 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGESR: A Genetic Programming-Based Symbolic Regression Method with Gene Editing
May 11, 2026Mathematical formulas serve as a language through which humans communicate with nature. Discovering mathematical laws from scientific data to describe natural phenomena has been a long-standing pursuit of humanity for centuries. In the field of artificial intelligence, this challenge is known as the symbolic regression problem. Among existing symbolic regression approaches, Genetic Programming (GP) based on evolutionary algorithms remains one of the most classical and widely adopted methods. GP simulates the evolutionary process across generations through genetic mutation and crossover. However, mutations and crossovers in GP are entirely random. While this randomness effectively mimics natural evolution, it inevitably produces both beneficial and detrimental variations. If there existed a metaphorical `God` capable of foreseeing which genetic mutations or crossovers would yield superior outcomes and performing targeted gene editing accordingly, the efficiency of evolution could be substantially improved. Motivated by this idea, we propose in this paper a symbolic regression approach based on gene editing, termed GESR. In GESR, we trained two "hands of God" (two BERT models). Among them, the first leverages the BERT's masked language modeling capability to guide the mutation of genes (expression symbols). The other BERT model guides the crossover of individual genes by predicting the crossover point. Experimental results demonstrate that GESR significantly improves computational efficiency compared with traditional GP algorithms and achieves strong overall performance across multiple symbolic regression tasks.
F\textsuperscript{2}LP-AP: Fast \& Flexible Label Propagation with Adaptive Propagation Kernel
Apr 22, 2026Semi-supervised node classification is a foundational task in graph machine learning, yet state-of-the-art Graph Neural Networks (GNNs) are hindered by significant computational overhead and reliance on strong homophily assumptions. Traditional GNNs require expensive iterative training and multi-layer message passing, while existing training-free methods, such as Label Propagation, lack adaptability to heterophilo\-us graph structures. This paper presents \textbf{F$^2$LP-AP} (Fast and Flexible Label Propagation with Adaptive Propagation Kernel), a training-free, computationally efficient framework that adapts to local graph topology. Our method constructs robust class prototypes via the geometric median and dynamically adjusts propagation parameters based on the Local Clustering Coefficient (LCC), enabling effective modeling of both homophilous and heterophilous graphs without gradient-based training. Extensive experiments across diverse benchmark datasets demonstrate that \textbf{F$^2$LP-AP} achieves competitive or superior accuracy compared to trained GNNs, while significantly outperforming existing baselines in computational efficiency.
A Loss Landscape Visualization Framework for Interpreting Reinforcement Learning: An ADHDP Case Study
Mar 15, 2026Reinforcement learning algorithms have been widely used in dynamic and control systems. However, interpreting their internal learning behavior remains a challenge. In the authors' previous work, a critic match loss landscape visualization method was proposed to study critic training. This study extends that method into a framework which provides a multi-perspective view of the learning dynamics, clarifying how value estimation, policy optimization, and temporal-difference (TD) signals interact during training. The proposed framework includes four complementary components; a three-dimensional reconstruction of the critic match loss surface that shows how TD targets shape the optimization geometry; an actor loss landscape under a frozen critic that reveals how the policy exploits that geometry; a trajectory combining time, Bellman error, and policy weights that indicates how updates move across the surface; and a state-TD map that identifies the state regions that drive those updates. The Action-Dependent Heuristic Dynamic Programming (ADHDP) algorithm for spacecraft attitude control is used as a case study. The framework is applied to compare several ADHDP variants and shows how training stabilizers and target updates change the optimization landscape and affect learning stability. Therefore, the proposed framework provides a systematic and interpretable tool for analyzing reinforcement learning behavior across algorithmic designs.
Visualizing Critic Match Loss Landscapes for Interpretation of Online Reinforcement Learning Control Algorithms
Mar 15, 2026Reinforcement learning has proven its power on various occasions. However, its performance is not always guaranteed when system dynamics change. Instead, it largely relies on users' empirical experience. For reinforcement learning algorithms with an actor-critic structure, the critic neural network reflects the approximation and optimization process in the RL algorithm. Analyzing the performance of the critic neural network helps to understand the mechanism of the algorithm. To support systematic interpretation of such algorithms in dynamic control problems, this work proposes a critic match loss landscape visualization method for online reinforcement learning. The method constructs a loss landscape by projecting recorded critic parameter trajectories onto a low-dimensional linear subspace. The critic match loss is evaluated over the projected parameter grid using fixed reference state samples and temporal-difference targets. This yields a three-dimensional loss surface together with a two-dimensional optimization path that characterizes critic learning behavior. To extend analysis beyond visual inspection, quantitative landscape indices and a normalized system performance index are introduced, enabling structured comparison across different training outcomes. The approach is demonstrated using the Action-Dependent Heuristic Dynamic Programming algorithm on cart-pole and spacecraft attitude control tasks. Comparative analyses across projection methods and training stages reveal distinct landscape characteristics associated with stable convergence and unstable learning. The proposed framework enables both qualitative and quantitative interpretation of critic optimization behavior in online reinforcement learning.
