 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAusSmoke meets MultiNatSmoke: a fully-labelled diverse smoke segmentation dataset
Apr 26, 2026Wildfires are an escalating global concern due to the devastating impacts on the environment, economy, and human health, with notable incidents such as the 2019-2020 Australian bushfires and the 2025 California wildfires underscoring the severity of these events. AI-enabled camera-based smoke detection has emerged as a promising approach for the rapid detection of wildfires. However, existing wildfire smoke segmentation datasets that are used for training detection and segmentation models are limited in scale, geographically constrained, and often rely on synthetic imagery, which hinders effective training and generalization. To overcome these limitations, we present AusSmoke, a new smoke segmentation dataset collected from Australia to address the data scarcity in this region. Furthermore, we introduce a MultiNational geographically diverse and substantially larger fully-labelled benchmark, called MultiNatSmoke, that consolidates publicly available international datasets with the newly collected Australian imagery, expanding the scale by an order of magnitude over previous collections. Finally, we benchmark smoke segmentation models, demonstrating improved performance and enhanced generalization across diverse geographical contexts. The project is available at \href{https://github.com/henryzhao0615/MultiNatSmoke}{Github}.
SmokeBench: Evaluating Multimodal Large Language Models for Wildfire Smoke Detection
Dec 12, 2025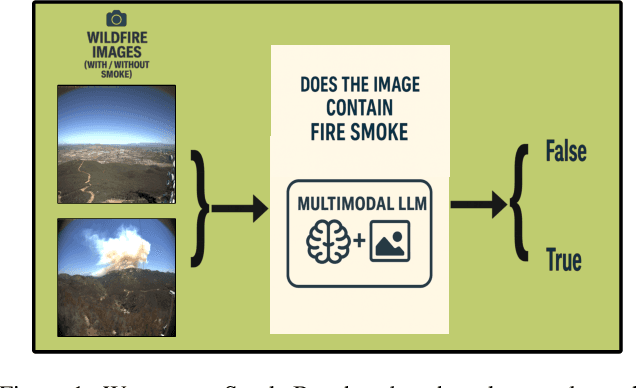
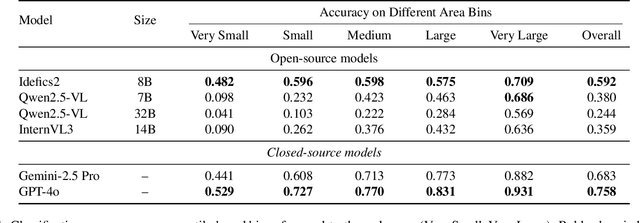

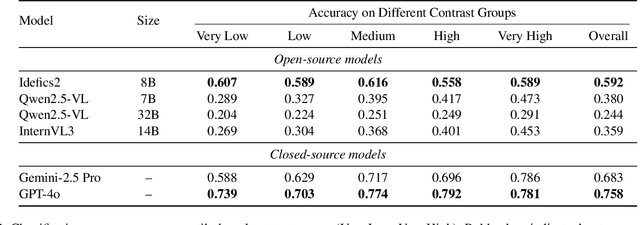
Wildfire smoke is transparent, amorphous, and often visually confounded with clouds, making early-stage detection particularly challenging. In this work, we introduce a benchmark, called SmokeBench, to evaluate the ability of multimodal large language models (MLLMs) to recognize and localize wildfire smoke in images. The benchmark consists of four tasks: (1) smoke classification, (2) tile-based smoke localization, (3) grid-based smoke localization, and (4) smoke detection. We evaluate several MLLMs, including Idefics2, Qwen2.5-VL, InternVL3, Unified-IO 2, Grounding DINO, GPT-4o, and Gemini-2.5 Pro. Our results show that while some models can classify the presence of smoke when it covers a large area, all models struggle with accurate localization, especially in the early stages. Further analysis reveals that smoke volume is strongly correlated with model performance, whereas contrast plays a comparatively minor role. These findings highlight critical limitations of current MLLMs for safety-critical wildfire monitoring and underscore the need for methods that improve early-stage smoke localization.
