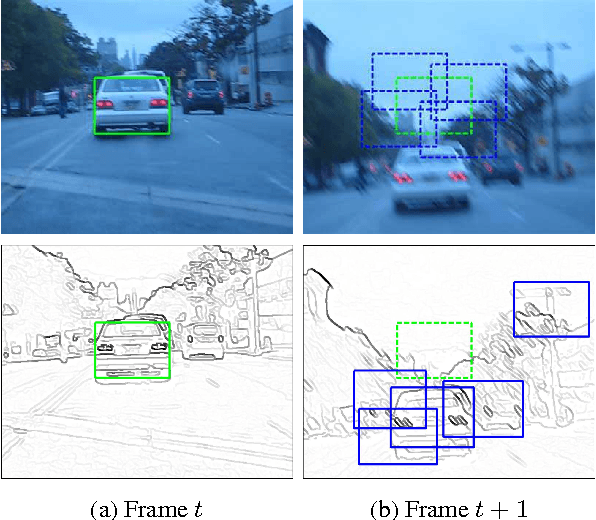
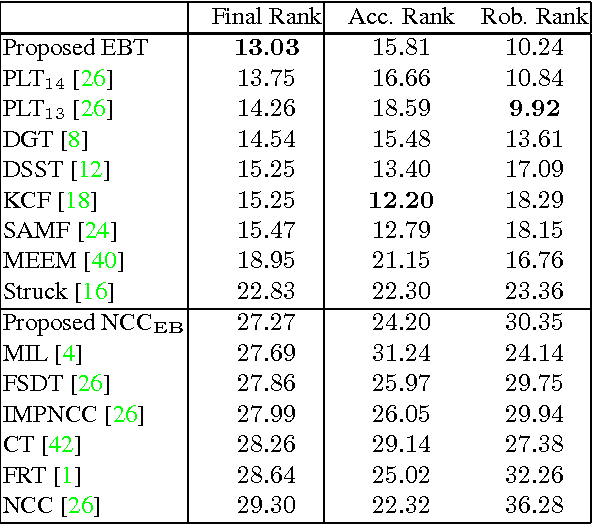
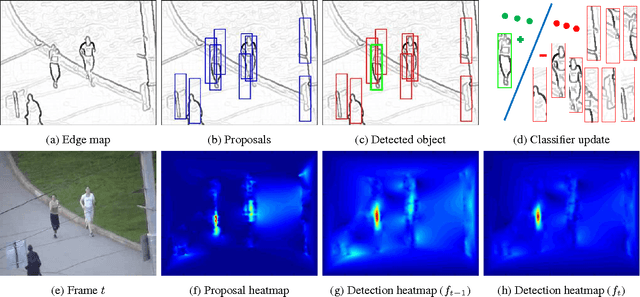

Most tracking-by-detection methods employ a local search window around the predicted object location in the current frame assuming the previous location is accurate, the trajectory is smooth, and the computational capacity permits a search radius that can accommodate the maximum speed yet small enough to reduce mismatches. These, however, may not be valid always, in particular for fast and irregularly moving objects. Here, we present an object tracker that is not limited to a local search window and has ability to probe efficiently the entire frame. Our method generates a small number of "high-quality" proposals by a novel instance-specific objectness measure and evaluates them against the object model that can be adopted from an existing tracking-by-detection approach as a core tracker. During the tracking process, we update the object model concentrating on hard false-positives supplied by the proposals, which help suppressing distractors caused by difficult background clutters, and learn how to re-rank proposals according to the object model. Since we reduce significantly the number of hypotheses the core tracker evaluates, we can use richer object descriptors and stronger detector. Our method outperforms most recent state-of-the-art trackers on popular tracking benchmarks, and provides improved robustness for fast moving objects as well as for ultra low-frame-rate videos.