Adapting Critic Match Loss Landscape Visualization to Off-policy Reinforcement Learning
Mar 15, 2026This work extends an established critic match loss landscape visualization method from online to off-policy reinforcement learning (RL), aiming to reveal the optimization geometry behind critic learning. Off-policy RL differs from stepwise online actor-critic learning in its replay-based data flow and target computation. Based on these two structural differences, the critic match loss landscape visualization method is adapted to the Soft Actor-Critic (SAC) algorithm by aligning the loss evaluation with its batch-based data flow and target computation, using a fixed replay batch and precomputed critic targets from the selected policy. Critic parameters recorded during training are projected onto a principal component plane, where the critic match loss is evaluated to form a 3-D landscape with an overlaid 2-D optimization path. Applied to a spacecraft attitude control problem, the resulting landscapes are analyzed both qualitatively and quantitatively using sharpness, basin area, and local anisotropy metrics, together with temporal landscape snapshots. Comparisons between convergent SAC, divergent SAC, and divergent Action-Dependent Heuristic Dynamic Programming (ADHDP) cases reveal distinct geometric patterns and optimization behaviors under different algorithmic structures. The results demonstrate that the adapted critic match loss visualization framework serves as a geometric diagnostic tool for analyzing critic optimization dynamics in replay-based off-policy RL-based control problems.
Adaptive Visual Autoregressive Acceleration via Dual-Linkage Entropy Analysis
Feb 01, 2026Visual AutoRegressive modeling (VAR) suffers from substantial computational cost due to the massive token count involved. Failing to account for the continuous evolution of modeling dynamics, existing VAR token reduction methods face three key limitations: heuristic stage partition, non-adaptive schedules, and limited acceleration scope, thereby leaving significant acceleration potential untapped. Since entropy variation intrinsically reflects the transition of predictive uncertainty, it offers a principled measure to capture modeling dynamics evolution. Therefore, we propose NOVA, a training-free token reduction acceleration framework for VAR models via entropy analysis. NOVA adaptively determines the acceleration activation scale during inference by online identifying the inflection point of scale entropy growth. Through scale-linkage and layer-linkage ratio adjustment, NOVA dynamically computes distinct token reduction ratios for each scale and layer, pruning low-entropy tokens while reusing the cache derived from the residuals at the prior scale to accelerate inference and maintain generation quality. Extensive experiments and analyses validate NOVA as a simple yet effective training-free acceleration framework.
A New Benchmark for Online Learning with Budget-Balancing Constraints
Mar 19, 2025The adversarial Bandit with Knapsack problem is a multi-armed bandits problem with budget constraints and adversarial rewards and costs. In each round, a learner selects an action to take and observes the reward and cost of the selected action. The goal is to maximize the sum of rewards while satisfying the budget constraint. The classical benchmark to compare against is the best fixed distribution over actions that satisfies the budget constraint in expectation. Unlike its stochastic counterpart, where rewards and costs are drawn from some fixed distribution (Badanidiyuru et al., 2018), the adversarial BwK problem does not admit a no-regret algorithm for every problem instance due to the "spend-or-save" dilemma (Immorlica et al., 2022). A key problem left open by existing works is whether there exists a weaker but still meaningful benchmark to compare against such that no-regret learning is still possible. In this work, we present a new benchmark to compare against, motivated both by real-world applications such as autobidding and by its underlying mathematical structure. The benchmark is based on the Earth Mover's Distance (EMD), and we show that sublinear regret is attainable against any strategy whose spending pattern is within EMD $o(T^2)$ of any sub-pacing spending pattern. As a special case, we obtain results against the "pacing over windows" benchmark, where we partition time into disjoint windows of size $w$ and allow the benchmark strategies to choose a different distribution over actions for each window while satisfying a pacing budget constraint. Against this benchmark, our algorithm obtains a regret bound of $\tilde{O}(T/\sqrt{w}+\sqrt{wT})$. We also show a matching lower bound, proving the optimality of our algorithm in this important special case. In addition, we provide further evidence of the necessity of the EMD condition for obtaining a sublinear regret.