FreeVPS: Repurposing Training-Free SAM2 for Generalizable Video Polyp Segmentation
Aug 27, 2025Existing video polyp segmentation (VPS) paradigms usually struggle to balance between spatiotemporal modeling and domain generalization, limiting their applicability in real clinical scenarios. To embrace this challenge, we recast the VPS task as a track-by-detect paradigm that leverages the spatial contexts captured by the image polyp segmentation (IPS) model while integrating the temporal modeling capabilities of segment anything model 2 (SAM2). However, during long-term polyp tracking in colonoscopy videos, SAM2 suffers from error accumulation, resulting in a snowball effect that compromises segmentation stability. We mitigate this issue by repurposing SAM2 as a video polyp segmenter with two training-free modules. In particular, the intra-association filtering module eliminates spatial inaccuracies originating from the detecting stage, reducing false positives. The inter-association refinement module adaptively updates the memory bank to prevent error propagation over time, enhancing temporal coherence. Both modules work synergistically to stabilize SAM2, achieving cutting-edge performance in both in-domain and out-of-domain scenarios. Furthermore, we demonstrate the robust tracking capabilities of FreeVPS in long-untrimmed colonoscopy videos, underscoring its potential reliable clinical analysis.
NoiseSDF2NoiseSDF: Learning Clean Neural Fields from Noisy Supervision
Jul 18, 2025Reconstructing accurate implicit surface representations from point clouds remains a challenging task, particularly when data is captured using low-quality scanning devices. These point clouds often contain substantial noise, leading to inaccurate surface reconstructions. Inspired by the Noise2Noise paradigm for 2D images, we introduce NoiseSDF2NoiseSDF, a novel method designed to extend this concept to 3D neural fields. Our approach enables learning clean neural SDFs directly from noisy point clouds through noisy supervision by minimizing the MSE loss between noisy SDF representations, allowing the network to implicitly denoise and refine surface estimations. We evaluate the effectiveness of NoiseSDF2NoiseSDF on benchmarks, including the ShapeNet, ABC, Famous, and Real datasets. Experimental results demonstrate that our framework significantly improves surface reconstruction quality from noisy inputs.
Open Set Label Shift with Test Time Out-of-Distribution Reference
May 09, 2025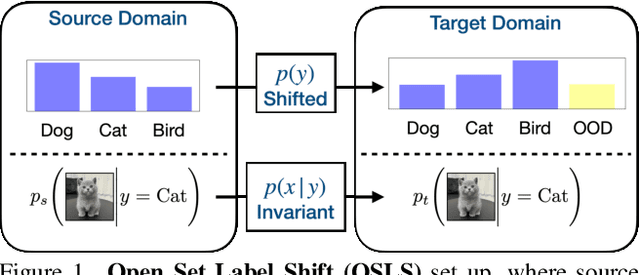
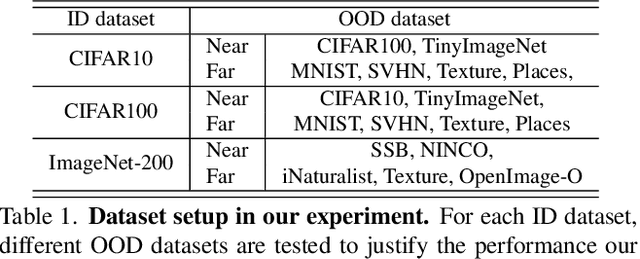
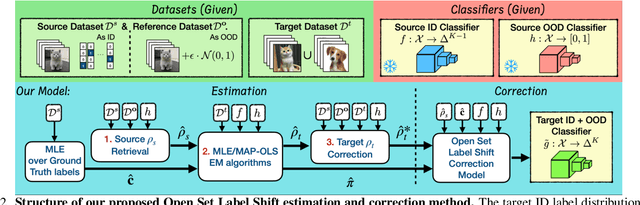

Open set label shift (OSLS) occurs when label distributions change from a source to a target distribution, and the target distribution has an additional out-of-distribution (OOD) class. In this work, we build estimators for both source and target open set label distributions using a source domain in-distribution (ID) classifier and an ID/OOD classifier. With reasonable assumptions on the ID/OOD classifier, the estimators are assembled into a sequence of three stages: 1) an estimate of the source label distribution of the OOD class, 2) an EM algorithm for Maximum Likelihood estimates (MLE) of the target label distribution, and 3) an estimate of the target label distribution of OOD class under relaxed assumptions on the OOD classifier. The sampling errors of estimates in 1) and 3) are quantified with a concentration inequality. The estimation result allows us to correct the ID classifier trained on the source distribution to the target distribution without retraining. Experiments on a variety of open set label shift settings demonstrate the effectiveness of our model. Our code is available at https://github.com/ChangkunYe/OpenSetLabelShift.
