 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Segment Dominant Object Motion From Watching Videos
Paper and Code

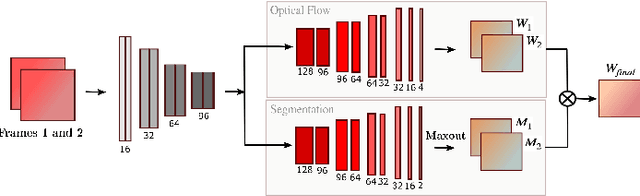

Existing deep learning based unsupervised video object segmentation methods still rely on ground-truth segmentation masks to train. Unsupervised in this context only means that no annotated frames are used during inference. As obtaining ground-truth segmentation masks for real image scenes is a laborious task, we envision a simple framework for dominant moving object segmentation that neither requires annotated data to train nor relies on saliency priors or pre-trained optical flow maps. Inspired by a layered image representation, we introduce a technique to group pixel regions according to their affine parametric motion. This enables our network to learn segmentation of the dominant foreground object using only RGB image pairs as input for both training and inference. We establish a baseline for this novel task using a new MovingCars dataset and show competitive performance against recent methods that require annotated masks to train.