Frontiers in Intelligent Colonoscopy
Oct 22, 2024Colonoscopy is currently one of the most sensitive screening methods for colorectal cancer. This study investigates the frontiers of intelligent colonoscopy techniques and their prospective implications for multimodal medical applications. With this goal, we begin by assessing the current data-centric and model-centric landscapes through four tasks for colonoscopic scene perception, including classification, detection, segmentation, and vision-language understanding. This assessment enables us to identify domain-specific challenges and reveals that multimodal research in colonoscopy remains open for further exploration. To embrace the coming multimodal era, we establish three foundational initiatives: a large-scale multimodal instruction tuning dataset ColonINST, a colonoscopy-designed multimodal language model ColonGPT, and a multimodal benchmark. To facilitate ongoing monitoring of this rapidly evolving field, we provide a public website for the latest updates: https://github.com/ai4colonoscopy/IntelliScope.
Operator Feature Neural Network for Symbolic Regression
Aug 14, 2024Symbolic regression is a task aimed at identifying patterns in data and representing them through mathematical expressions, generally involving skeleton prediction and constant optimization. Many methods have achieved some success, however they treat variables and symbols merely as characters of natural language without considering their mathematical essence. This paper introduces the operator feature neural network (OF-Net) which employs operator representation for expressions and proposes an implicit feature encoding method for the intrinsic mathematical operational logic of operators. By substituting operator features for numeric loss, we can predict the combination of operators of target expressions. We evaluate the model on public datasets, and the results demonstrate that the model achieves superior recovery rates and high $R^2$ scores. With the discussion of the results, we analyze the merit and demerit of OF-Net and propose optimizing schemes.
DN-CL: Deep Symbolic Regression against Noise via Contrastive Learning
Jun 21, 2024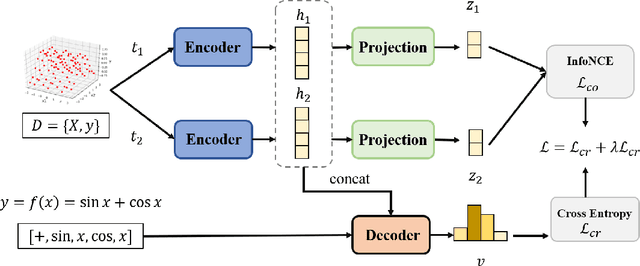

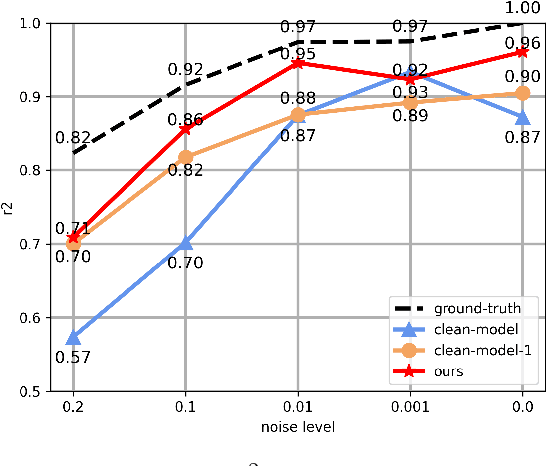
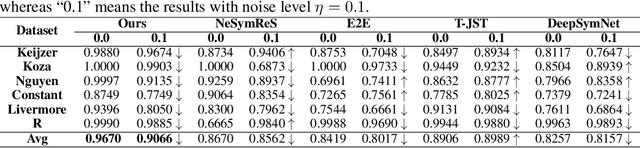
Noise ubiquitously exists in signals due to numerous factors including physical, electronic, and environmental effects. Traditional methods of symbolic regression, such as genetic programming or deep learning models, aim to find the most fitting expressions for these signals. However, these methods often overlook the noise present in real-world data, leading to reduced fitting accuracy. To tackle this issue, we propose \textit{\textbf{D}eep Symbolic Regression against \textbf{N}oise via \textbf{C}ontrastive \textbf{L}earning (DN-CL)}. DN-CL employs two parameter-sharing encoders to embed data points from various data transformations into feature shields against noise. This model treats noisy data and clean data as different views of the ground-truth mathematical expressions. Distances between these features are minimized, utilizing contrastive learning to distinguish between 'positive' noise-corrected pairs and 'negative' contrasting pairs. Our experiments indicate that DN-CL demonstrates superior performance in handling both noisy and clean data, presenting a promising method of symbolic regression.