NumGrad-Pull: Numerical Gradient Guided Tri-plane Representation for Surface Reconstruction from Point Clouds
Nov 26, 2024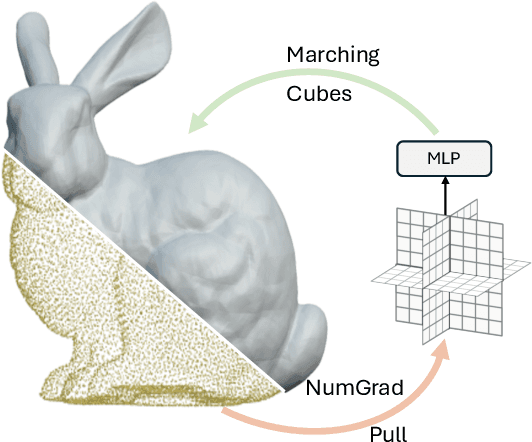
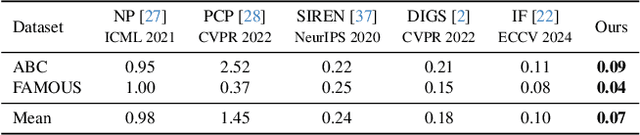
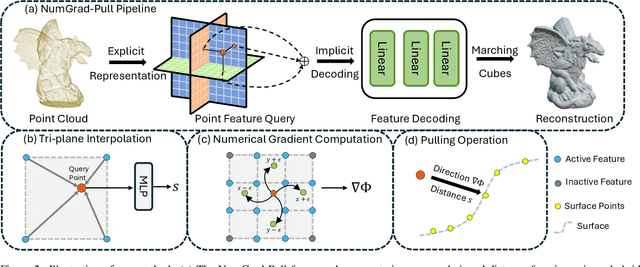
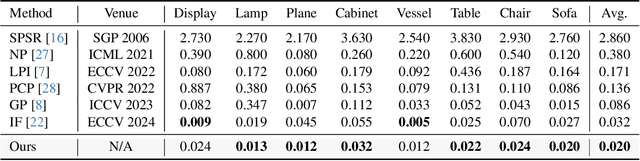
Reconstructing continuous surfaces from unoriented and unordered 3D points is a fundamental challenge in computer vision and graphics. Recent advancements address this problem by training neural signed distance functions to pull 3D location queries to their closest points on a surface, following the predicted signed distances and the analytical gradients computed by the network. In this paper, we introduce NumGrad-Pull, leveraging the representation capability of tri-plane structures to accelerate the learning of signed distance functions and enhance the fidelity of local details in surface reconstruction. To further improve the training stability of grid-based tri-planes, we propose to exploit numerical gradients, replacing conventional analytical computations. Additionally, we present a progressive plane expansion strategy to facilitate faster signed distance function convergence and design a data sampling strategy to mitigate reconstruction artifacts. Our extensive experiments across a variety of benchmarks demonstrate the effectiveness and robustness of our approach. Code is available at https://github.com/CuiRuikai/NumGrad-Pull
Frontiers in Intelligent Colonoscopy
Oct 22, 2024Colonoscopy is currently one of the most sensitive screening methods for colorectal cancer. This study investigates the frontiers of intelligent colonoscopy techniques and their prospective implications for multimodal medical applications. With this goal, we begin by assessing the current data-centric and model-centric landscapes through four tasks for colonoscopic scene perception, including classification, detection, segmentation, and vision-language understanding. This assessment enables us to identify domain-specific challenges and reveals that multimodal research in colonoscopy remains open for further exploration. To embrace the coming multimodal era, we establish three foundational initiatives: a large-scale multimodal instruction tuning dataset ColonINST, a colonoscopy-designed multimodal language model ColonGPT, and a multimodal benchmark. To facilitate ongoing monitoring of this rapidly evolving field, we provide a public website for the latest updates: https://github.com/ai4colonoscopy/IntelliScope.