Tracking Randomly Moving Objects on Edge Box Proposals
Nov 29, 2015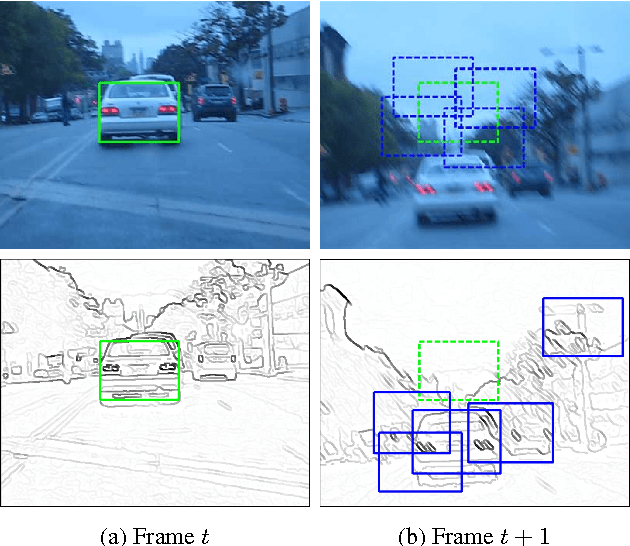
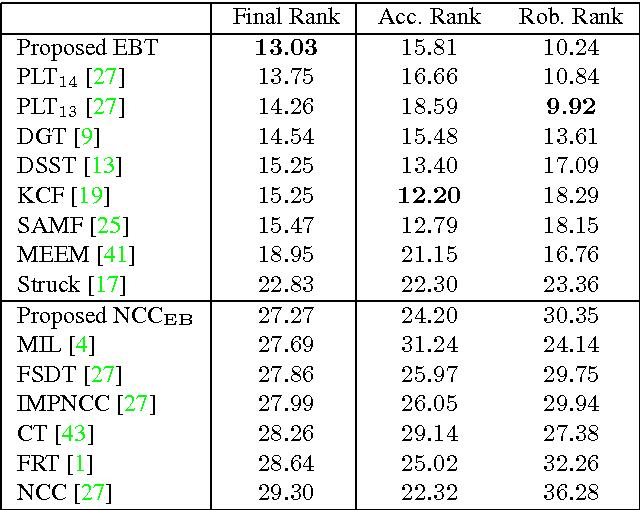
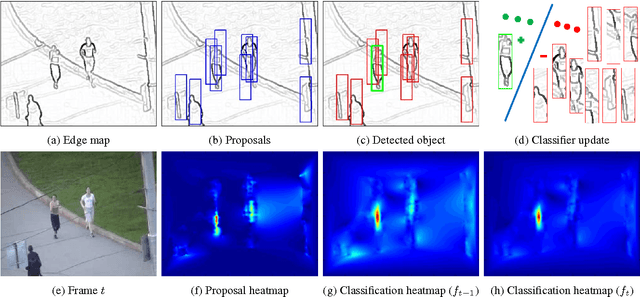
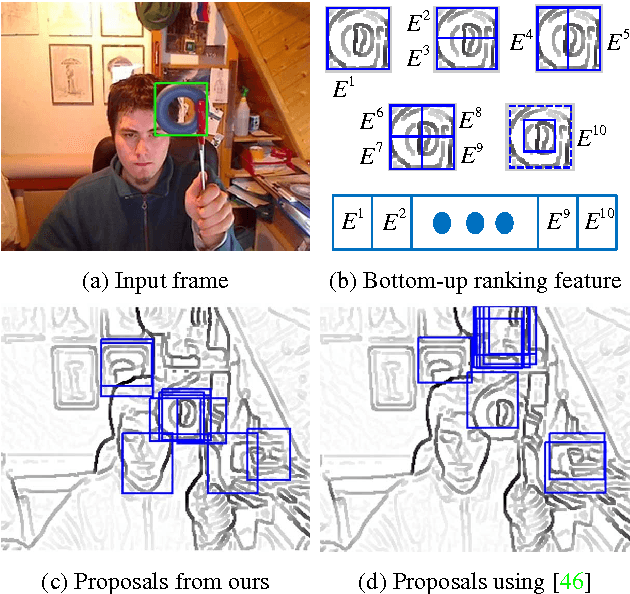
Most tracking-by-detection methods employ a local search window around the predicted object location in the current frame assuming the previous location is accurate, the trajectory is smooth, and the computational capacity permits a search radius that can accommodate the maximum speed yet small enough to reduce mismatches. These, however, may not be valid always, in particular for fast and irregularly moving objects. Here, we present an object tracker that is not limited to a local search window and has ability to probe efficiently the entire frame. Our method generates a small number of "high-quality" proposals by a novel instance-specific objectness measure and evaluates them against the object model that can be adopted from an existing tracking-by-detection approach as a core tracker. During the tracking process, we update the object model concentrating on hard false-positives supplied by the proposals, which help suppressing distractors caused by difficult background clutters, and learn how to re-rank proposals according to the object model. Since we reduce significantly the number of hypotheses the core tracker evaluates, we can use richer object descriptors and stronger detector. Our method outperforms most recent state-of-the-art trackers on popular tracking benchmarks, and provides improved robustness for fast moving objects as well as for ultra low-frame-rate videos.