 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDI-Paste: Synthetic Dynamic Instance Copy-Paste for Video Instance Segmentation
Oct 16, 2024



Data augmentation methods such as Copy-Paste have been studied as effective ways to expand training datasets while incurring minimal costs. While such methods have been extensively implemented for image level tasks, we found no scalable implementation of Copy-Paste built specifically for video tasks. In this paper, we leverage the recent growth in video fidelity of generative models to explore effective ways of incorporating synthetically generated objects into existing video datasets to artificially expand object instance pools. We first procure synthetic video sequences featuring objects that morph dynamically with time. Our carefully devised pipeline automatically segments then copy-pastes these dynamic instances across the frames of any target background video sequence. We name our video data augmentation pipeline Synthetic Dynamic Instance Copy-Paste, and test it on the complex task of Video Instance Segmentation which combines detection, segmentation and tracking of object instances across a video sequence. Extensive experiments on the popular Youtube-VIS 2021 dataset using two separate popular networks as baselines achieve strong gains of +2.9 AP (6.5%) and +2.1 AP (4.9%). We make our code and models publicly available.
Learning To Segment Dominant Object Motion From Watching Videos
Nov 28, 2021
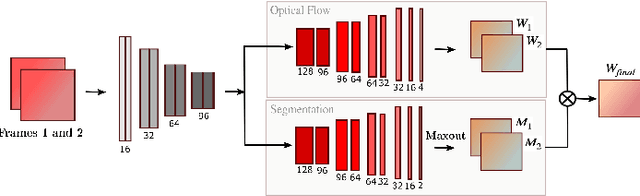

Existing deep learning based unsupervised video object segmentation methods still rely on ground-truth segmentation masks to train. Unsupervised in this context only means that no annotated frames are used during inference. As obtaining ground-truth segmentation masks for real image scenes is a laborious task, we envision a simple framework for dominant moving object segmentation that neither requires annotated data to train nor relies on saliency priors or pre-trained optical flow maps. Inspired by a layered image representation, we introduce a technique to group pixel regions according to their affine parametric motion. This enables our network to learn segmentation of the dominant foreground object using only RGB image pairs as input for both training and inference. We establish a baseline for this novel task using a new MovingCars dataset and show competitive performance against recent methods that require annotated masks to train.