SDI-Paste: Synthetic Dynamic Instance Copy-Paste for Video Instance Segmentation
Oct 16, 2024



Data augmentation methods such as Copy-Paste have been studied as effective ways to expand training datasets while incurring minimal costs. While such methods have been extensively implemented for image level tasks, we found no scalable implementation of Copy-Paste built specifically for video tasks. In this paper, we leverage the recent growth in video fidelity of generative models to explore effective ways of incorporating synthetically generated objects into existing video datasets to artificially expand object instance pools. We first procure synthetic video sequences featuring objects that morph dynamically with time. Our carefully devised pipeline automatically segments then copy-pastes these dynamic instances across the frames of any target background video sequence. We name our video data augmentation pipeline Synthetic Dynamic Instance Copy-Paste, and test it on the complex task of Video Instance Segmentation which combines detection, segmentation and tracking of object instances across a video sequence. Extensive experiments on the popular Youtube-VIS 2021 dataset using two separate popular networks as baselines achieve strong gains of +2.9 AP (6.5%) and +2.1 AP (4.9%). We make our code and models publicly available.
LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
May 24, 2024
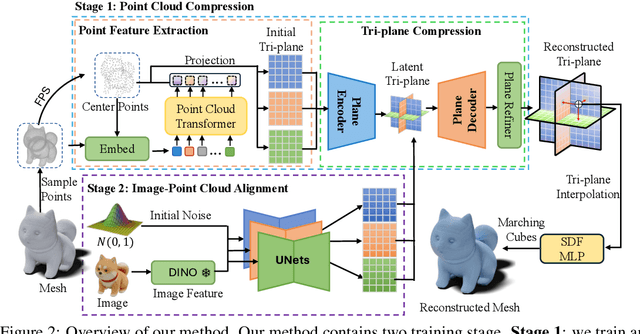

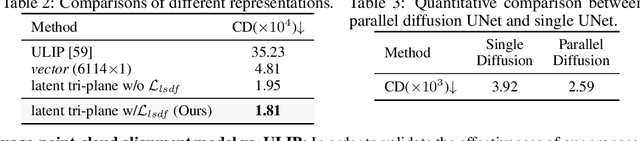
Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.
Learning Gaussian Representation for Eye Fixation Prediction
Mar 21, 2024



Existing eye fixation prediction methods perform the mapping from input images to the corresponding dense fixation maps generated from raw fixation points. However, due to the stochastic nature of human fixation, the generated dense fixation maps may be a less-than-ideal representation of human fixation. To provide a robust fixation model, we introduce Gaussian Representation for eye fixation modeling. Specifically, we propose to model the eye fixation map as a mixture of probability distributions, namely a Gaussian Mixture Model. In this new representation, we use several Gaussian distribution components as an alternative to the provided fixation map, which makes the model more robust to the randomness of fixation. Meanwhile, we design our framework upon some lightweight backbones to achieve real-time fixation prediction. Experimental results on three public fixation prediction datasets (SALICON, MIT1003, TORONTO) demonstrate that our method is fast and effective.